


分片机制
1. 数据切分
首先,基于分片切分后的数据块称为 chunk,一个分片后的集合会包含多个 chunk,每个 chunk 位于哪个分片(Shard) 则记录在 Config Server(配置服务器)上。Mongos 在操作分片集合时,会自动根据分片键找到对应的 chunk,并向该 chunk 所在的分片发起操作请求。数据是根据分片策略来进行切分的,而分片策略则由 分片键(ShardKey)+分片算法(ShardStrategy)组成。MongoDB 支持两种分片算法:
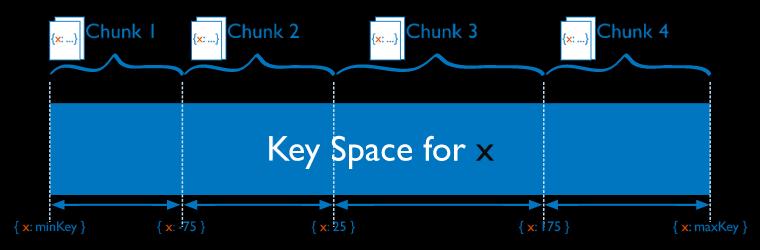
- 范围分片:将整个取值范围划分为多个chunk,每个chunk(默认配置为64MB)包含其中一小段的数据。如Chunk1包含x的取值在[minKey, -75)的所有文档,而Chunk2包含x取值在[-75, 25)之间的所有文档。范围分片能很好的满足范围查询的需求,比如想查询x的值在[-30, 10]之间的所有文档,这时 Mongos 直接能将请求路由到 Chunk2,就能查询出所有符合条件的文档。 范围分片的缺点在于,如果 ShardKey 有明显递增(或者递减)趋势,则新插入的文档多会分布到同一个chunk,无法扩展写的能力。
- 哈希分片:Hash分片是根据用户的 ShardKey 先计算出hash值(64bit整型),再根据hash值按照范围分片的策略将文档分布到不同的 chunk。由于 hash值的计算是随机的,因此 Hash 分片具有很好的离散性,可以将数据随机分发到不同的 chunk 上。 Hash 分片可以充分的扩展写能力,弥补了范围分片的不足,但不能高效的服务范围查询,所有的范围查询要查询多个 chunk 才能找出满足条件的文档。

2. 保证均衡
数据是分布在不同的 chunk上的,而 chunk 则会分配到不同的分片上,那么如何保证分片上的 数据(chunk) 是均衡的呢?在真实的场景中,会存在下面两种情况:
-
A. 全预分配,chunk 的数量和 shard 都是预先定义好的,比如 10个shard,存储1000个chunk,那么每个shard 分别拥有100个chunk。
此时集群已经是均衡的状态。 -
B. 非预分配,这种情况则比较复杂,一般当一个 chunk 太大时会产生分裂(split),不断分裂的结果会导致不均衡;或者动态扩容增加分片时,也会出现不均衡的状态。 这种不均衡的状态由集群均衡器进行检测,一旦发现了不均衡则执行 chunk数据的搬迁达到均衡。
MongoDB 的数据均衡器运行于 Primary Config Server(配置服务器的主节点)上,而该节点也同时会控制 Chunk 数据的搬迁流程。对于数据的不均衡是根据两个分片上的 Chunk 个数差异来判定的,阈值对应表如下:
| Chunk的数量 | 迁移阈值 |
|---|---|
| Fewer than 20 | 2 |
| 20-79 | 4 |
| 80 and greater | 8 |
MongoDB 的数据迁移对集群性能存在一定影响,这点无法避免,目前的规避手段只能是将均衡窗口对齐到业务闲时段。
副本集
副本集可以作为 Shard Cluster 中的一个Shard(片)之外,对于规模较小的业务来说,也可以使用一个单副本集的方式进行部署。MongoDB 的副本集采取了一主多从的结构,即一个Primary Node + N* Secondary Node的方式,数据从主节点写入,并复制到多个备节点。
利用副本集,可以实现:
- 数据库高可用,主节点宕机后,由备节点自动选举成为新的主节点;
- 读写分离,读请求可以分流到备节点,减轻主节点的单点压力。
但读写分离只能增加集群"读"的能力,对于写负载非常高的情况却无能为力。对此需求,使用分片集群并增加分片,或者提升数据库节点的磁盘IO、CPU能力可以取得一定效果。
选举
MongoDB 副本集通过 Raft 算法来完成主节点的选举,这个环节在初始化的时候会自动完成,initiate 命令用于实现副本集的初始化,在选举完成后,通过 isMaster()命令就可以看到选举的结果。受 Raft算法的影响,主节点的选举需要满足"大多数"原则,因此,为了避免出现平票的情况,副本集的部署一般采用是基数个节点。
心跳
在高可用的实现机制中,心跳(heartbeat)是非常关键的,判断一个节点是否宕机就取决于这个节点的心跳是否还是正常的。副本集中的每个节点上都会定时向其他节点发送心跳,以此来感知其他节点的变化,比如是否失效、或者角色发生了变化。利用心跳,MongoDB 副本集实现了自动故障转移的功能。
默认情况下,节点会每2秒向其他节点发出心跳,这其中包括了主节点。 如果备节点在10秒内没有收到主节点的响应就会主动发起选举。此时新一轮选举开始,新的主节点会产生并接管原来主节点的业务。 整个过程对于上层是透明的,应用并不需要感知,因为 Mongos 会自动发现这些变化。如果应用仅仅使用了单个副本集,那么就会由 Driver 层来自动完成处理。
复制
主节点和备节点的数据是通过日志(oplog)复制来实现的,这很类似于 mysql 的 binlog。在每一个副本集的节点中,都会存在一个名local.oplog.rs的特殊集合。 当 Primary 上的写操作完成后,会向该集合中写入一条oplog,而 Secondary 则持续从 Primary 拉取新的 oplog 并在本地进行回放以达到同步的目的。
