1. 网络数据收发程序架构
结合源码分析,rte_eth_devices全局变量用于存储每个网卡port相关的信息,以网卡port为单位,以数组形式存储rte_eth_devices[RTE_MAX_ETHPORTS],RTE_MAX_ETHPORTS为数组能存储的最大网卡port数;
rte_eth_devices结构里有一些收发操作相关的信息,如收发函数指针rx_pkt_burst、tx_pkt_burst等,负责当前网卡port的收发具体实现,data指针,指向rte_eth_dev_data结构体,里面有收发队列相关的信息,如rx_queues、tx_queues等,负责网络数据帧的存储,其中rx_queues、tx_queues指向的结构里包含rx_ring、tx_ring和sw_ring,rx_ring、tx_ring为网卡的描述符环形缓冲区,用于DMA,sw_ring为描述符一一对应的真实的网络数据帧存储结构mbuf;
以上这些信息是收发流程用到的最主要的结构,即收发动作和收发数据存储,下面从这些方面进行分析dpdk的网络数据帧的收发流程;

2. 收包流程
根据上述分析,用到的主要程序结构有rx_pkt_burst、rx_queues、rx_ring+sw_ring,以igb驱动为例进行分析;
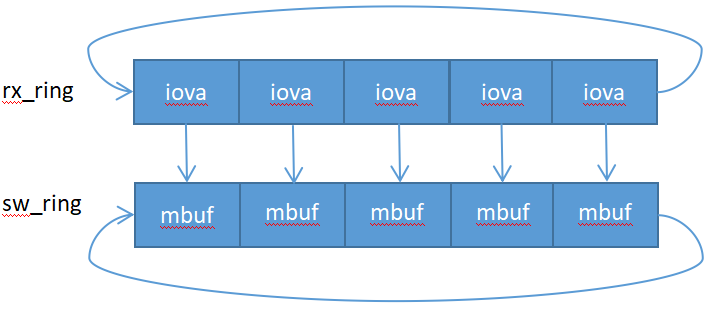
eth_igb_rx_init初始化函数把rx_pkt_burst函数指针初始化,指向eth_igb_recv_pkts函数或者eth_igb_recv_scattered_pkts函数,eth_igb_rx_queue_setup函数创建并初始化rx_queues队列,eth_igb_rx_init初始化函数又调用igb_alloc_rx_queue_mbufs函数为每个rx_queues队列里的sw_ring申请挂接nb_rx_desc个mbuf,为rx_ring初始化为对应的mbuf的iova指针(DMA指针),现在收包函数和网络数据帧存储结构都完成了初始化,存储结构如下图所示:
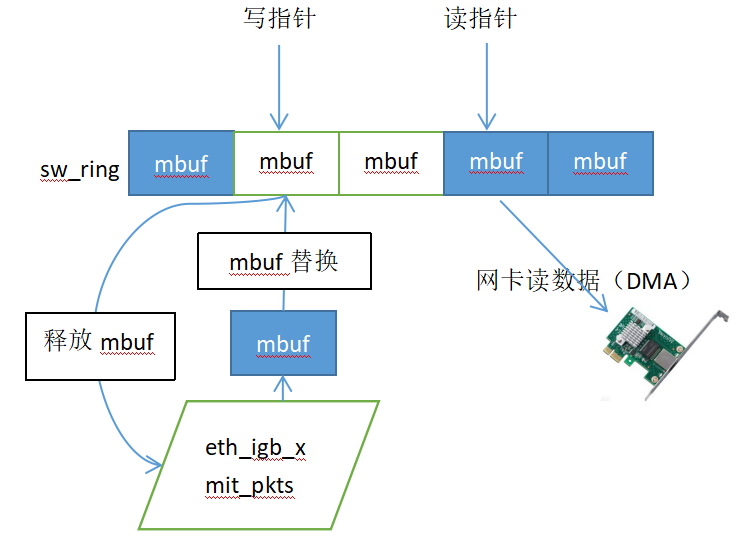
以eth_igb_recv_pkts函数为例进行说明,这个函数主要是用于巨型mbuf处理,即网络数据帧不超过单个mbuf存储空间,所以这种情况下mbuf没有级联;
首先网卡通过读取寄存器(对应rx_ring)获取mbuf的DMA指针,然后向mbuf(对应sw_ring)存放网络数据帧,设置DD标志为1,表示写数据完成,eth_igb_recv_pkts可以从对应mbuf读取数据了;以下为eth_igb_recv_pkts函数的大致流程:
//获取读取mbuf的起始mbuf,即上次读取的最后一个mbuf的下一个mbuf;
rx_id = rxq->rx_tail;//下标
rxdp = &rx_ring[rx_id];//对应的描述符
//通过DD标志判断当前mbuf是否可读
if (! (staterr & rte_cpu_to_le_32(E1000_RXD_STAT_DD)))
break;
//从内存池申请一个新的mbuf,这个是实现网络帧零copy的关键地方,即当前要读取的mbuf的从sw_ring中出队给接收方,然后把新申请的mbuf入队到sw_ring,只是指针的操作,避免了真正的数据copy
nmb = rte_mbuf_raw_alloc(rxq->mb_pool);//申请新的mbuf
rxe = &sw_ring[rx_id];//待读取的mbuf
rxm = rxe->mbuf;//把待读取的mbuf从sw_ring中出队给接收方
rxe->mbuf = nmb;//把新申请的mbuf入队到sw_ring
dma_addr = rte_cpu_to_le_63(rte_mbuf_data_iova_default(nmb));//计算新申请的mbuf的iova指针
rxdp->read.hdr_addr = 0;//重置DD标志为0
rxdp->read.pkt_addr = dma_addr;//对应的rx_ring也要更新mbuf的iova指针
然后对读取到的mbuf头部数据做一些设置,包括一些通用设置和硬件的offload标志设置;
/*
* Initialize the returned mbuf.
* 1) setup generic mbuf fields:
* - number of segments,
* - next segment,
* - packet length,
* - RX port identifier.
* 2) integrate hardware offload data, if any:
* - RSS flag & hash,
* - IP checksum flag,
* - VLAN TCI, if any,
* - error flags.
*/
rx_pkts[nb_rx++] = rxm;//把读取到的mbuf返回给接收方(调用者)
rxq->rx_tail = rx_id;//更新用户态的读指针
在读取mbuf的数量达到阈值时,需要更新网卡的寄存器(相当于更新描述符队列rx_ring)的读指针,为网卡继续写mbuf创造空间,需要注意的是要防止rx_ring的读写指针重合,所以更新网卡寄存器的读指针时要减去1(因为dpdk侧读完mbuf时rx_ring的读写指针会重合);
/*
* If the number of free RX descriptors is greater than the RX free
* threshold of the queue, advance the Receive Descriptor Tail (RDT)
* register.
* Update the RDT with the value of the last processed RX descriptor
* minus 1, to guarantee that the RDT register is never equal to the
* RDH register, which creates a "full" ring situtation from the
* hardware point of view...
*/
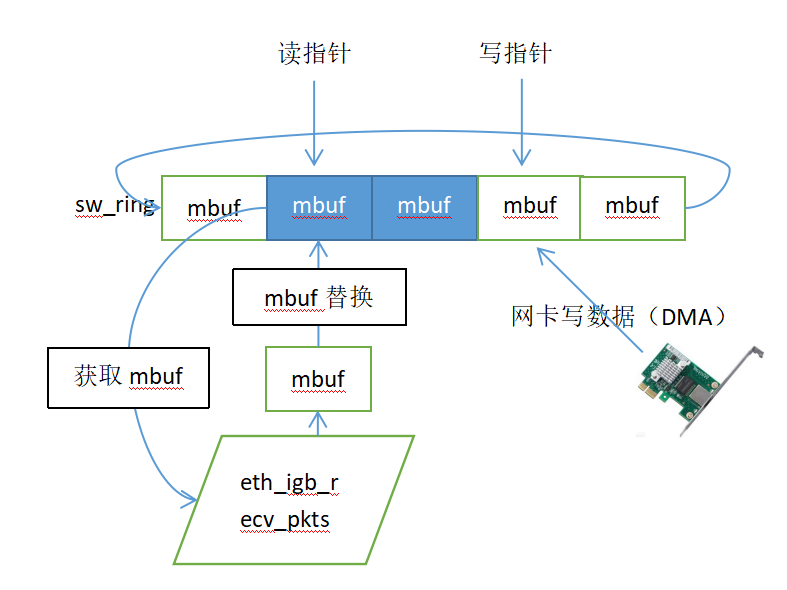
以上收包流程大致如下图所示:
3. 发包流程
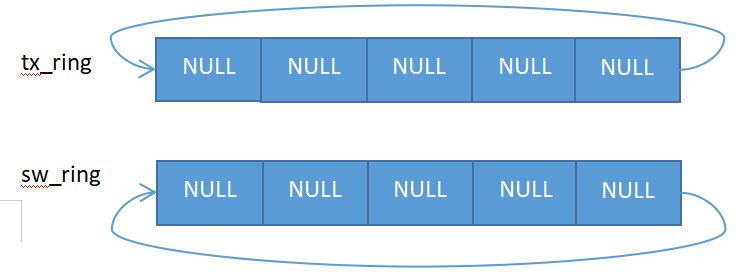
eth_igb_dev_init初始化函数把函数指针tx_pkt_burst指向eth_igb_xmit_pkts函数,eth_igb_tx_queue_setup函数会创建并初始化队列tx_queues,此时tx_queues队列里的sw_ring是没有挂接mbuf的,所以也不用对tx_ring进行mbuf的iova指针赋值,结构如下:
分析eth_igb_xmit_pkts函数可知,mbuf的挂接到sw_ring是此函数完成的,具体发送流程如下:
//获取本次发送的mbuf需要挂接sw_ring的起始位置
tx_id = txq->tx_tail;//获取下标
txe = &sw_ring[tx_id];//对应的sw_ring的起始位置
//挂接前同样需要判断当前位置的mbuf是否已经发送完成,即DD标志是否为1
//因为发送的mbuf可能是级联的,所以要判断所有mbuf所占用的位置对应的mbuf是否都已经发送完成
//这里不但要求本次mbuf所占用的位置对应的mbuf发送完成,而且要求后面的一个级联mbuf也发送完成,具体操作如下
/*
* 先找到当前要发送的mbuf(如果为级联mbuf,则需要计算到最后一个mbuf)占
* 用的sw_ring位置A,然后找到A所在的级联mbuf的最后一个mbuf所占的sw_ring
* 的位置B,然后再找到B的下一个位置C,找到C所在的级联mbuf的最后一个mbuf所
* 占的sw_ring的位置D,只有D所在的mbuf被发送成功后,才满足这次发送mbuf所需
* 要的sw_ring的空间,相当于为本次发送预留两次发送mbuf的空间
*/
tx_last = (uint16_t) (tx_id + tx_pkt->nb_segs - 1);//位置A
/*
* The "last descriptor" of the previously sent packet, if any,
* which used the last descriptor to allocate.
*/
tx_end = sw_ring[tx_last].last_id;//位置B
/*
* The next descriptor following that "last descriptor" in the
* ring.
*/
tx_end = sw_ring[tx_end].next_id;//位置C
/*
* The "last descriptor" associated with that next descriptor.
*/
tx_end = sw_ring[tx_end].last_id;//位置D
/*
* Check that this descriptor is free.
*/
if (! (txr[tx_end].wb.status & E1000_TXD_STAT_DD)) {//判断位置D对应的mbuf是否发送完成
if (nb_tx == 0)
return 0;
goto end_of_tx;
}
//如果满足本次发送所需的sw_ring空间,则开始循环(循环是为了级联mbuf,所有级联的mbuf都要挂接)挂接本次mbuf到sw_ring;
do {
txn = &sw_ring[txe->next_id];//预取下一个sw_ring位置
txd = &txr[tx_id];//当前待挂接mbuf的sw_ring位置对应的描述符tx_ring
if (txe->mbuf != NULL)
rte_pktmbuf_free_seg(txe->mbuf);//释放当前sw_ring位置对应的mbuf,这个mbuf为之前挂接的,已经由网卡发送完成
txe->mbuf = m_seg;//把本次待发送的mbuf挂接到sw_ring
/*
* Set up transmit descriptor.
*/
//设置sw_ring对应的描述符tx_ring的信息,包括mbuf的iova指针等
slen = (uint16_t) m_seg->data_len;
buf_dma_addr = rte_mbuf_data_iova(m_seg);
txd->read.buffer_addr =
rte_cpu_to_le_63(buf_dma_addr);
txd->read.cmd_type_len =
rte_cpu_to_le_32(cmd_type_len | slen);
txd->read.olinfo_status =
rte_cpu_to_le_32(olinfo_status);
txe->last_id = tx_last;//本次发送mbuf的最后一个mbuf占用的sw_ring位置,每个mbuf对应的sw_ring的last_id都要设置为tx_last,表示本次级联mbuf占用的一组sw_ring的尾部
tx_id = txe->next_id;//移动位置下标
txe = txn;//为本次级联mbuf的下一个mbuf挂接准备sw_ring位置
m_seg = m_seg->next;//开始挂接级联mbuf的下一个mbuf
} while (m_seg != NULL);
//为本次级联mbuf设置结束符,即让网卡知道本次级联mbuf有几个分段(mbuf)需要发送
/*
* The last packet data descriptor needs End Of Packet (EOP)
* and Report Status (RS).
*/
txd->read.cmd_type_len |=
rte_cpu_to_le_32(E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS);
//在待发送的mbuf挂接sw_ring完成后,需要更新网卡寄存器里的写指针
/*
* Set the Transmit Descriptor Tail (TDT).
*/
E1000_PCI_REG_WRITE_RELAXED(txq->tdt_reg_addr, tx_id);
txq->tx_tail = tx_id;//同步更新用户态的写指针
以上代码流程大致如下图所示: