


Background & Motivation
大规模近似近邻搜索(ANNS)场景下的数据处理广泛应用于推荐系统,搜索引擎
这种应用的需求:搜索结果要求满足一定的精度要求,且时延低
应用优化的挑战在于:待搜索的数据集庞大,同时满足精度和时延要求下加速应用性能。

(图片源于:intel关于NeurlPS ANNS挑战赛)
一般的ANNS算法可以描述为Algorithm 1的样子,

其中查询对象与其他对象的相似度计算采用基于距离的相似度进行,具体计算可以用L2,也可以用Angular距离。
考虑到ANNS要处理大规模数据,目前的研究主要可以分为两类:基于压缩的方法(下图中(a))和基于层次化的方法(下图中(b))。
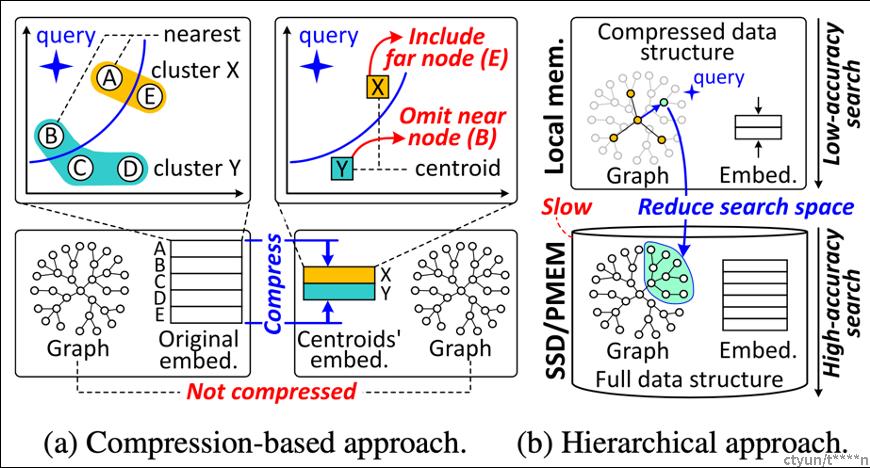
基于压缩的方法会损失精度,因为他通过将众多邻近的对象描述为独立对象进行“概括”,这样在实际的搜索中会丢失一些候选对象,所以精度较差。
基于层次化的方法会比较慢,这主要是因为他把数据集进行压缩,放置于本地内存,然后把数据全集放在SSD或者持久化内存中,这种介质的数据访问要远比本地内存要大。所以查询性能较慢。
也就是说,现存的两类方法在大规模数据集下无法同时满足精度与查询性能(时延)的要求。
为此,作者提出采用CXL内存池进行ANNS的应用性能优化。
Idea
作者搭建了如下图所示的CXL内存池架构,不过显而易见的是,仅仅这么使用内存,免不了CXL内存访问带来的性能劣化,毕竟这种内存访问时延要比本地内存访问大很多,那么如何加速呢?
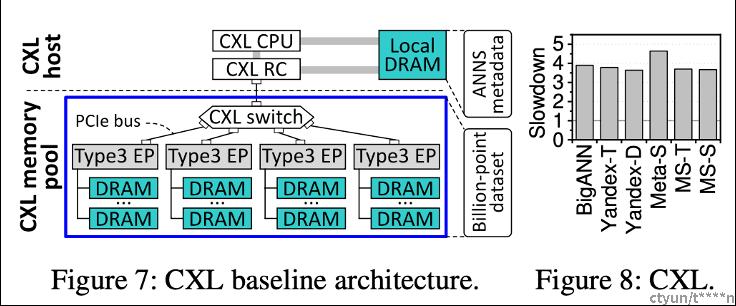
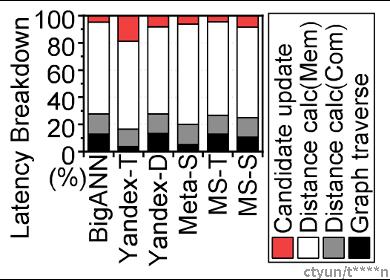
作者对ANNS的业务进行了breakdown,如下图所示,可以发现距离计算部分的业务最耗时,基本上占据了80%,所以根据阿姆达尔定律,我们可以尝试在这里入手,这样加速最明显。
作者主要围绕四个方面进行加速:
(1)近存计算
(2)冷热分级
(3)访问预测
(4)精细化任务调度
下面我们一个一个展开。
Observations & Design
冷热分级就是可以把ANNS在邻居搜索过程中频繁访问的节点放到本地内存中来,这样可以极大地加速。
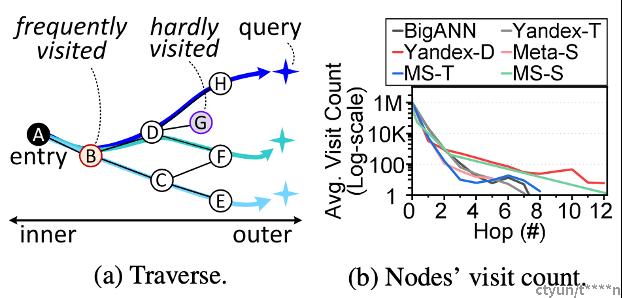
近存计算就是由CXL EP就近对CXL内存中的数据进行距离计算,把计算结果送到本地内存中,这样减少数据传送。

访问预测就是预测搜索过程中的节点访问,然后对该节点的数据进行预取,形成overlap,减少数据等待开销。

精细化任务调度就是分解业务中的update操作,其实就是类似把原来业务上的大“原子”操作,拆分成小的“原子”操作,也有点CPU乱序的感觉,不过这里的性能提升不大。
这四个技巧中,最大的性能提升来自于近存计算。
Implementation
下图是CXL-ANNS的软硬协同架构图。

挂了4个EP(每个含4个memory controller 挂一个dimm channel 256GB),DSA由CXL engine映射到Host 空间的寄存器获得command,对memory controller发送内存请求进行数据获取,然后进行计算。根据entry-point计算单源最短路径,然后按路径排序,优先放置节点在local DRAM,放满后放CXL DRAM。考虑到邻居数量是变长的,其对CXL内存采用buddy-like 分配器,Data vector采用stack-like分配器,通过跨arena 轮转分配,平衡EP的工作负载。最后,最终的协同是各个ep从Host-CPU侧的local dram获取搜索过程中的邻居节点信息,然后通过PE sharding并行计算取得distance送至local dram,这是最关键的性能提升部分。相当于一个map-reduce过程。
Evaluation
下面展示CXL-ANNS的性能提速效果,对比不同的数据集在相同recall精度要求下的QoS。

其中,
Comp代表压缩型ANNS的设计,其以中心向量代表cluster;
Hr-D代表DiskANN设计;
Hr-H代表混合内存的层次化设计:HM-ANN;
Orrl代表采用全部DRAM进行数据集存储,然后进行未优化的ANNS搜索;
Base代表采用CXL pool进行数据集存储,然后进行未优化的ANNS搜索,即只有CXL CPU进行计算;
EPAx代表开启DSA加速的方案;
Cache代表开启预取与relationship-aware放置的方案;
CXLA代表文章提出的包含所有优化特性的方案。
可以看出,不同数据集下以及不同query的配置下(选不同的K进行k-anns),CXLA可以同时保障精确度和性能。
通过breakdown,如下图,也可以看出CXLA可大幅缩小查询时延,其主要性能提升来自于Distance Calc(近存计算)

