


基本概念:
- broadcast:将主进程的相同数据分发给组里的其他进程
- scatter:将主进程的一小部分数据分发给组里的其他进程
- gather:收集其他进程发来的数据
- reduce:收集其他进程发来的数据并执行某种操作(比如sum)
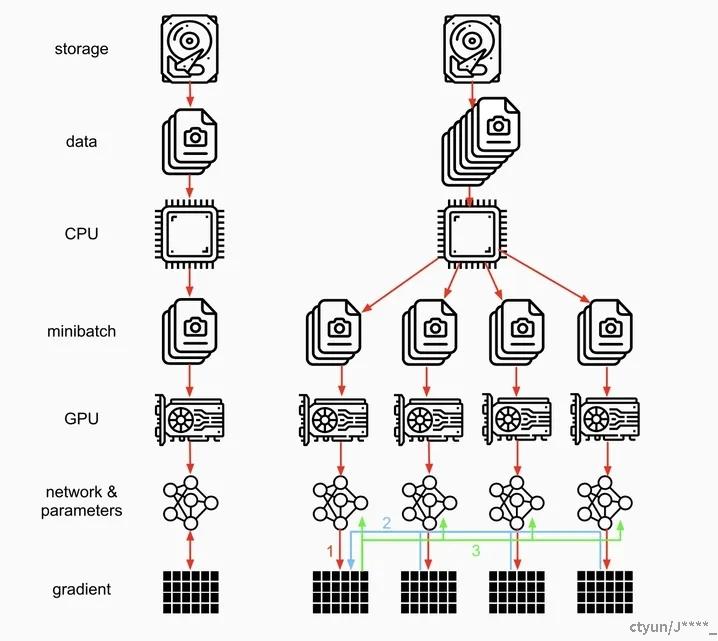
网络在前向传播时会将 model 从主卡 (默认是逻辑 0 卡) broadcast 到所有 device 上,输入数据会在 batch 这个维度被分组后 scatter 到不同的 device 上进行前向计算 ,计算完毕后网络的输出被 gather 到主卡上,loss 随后在主卡上被计算出来 (这也是为什么主卡负载更大的原因,loss 每次都会在主卡上计算,这就造成主卡负载远大于其他显卡)。在反向传播时,loss 会被 scatter 到每个 device 上,每个卡各自进行反向传播计算梯度,然后梯度会被 reduce 到主卡上 (i.e. 求得各个 device 的梯度之和,然后按照 batch_size 大小求得梯度均值),再用反向传播在主卡上更新模型参数,最后将更新后的模型参数 broadcast 到其余 GPU 中进行下一轮的前向传播,以此来实现并行
缺陷:
- 只能在一个机器上实现,所以叫单机多卡(一个机器,多个cuda卡),不能使用 Apex 进行混合精度训练。同时它基于多线程的方式,确实方便了信息的交换,但受困于 GIL (Python 全局解释器锁),会带来性能开销 (GIL 的存在使得一个 Python 进程只能利用一个 CPU 核心,不适合用于计算密集型的任务)
- 存在效率问题,主卡性能和通信开销容易成为瓶颈,GPU 利用率通常很低。数据集需要先拷贝到主进程,然后再 split 到每个设备上;权重参数只在主卡上更新,需要每次迭代前向所有设备做一次同步;每次迭代的网络输出需要 gather 到主卡上
- 不支持模型并行
通信开销:假设单个GPU有K张卡,模型参数量为P,则通信开销为2P(k-1)
