


前言
2021年,“湖仓一体”首次被写入Gartner数据管理领域成熟度报告。2023年6月,大数据技术标准推进委员会发布了《湖仓一体技术与产业研究报告(2023年)》。报告中指出,湖仓一体是指融合数据湖与数据仓库的优势,形成一体化、开放式数据处理平台的技术。通过湖仓一体技术,可使得数据处理平台底层支持多数据类型统一存储,实现数据在数据湖、数据仓库之间无缝调度和管理,并使得上层通过统一接口进行访问查询和分析。
通过定义我们可以看出,湖仓一体是一个用于大数据分析的新技术,在这项技术中对存储、计算和应用都提出了新的要求。
为什么要做湖仓一体
数据仓库主要基于MPP或者关系型数据库来实现,主要支撑结构化数据在OLAP场景下的BI分析和查询需求。数据湖是基于Hadoop生态实现的,主要用于支撑多源异构的数据存储,满足批处理、流式计算等业务场景。
为了满足多种业务场景的分析诉求,在企业的数据分析平台构建时,常常需要同时构建数据仓库和数据湖两套独立的系统。如下图所示,
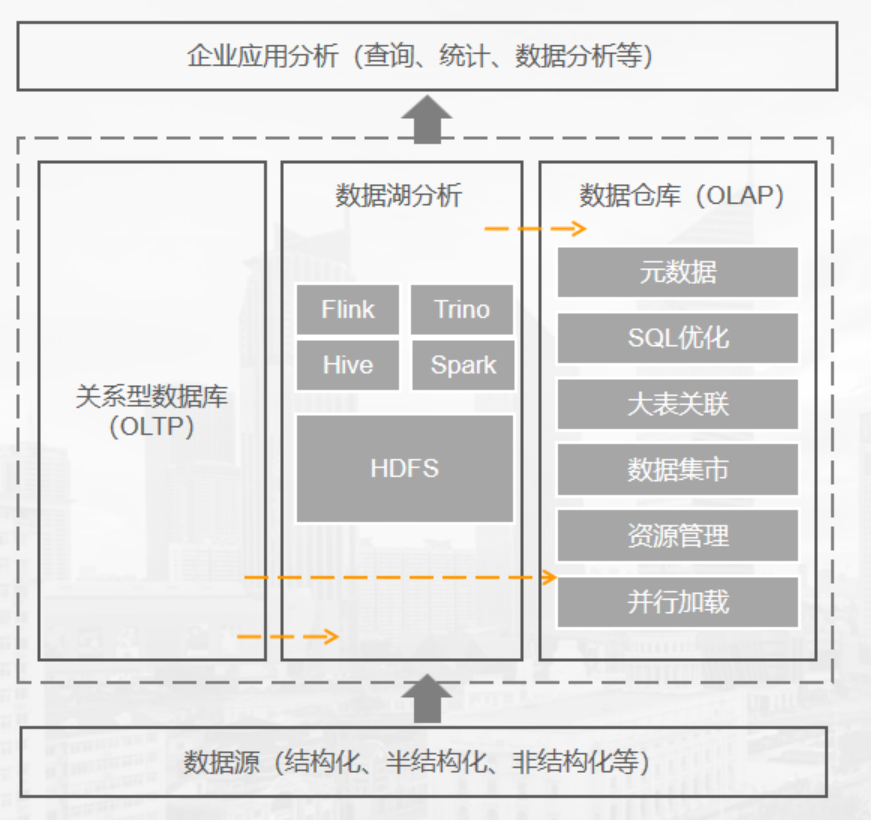
这种混合的架构虽然满足了业务需求,但也存在一些弊端:
● 数据冗余
技术上,引擎对数据做了冗余备份;业务上同一份数据可能在两个系统中同时存在。既增加了存储成本,又为数据不一致性埋下了伏笔。
● 时效性差
数据处理链路较长。数据通常先入湖,再通过ETL入仓,影响数据处理的时效性。
● 数据一致性问题
两个系统之间通过数据迁移实现数据流动,在迁移过程中容易出现数据不一致的问题,增加了数据校验的成本。
● 运维难
两个独立的系统和技术栈,使得数据架构复杂,平台开发运维难度较大,成本升高。
因此,我们系统通过将湖和仓融合的方式,重新设计架构,通过引入数据仓库治理能力,挖掘数据湖中的数据价值,将高效建仓和灵活建湖两大优势相结合,提升了数据管理效率和灵活性。 “湖仓一体”的英文翻译是Lakehouse,从单词构成也可以看出这个目标,即Data Lake + Data Warehouse。
湖仓一体的关键模块
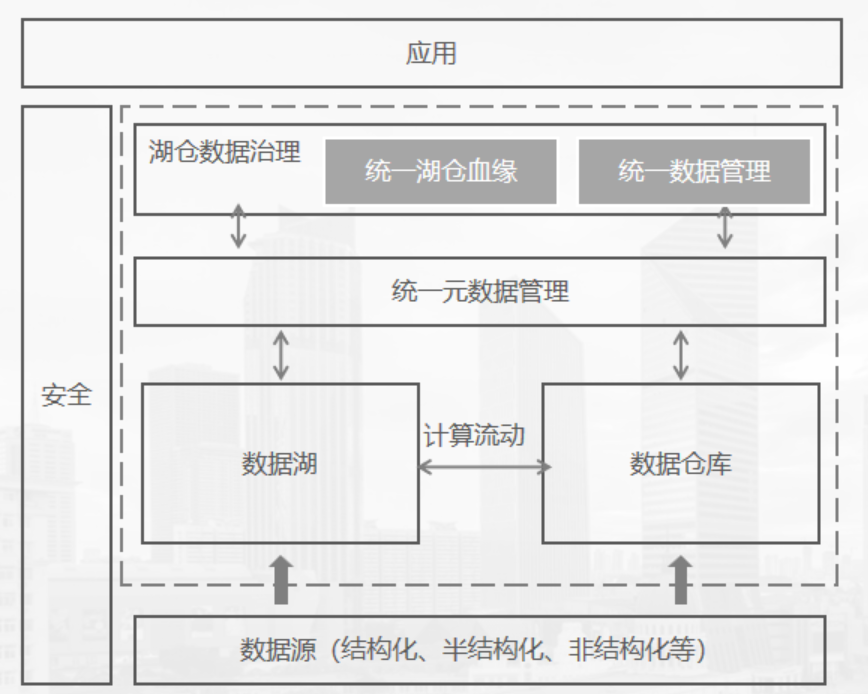
上图是湖仓一体的架构模块图,按功能我们将它划分为以下几个层级:数据入湖、存储层、元数据层、计算层和应用层。其中,前面四个层级更偏底层平台。
● 数据入湖仓
关注数据源(Source)和目的地(Sink),通常数据源包含了关系型数据库、NoSQL数据库、分布式文件系统、消息队列等多种类型。数据经过处理按照实时或批量的方式写入数据湖或数据仓库中。同时,在湖仓之间亦可以按需进行流动。
● 存储层
数据仓库通常内置存储能力,专门服务于该数仓引擎。对于数据湖分析而言,通常采用存算分离的方式,将数据进行集中存储(例如,对象存储)。同时,数据湖存储还会根据数据访问的频次,进行冷热温分层存储。
● 元数据层
提供统一的元数据的管理和权限管理。支持的计算引擎的丰富度是关键。元数据的发现可与数据入湖的能力进行联动,在入湖的同时自动识别。统一的权限管理可以让用户当通过不同引擎访问同一份数据时,保持权限一致,简化配置流程。
● 计算层
根据业务场景选择不同的计算引擎,包括批处理、流式计算、即席查询等。对于Hadoop生态的引擎(如Hive、Spark、Flink、Trino等),都可以支持数据湖存储及包含Delta、Hudi、Iceberg在内的多种存储格式。以Doris、ClickHouse为数仓产品,也支持读写数据湖中的数据,实现数据在湖仓之间的双向流通。
