


目标是成为大模型微调大师
一、背景介绍
2022年12月,ChatGPT横空出世,OpenAI正式宣告了大模型时代的到来。而随着众多底座大模型的开源,大模型技术开始逐渐走向大众,不管是企业还是个人,都可以通过大模型来满足业务需求或者解决特定问题,其中,常见的基座大模型,即通用大模型大多以Transformer模型为基础架构,并且遵循尺度定律(Scaling Law),随着模型参数量大小、训练数据量大小、计算浮点数精度大小的增加,模型的性能也会显著提升,即大模型的能力与前述三者之间存在的渐进关系,由此,常见的基座大模型的参数量一般都达到了十亿级参数,甚至达到了千亿级参数。
随着多个研究机构开源其基座大模型,部分研究者通过使用特定领域或任务的训练数据对大模型进行训练微调,可以使得大模型更加适配具体的应用场景和任务,因此,针对大模型在特定领域的微调(Fine-Tuning)技术也得到了广泛关注,微调的目的是使得通用的底座大模型转换为具体的专用大模型,并消除底座大模型的通用知识与具体业务需求之间的差距,其中,微调技术分为全参数微调和轻量化微调,全参数微调指的是对模型的所有参数进行训练微调,而轻量化微调,即参数高效微调,指的是在模型训练微调过程中,最小化引入的额外参数或所需要的计算资源数量,全参数微调是对整个模型参数进行调整,其计算成本随着模型参数量大小和训练数据量大小的增加而增加,在实际应用中,从头开始训练微调底座大模型的全量参数不太现实,庞大的计算成本和密集的计算资源对系统来说是巨大的挑战,因此,研究者以及从业人员更偏向于使用轻量化微调的方法对底座大模型进行训练微调,以匹配业务的时效性。
二、什么是轻量化微调(PEFT:Parameter-Efficient Fine-Tuning)?
轻量化微调技术是为了解决使用大语言模型对特定任务或场景的数据进行训练微调时所面临的巨大计算量代价问题以及兼顾大模型的丰富通用知识,通过最小化引入的额外参数或所需要的计算资源数量,实现通用大模型到专用大模型的转变。
轻量化微调技术具体主要分为以下五种方法,一是附加式微调(Additive Fine-tuning),该方法主要通过引入额外的可训练参数模块以进行特定任务上的训练微调,包括基于适配器的微调(Adapter-based Fine-tuning)、基于软提示的微调(Soft Prompt-based Fine-tuning)以及其他引入附加模型参数的微调方法;二是局部式微调(Partial Fine-tuning),该方法的主要通过选择大语言模型中对下游任务更加重要的部分预训练参数进行训练微调而舍弃不重要的参数,达到减少微调参数的目的,包括偏好更新(Bias Update)、预训练权重掩蔽(Pretrained Weight Masking)、Delta权重掩蔽(Delta Weight Masking);三是重参数化式微调(Reparameterized Fine-tuning),该方法通过对预训练权重中的高维矩阵进行低秩变换以减少可训练参数量,包括低秩压缩和LoRA(Low-Rank Adaptatio)变体;四是混合式微调(Hybrid Fine-tuning),这种方法主要结合了多种轻量化微调技术,例如适配器(Adapter)、前缀微调(Prefix Tuning)、LoRA,整合多种微调技术的优点的同时,并缓解各自的缺点,以达到微调的最优;五是统一式微调(Unified Fine-tuning),统一式微调表示一种统一的微调框架,通过将多种微调方法整合成一个综合的流水线框架,来模型微调过程中的一致性和高效性。
三、常用的轻量化微调方法有哪些?
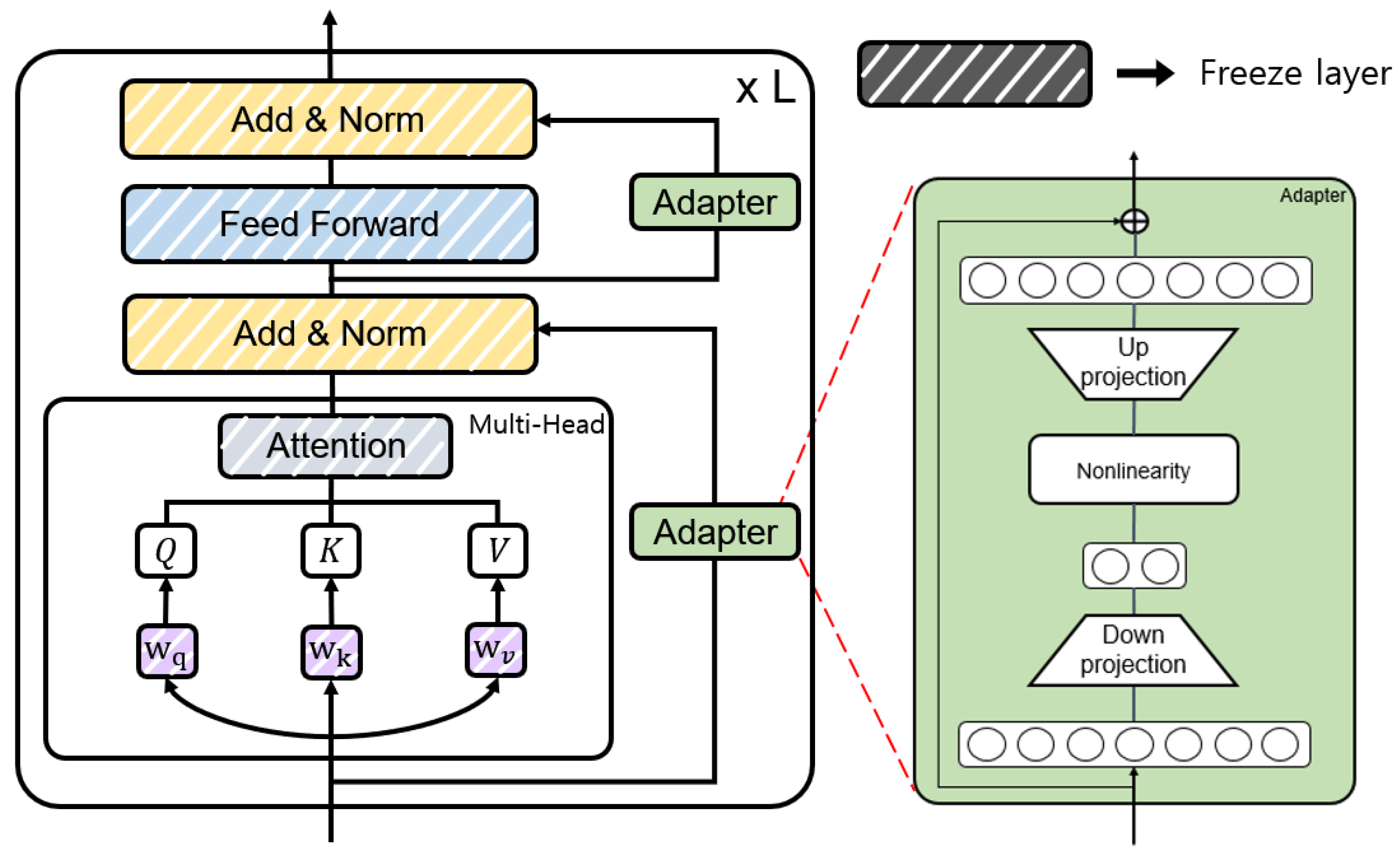
1、基于适配器的微调(Adapter-based Fine-tuning)。
基于适配器的微调是一种针对预训练语言模型(Pretrained Language Models,PLMs)的训练微调方法。这种方法通过在预训练模型中添加轻量级的适配器模块(Adapter Modules),并在学习下游任务时仅更新这些适配器模块的参数。与传统的微调(Fine-Tuning)相比,适配器微调仅为每个新任务添加少量可训练参数,从而实现了预训练语言模型的参数共享。适配器微调的主要优势在于其训练微调上的参数效率,因为与传统的微调相比,它不需要为每个任务复制和更新整个模型的权重,而是只更新适配器模块的参数,同时保持原始预训练模型的权重不变。这种方法在低资源和跨语言任务中表现出更好的性能,并且对过拟合更具有鲁棒性,对学习率的变化也不那么敏感。此外,适配器微调由于其结构特点,能够在一定程度上缓解灾难性遗忘问题,因为它能够更好地保留预训练模型的原始知识。很多研究者通过实验验证了,适配器微调在特定设置下,尤其是当任务特定性更强或训练样本较少时,能够取得与模型全参数训练微调相当的性能。
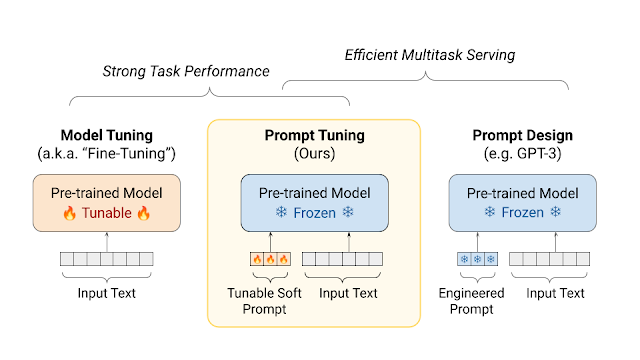
2、基于软提示的微调(Soft Prompt-based Fine-tuning)。
基于软提示的微调是一种针对大规模预训练语言模型的参数高效调整方法。这种方法通过在模型输入中添加可学习的连续向量(称为软提示或soft prompts),而不是对整个模型参数进行训练微调,来适应特定的下游任务。其中,软提示是一些嵌入向量,它们在模型的输入序列中作为提示出现,用于引导模型的输出和行为。与传统的全参数微调相比,软提示微调只更新一小部分参数,即那些与软提示相关的参数,而保持预训练模型的其余部分参数不变。这种方法的优势在于它能够显著减少所需的计算资源和存储空间,同时在很多情况下能够与全参数微调相媲美的性能。基于软提示的微调的关键点包括:1)参数效率:只调整模型输入中的一小部分连续向量,而不是整个模型的参数;2)灵活性:通过调整软提示,可以灵活地引导模型的行为,以适应不同的任务;3)性能:尽管只更新了少量参数,但在许多任务上能够实现与全参数微调相似的性能;4)多任务学习:软提示可以针对多任务学习场景进行优化,以提高模型在多个任务上的泛化能力。在实际应用中,软提示微调可以用于各种自然语言处理任务,如文本分类、情感分析、问答系统等。此外,这种方法也适用于低资源场景,即在训练数据较少的情况下,仍然能够有效地调整模型以适应新任务。
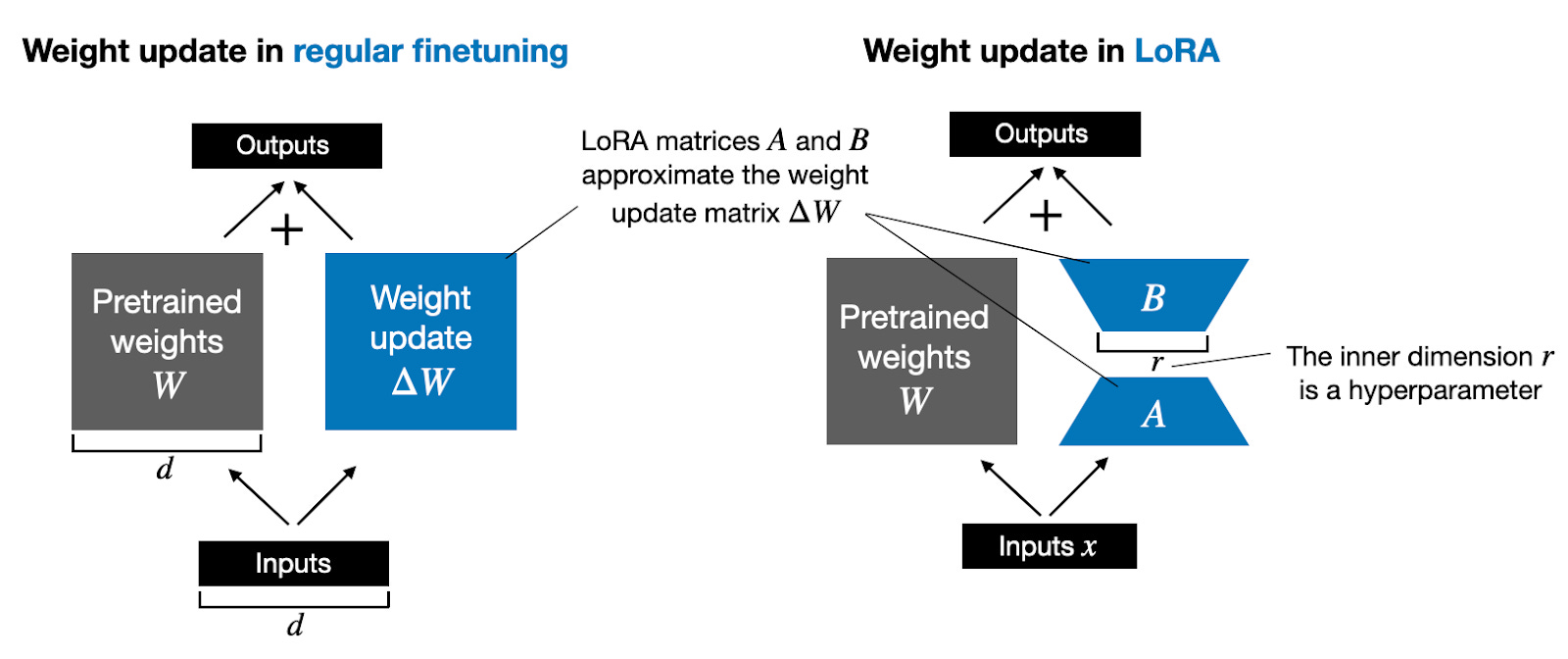
3、低秩适配(Low-rank Adaptation)。
低秩适配,即LoRA,是一种针对预训练语言模型的参数高效微调方法。这种方法的核心思想是,在微调过程中,不是更新模型的所有参数,而是通过引入低秩矩阵来更新模型的权重矩阵,从而减少可训练参数的数量。具体来说,LoRA 通过以下步骤实现:1)选择性更新:选择模型中的部分权重矩阵进行更新,例如Transformer模型中的自注意力机制(Self-Attention)或前馈网络(Feed-Forward Networks)的权重。2)低秩分解:对于选定的权重矩阵,LoRA 不直接更新整个矩阵,而是通过低秩分解(如奇异值分解)引入一组低秩矩阵。这些低秩矩阵与原权重矩阵相乘,以实现权重的更新。3)参数共享:在某些情况下,LoRA 还可以通过参数共享进一步减少参数数量,即多个权重矩阵共享相同的低秩矩阵。LoRA 的优势在于:1)参数效率:由于只更新了模型中一小部分权重,LoRA 大大减少了可训练参数的数量,降低了模型对计算资源的需求;2)保持预训练信息:通过只更新部分权重,LoRA 能够更好地保留预训练模型在大规模语料库中学习到的知识;3)灵活性:LoRA 可以灵活地应用于不同的模型架构和不同的任务,易于集成到现有的微调流程中;4)性能:尽管参数数量减少,LoRA 通常能够在多种任务上实现与全参数微调相似或接近的性能。LoRA 适用于大规模预训练模型的微调,特别是在计算资源有限或需要快速部署模型的场景中。通过减少参数数量,LoRA有助于提高模型的可扩展性和实用性。
四、Talk is cheap,show me code — 大模型微调实战。
1、大模型微调入门
本文将简单地介绍如何基于huggingface transformers库、PEFT库等框架,使用LoRA微调技术对Qwen-7B-Chat模型进行训练微调。
2、环境要求和配置
- 系统环境:Ubuntu20.04
- 基础环境:python3.9、torch2.0.1、cuda11.7
- GPU:NVIDIA V100 32G * 1
3、依赖库安装
pip install transformers==4.35.2
pip install peft==0.4.0
pip install datasets==2.10.1
pip install accelerate==0.20.3
pip install tiktoken
pip install transformers_stream_generator
- 数据形式:针对大模型的数据层面的微调方法主要通过指令微调方式实现,具体地,就是将输入数据集构建成以下形式:
{
"instrution":"回答以下用户问题,仅输出答案。",
"input":"1+1等于几?",
"output":"2"
}
其中,instruction 是用户指令,告知模型其需要完成的任务;input 是用户输入,是完成用户指令所必须的输入内容;output是模型应该给出的输出。
- 数据集构建:本文将使用ruozhiba数据集对Qwen-7B-Chat模型进行训练微调,该数据集数据来自百度贴吧-弱智吧提供的疑问句,然后调用GPT-4获取答案,并过滤掉明显拒答的回复。然后将数据集中的每一条问答数据构建成以下形式:
{
"instrution":"回答以下用户问题,仅输出答案。",
"input":"只剩一个心脏了还能活吗?",
"output":"能,人本来就只有一个心脏。"
}
最后将所有问答数据整合到一个json文件中得到我们需要的训练数据,格式如下所示:
[
{
"instruction":"回答以下用户问题,仅输出答案。",
"input":"只剩一个心脏了还能活吗?",
"output":"能,人本来就只有一个心脏。"
},
...
{
"instruction":"回答以下用户问题,仅输出答案。",
"input":"为什么没有人能毫发无损的走出理发店?",
"output":"因为理发店是用来剪发的,如果毫发无损,那就说明没有剪发,那么去理发店的目的就没有达到。"
}
]
5、加载分词器和模型
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen-7B-Chat', use_fast=False, trust_remote_code=True)
tokenizer.pad_token_id = tokenizer.eod_id # Qwen中eod_id和pad_token_id是一样的,但需要指定一下
model = AutoModelForCausalLM.from_pretrained('Qwen/Qwen-7B-Chat', trust_remote_code=True, torch_dtype=torch.half, device_map="auto")
6、LoRA和训练配置
- LoRA配置
from peft import LoraConfig
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["c_attn", "c_proj", "w1", "w2"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1# Dropout 比例
)
其中各参数含义表示如下,task_type:模型类型;target_modules:需要训练的模型层的名字,主要就是attention部分的层,不同的模型对应的层的名字不同,可以传入数组,也可以字符串,也可以正则表达式;r:lora的秩,具体可以看Lora原理;lora_alpha:Lora alaph,具体作用参见 Lora 原理。
- 训练器配置
from transformers import TrainingArguments
args = TrainingArguments(
output_dir="./output/Qwen",
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
logging_steps=10,
num_train_epochs=3,
gradient_checkpointing=True,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True
)
其中各参数表示如下,output_dir:模型的输出路径;per_device_train_batch_size:定义每张显卡的batch_size;gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些;logging_steps:多少步,输出一次log;num_train_epochs:训练的轮次;gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads()。
7、开始训练
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train()
8、模型推理
- 最后,加载训练好的模型进行问答。
model = AutoModelForCausalLM.from_pretrained('./output/Qwen', trust_remote_code=True, torch_dtype=torch.half, device_map="auto")
model.eval()
response, history = model.chat(tokenizer, "为什么电梯要从一楼开始建呢 一楼住户也不需要使用?", history=[], system="回答以下用户问题,仅输出答案。")
print(response)
五、总结与展望。
如今的AI时代是大模型主导的时代,很多业务场景都可以用“大模型+”的方式进行提升,而对通用大模型进行训练微调,将通用转为专用是入门大模型的重要手段,其中,轻量化微调技术则显得格外重要,通过轻量化微调技术,可以大幅降低大模型训练微调的成本,并显著提升大模型在特定任务上的性能,该技术终将随着大模型的发展而发扬光大,成为大模型训练微调的“利器”,同时,研究人员对轻量化微调的研究也会一直向前,未来也会有更多的相关研究方向。
针对轻量化微调的研究,目前的主要研究方向包括以下几个方面,1)轻量混合高效微调方法,目前很多研究开始结合多种轻量化微调方法,目的是结合每种轻量化微调的优点以增强模型性能,但受限于多种轻量化微调方法本身的上限,因此越来越多的研究开始专注于如何整合多种轻量化微调方法的同时减少可训练参数;2)LoRA的衍生轻量化微调方法,目前越来越多围绕LoRA诞生的研究都取得了不错的实验效果,例如适配式秩调整、无结构剪枝技术、权重量化、多任务整合等,通过围绕LoRA开展各种相关研究,不断发掘LoRA的潜力;3)开发轻量化微调库,为了使得研究人员或从业者更方便地使用轻量化微调方法,很多研究团队开始开发轻量化微调库,例如PEFT library、AdapterHub等,这些库可以简化大模型微调的流程,并提高大模型微调的效率;4)轻量化微调的可解释性,目前轻量化微调的研究主要还是围绕自然语言处理展开,而通过对轻量化微调的可解释性研究,不仅能够帮助研究人员更好地理解轻量化微调的原理和机制,还能挖掘轻量化微调在其他方向的应用,例如计算机视觉、多模态学习。
六、参考资料。
[1] Xu L, Xie H, Qin S Z J, et al. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment[J]. arXiv preprint arXiv:2312.12148, 2023.
