


前言
在《浅析湖仓一体》一文中,我们介绍了关于湖仓一体的基本知识,以及在湖仓一体的方案中包含的关键模块。我们将在本文中介绍如何构建湖仓一体。2023年6月,大数据技术标准推进委员会发布了《湖仓一体技术与产业研究报告(2023年)》。在报告中提出了两种实践路径,分别是湖上建仓和仓外挂湖。
湖和仓的比较
下面的表格中从数据类型、技术架构、编程接口、产品生态、运维成本等方面对比了湖分析和数仓分析的差异。
除此之外,两类计算引擎在原理和应用场景上也有差别。数据湖分析是读取型Schema,即数据在读取时才会被按照Schema的定义进行解析;而传统数仓是写入型Schema,即数据在存入数仓时已经按照Schema的定义进行解析存储。在应用场景上,数据湖分析主要用于多源异构的数据分析,执行批处理、流处理等工作负载;而传统数仓主要用于对结构化数据的BI分析、Ad-hoc查询等。
另外,数据湖分析中,存储系统一般为HDFS或对象存储系统,因此无法支持像数仓那样对库表中的指定行数据进行修改和删除,这也是在需要在后面的湖仓建设中重点解决的问题。
| 对比项 | 数据湖分析 | 传统数仓 |
| 数据 | 所有数据,包括结构化、半结构化和非结构化数据 | 来自事务系统、运营数据库和业务线应用程序的关系型数据 |
| 计算与存储架构 | 从早期的存算一体,逐步演进到存算分离 | 以存算一体为主,架构上向MPP演进 |
| 编程接口 | 取决于引擎的选择,支持SQL/Java/Python等 | 以SQL为主 |
| 产品生态 | 以开源Hadoop生态为主,选择性较多 | 取决于引擎自身集成与被集成的能力 |
| 运维成本 | 一个或多个组件各异的集群,运维门槛高 | 集群引擎单一,存在扩缩容、性能优化等运维难点 |
湖上建仓
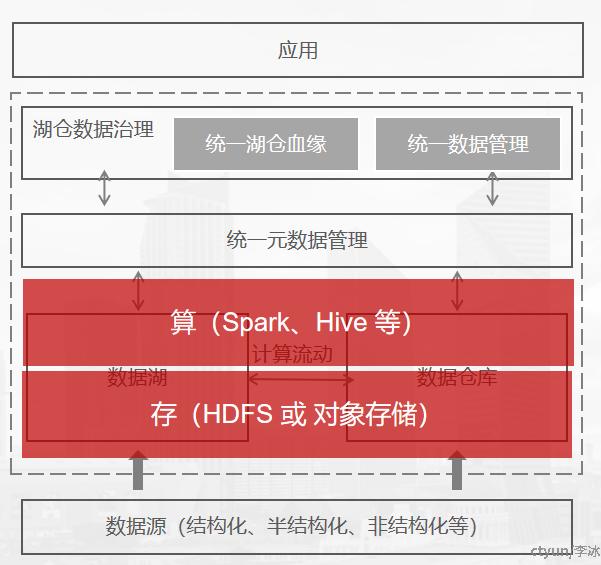
湖上建仓的方式是以数据湖为基础,通过引入新的数据湖格式(Deltalake、Hudi、Iceberg、Paimon等)作为数据存储中间层,实现对数据的删改,进而满足数仓场景中对数据增删改查的需求。
另外,数据湖分析中由于其自身引擎的多样性和面向离线批处理场景的引擎设计,使得统一元数据管理、统一权限管理和查询性能提升,成为了其在迈向湖仓一体的过程中必需解决的问题。例如,云厂商的Data Lake Formation产品、Gravitino等产品都锚向了统一元数据领域方向。
仓外挂湖
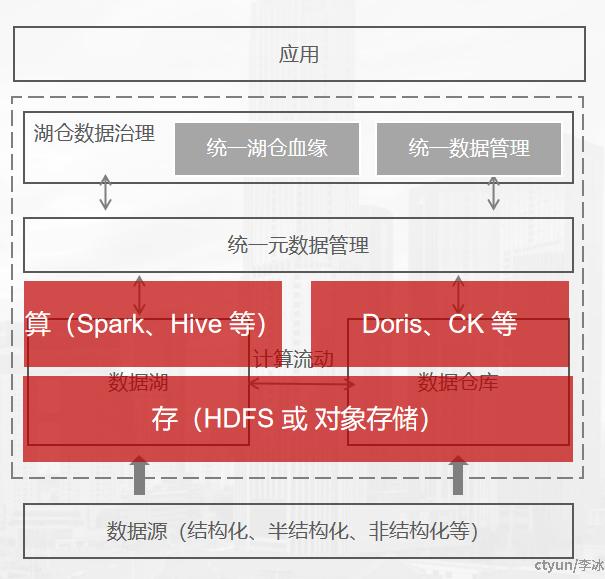
仓外挂湖的方式是指以MPP数据库为基础,使用可插拔架构,通过开放接口对接外部存储实现统一存储,在存储底层共享一份数据。在实际的应用中,通常采用让数仓引擎可以直接读写数据湖存储(HDFS或对象存储)的方式,而无需将数据进行转移。数仓往往为了保证数据查询效率,都有自己的内置存储。因此,对于数仓引擎来说,存算分离、数据缓存、统一元数据管理是今年来较为热门的能力特性。
小结
无论是湖上建仓还是仓外挂湖,都涉及了多个计算引擎的联合实现,无论哪种实践路径,都存在业务上的改造。因此,方案的选择上还应综合考虑当前的业务架构,如果是以实时数仓为主的场景,那么仓外挂湖的方式更适合;反之,如果多以离线处理、批处理为主,则湖上建仓的方式改造成本更低,现实中也是落地更多。
