


一、N-Gram参数空间过大问题
为了解决这个问题,引入马尔科夫假设:模型的当前状态仅仅依赖于前面的几个状态,这个假设简化了模型,减少了参数,假设仅仅依赖于前面两个状态的话,那么第N个词就只用基于前面的N-1和N-2个词,而不是从1到N-1的所有词,参数从而降低。
根据这个依赖数量,N-Gram可以分为:
- Bi-gram : 仅仅依赖前面的一个词,例如:$p(i)p(love|i)p(deep|love)p(learning|deep)$,bi这个英文前缀,表示两个,所以,这里其实就是“I love”、“love deep”、“deep learning”这样两单词的组合的意思;
- Tri-gram: 表示3个的意思,所以就是依赖前面两个词,变成了$p(i)p(love|i)p(deep|i, love)p(learning|deep,love)$
- 这里也可以体会到N-Gram中的N是一个什么含义,当然也可以弄个4-gram,但是常用的就是2和3
- Unigram这是一个可能听说过,但是不怎么用的模型,就是每个单词单独考虑,完全不考虑单词之间的组合的一个模型,每一个单词自身都是独立的,$p(i)p(love)p(deep)p(learning)$,这个句子与$deep learning love i 在Unigram模型下没有区别,这里要再提到一个概念bag of word(BOW)词袋模型,这个模型其实就和Unigram一样,不考虑单词的顺序,只考虑单词的频率。
二、N-Gram模型可以做什么
- 词性标注:love可以表示名词,也可以表示动词。对数据库中所有的单词进行词性标注,然后判断 I love 的love是一个什么词性,就用N-Gram模型:$p(动词| I的词性,love)=\frac{前一个词是代词,love是动词的组合的数量}{前面一个词是代词,不管love是什么词性的组合的数量}$
- 文本类别判断之是否是垃圾邮件:数据库中有垃圾邮件和非垃圾邮件,然后根据模型可以知道垃圾邮件中有什么词组,比如:大甩卖、畅销这样的词汇,然后根据这些内容,计算一个文本是否是垃圾邮件的概率
- 做情感分析,经常用在电影评论上面,判断一个评论是正面评论还是负面评论,还是中立的,可以把文本细分成六个情感类型:愤怒、厌恶、恐惧、喜悦、悲伤、惊喜
三、利用N-Gram模型评估语句是否合理
假设现在有一个语料库,我们统计了下面的一些词出现的数量

下面的这些概率值作为已知条件:
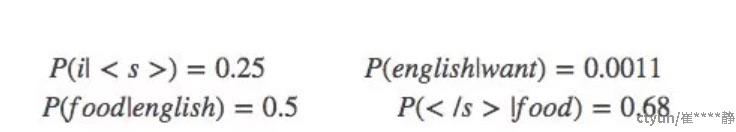
p(want|<s>) =0.25
下面这个表给出的是基于Bigram模型进行计数之结果
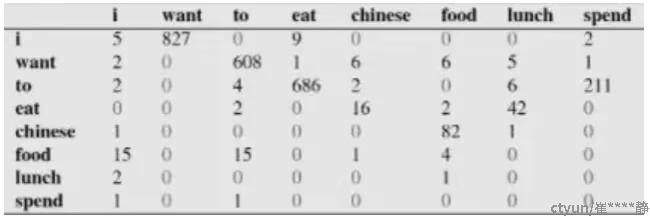
例如,其中第一行,第二列 表示给定前一个词是 “i” 时,当前词为“want”的情况一共出现了827次。据此,我们便可以算得相应的频率分布表如下。
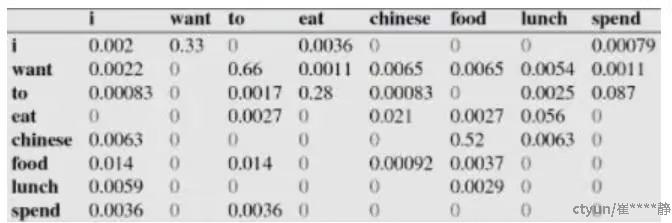
比如说,我们就以表中的p(eat|i)=0.0036这个概率值讲解,从表一得出“i”一共出现了2533次,而其后出现eat的次数一共有9次,p(eat|i)=p(eat,i)/p(i)=count(eat,i)/count(i)=9/2533 = 0.0036
下面我们通过基于这个语料库来判断s1=“<s> i want english food</s>” 与s2 = "<s> want i english food</s>"哪个句子更合理:
首先来判断p(s1)
P(s1)=P(i|<s>)P(want|i)P(english|want)P(food|english)P(</s>|food)
=0.25×0.33×0.0011×0.5×0.68=0.000031
再来求p(s2)?
P(s2)=P(want|<s>)P(i|want)P(english|want)P(food|english)P(</s>|food)
=0.25*0.0022*0.0011*0.5*0.68 = 0.00000002057
通过比较我们可以明显发现0.00000002057<0.000031,也就是说s1= "i want english food</s>"更合理。
当然,以上是对于二元语言模型(bigram model)的,大家也可以算下三元,或者1元语言模型的概率,不过结果都应该是一样的。
再深层次的分析,我们可以发现这两个句子的概率的不同,主要是由于顺序i want还是want i的问题,根据我们的直觉和常用搭配语法,i want要比want i出现的几率要大很多。所以两者的差异,第一个概率大,第二个概率小,也就能说的通了。
