


概述
Linux 开启分页后,物理内存的管理就会交给伙伴系统。伙伴系统有如下特点
- 有点:简单,高效
- 缺点:只能避免外碎片,不能避免内碎片。不能分配小于一页的内存
基本原理
伙伴系统分配内存的基本单位是 "页"。其组织结构有点类似于 "桶"
-
桶里面有不同 order 的链表头,管理着不同数量page组成的单元, 每个单元里page数量就是 $2^{order}$. 0号链表管理的单元是 1个page, 2号链表管理的单元是2个page....
-
需要分配page时,根据 order 从对应链表下进行分配。若不成功,则从更高 order 链表下分配。更高order链表下的单元会被拆成更小的单元,挂到对应 order 的链表下
-
当释放 page 时,会考虑该 page 是否能合并。若能合并,则挂载到更高 order 的链表下
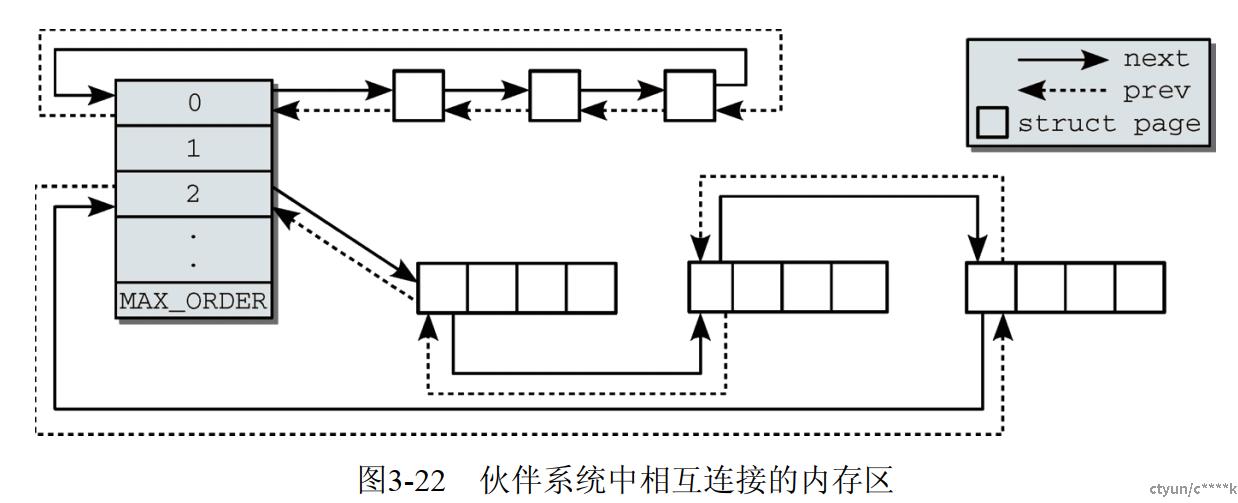
图片来源: 深入Linux内核架构
buddy 与 zone
伙伴系统专注于某个节点的内存域。当首选节点的内存区域无法满足分配请求时,会尝试从其他备用zone 分配。
当前伙伴系统的信息可以通过如下命令查看
> cat /proc/buddyinfo
//横轴表示阶数: order-0...order11
Node 0, zone DMA 0 0 0 0 0 0 0 0 1 2 2
Node 0, zone DMA32 6 6 7 8 9 8 8 5 7 7 787
Node 0, zone Normal 1999 2881 1377 5413 3054 721 234 12 3 7 1562
数据结构及API
数据结构
伙伴系统的数据结构位于 mmzone.h,可以看到非常简介。基本和前面介绍的内容一致。
#define MIGRATE_UNMOVABLE 0
#define MIGRATE_RECLAIMABLE 1
#define MIGRATE_MOVABLE 2
#define MIGRATE_RESERVE 3
#define MIGRATE_ISOLATE 4 /* can't allocate from here */
#define MIGRATE_TYPES 5
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
#define MAX_ORDER 11 //默认值是11,否则通过配置 CONFIG_FORCE_MAX_ZONEORDER 决定
struct zone {
...
struct free_area free_area[MAX_ORDER];
...
} ____cacheline_internodealigned_in_smp;
在 2.6.23 以前,引入 struct free_area 仅有一个 free_list。后续引入多个 MIGRATE_TYPES 是为减少物理内存碎片,更多详见 深入linux内核架构: 3.5.2
但我们本次分析会忽略多个 free_list
API
最重要的两类 API 就是分配和释放了。这里仅列出最具代表性的 API 。同时可以看到,linux 同一类的API可以在不同文件中声明。
[include/linux/gfp.h]
struct page *alloc_pages(gfp_t gfp_mask, unsigned int order);
...
[mm/page_alloc.c]
void free_pages(unsigned long addr, unsigned int order);
...
- alloc_pages: 所有分配相关的API,最后的核心都是 __alloc_pages,这也是本篇文章分析的重点
- free_pages: 核心调用 __free_pages
Linux 还提供了很多标志,用于控制分配的行为,具体含义请查阅相关资料
[include/linux/gfp.h]
#define __GFP_WAIT ((__force gfp_t)0x10u) /* Can wait and reschedule? */
#define __GFP_HIGH ((__force gfp_t)0x20u) /* Should access emergency pools? */
#define __GFP_IO ((__force gfp_t)0x40u) /* Can start physical IO? */
...
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_NOWAIT (GFP_ATOMIC & ~__GFP_HIGH)
#define GFP_ATOMIC (__GFP_HIGH)
...
常用MASK分析
-
最常用
- GFP_KERNEL: 内核内存的分配,可以睡眠
- GFP_ATOMIC: 分配过程中不能睡眠
- GFP_USER: 用户内存的分配,可以睡眠
-
Zone 角度
- GFP_DMA: 仅在 ZONE_DMA 查找可用内存
- GFP_NORMAL(默认): 优先考虑 ZONE_NORMAL, 其他是 ZONE_DMA
- GFP_HIGHMEM: 优先考虑 ZONE_HIGH, 其他是 ZONE_DMA
Page-flags标志
page->flags
- __ClearPageBuddy(): PG_buddy 位,在伙伴系统中,未被使用需要设置该位。
page->private: 该成员表示该page对应伙伴系统中的order
- set_page_private(): 当从伙伴系统中移除时,需要设置将该位清零。
- rmv_page_order() / set_page_order()
伙伴系统初始化
概述
伙伴系统初始化的源码地图如下
[linux-2.6.24]
start_kernel()
-> setup_arch()
-> zone_sizes_init() -> free_area_init_nodes()
-> mem_init()
zone_sizes_init()
zone_sizes_init() 主要工作是初始化 zone->free_area 成员。
调用链:zone_sizes_init() -> free_area_init_nodes() ->free_area_init_node() -> free_area_init_core() -> init_currently_empty_zone() -> zone_init_free_lists()
忽略冗长的调用链中间过程,我们从 free_area_init_node 开始分析
[linux-2.6.24/mm/page_alloc.c]
void __meminit free_area_init_node(int nid, struct pglist_data *pgdat,
unsigned long *zones_size, unsigned long node_start_pfn,
unsigned long *zholes_size)
{
pgdat->node_id = nid;
pgdat->node_start_pfn = node_start_pfn;
calculate_node_totalpages(pgdat, zones_size, zholes_size);
alloc_node_mem_map(pgdat);
free_area_init_core(pgdat, zones_size, zholes_size);
}
主要工作如下
- alloc_node_mem_map(): 创建 struct page 管理每一个 page
- free_area_init_core(): 伙伴系统的核心初始化。该函数会初始化zone,以及最重要的 zone->free_area
alloc_node_mem_map()
[mm/memory.c]
struct page *mem_map;
[mm/page_alloc.c]
static void __init_refok alloc_node_mem_map(struct pglist_data *pgdat)
{
#ifdef CONFIG_FLAT_NODE_MEM_MAP
/* ia64 gets its own node_mem_map, before this, without bootmem */
if (!pgdat->node_mem_map) { --- A
unsigned long size, start, end;
struct page *map;
start = pgdat->node_start_pfn & ~(MAX_ORDER_NR_PAGES - 1); //通常是0
end = pgdat->node_start_pfn + pgdat->node_spanned_pages;
end = ALIGN(end, MAX_ORDER_NR_PAGES);
size = (end - start) * sizeof(struct page);
if (!map)
map = alloc_bootmem_node(pgdat, size);
pgdat->node_mem_map = map + (pgdat->node_start_pfn - start);
}
if (pgdat == NODE_DATA(0)) {
mem_map = NODE_DATA(0)->node_mem_map; --- B
...
}
#endif /* CONFIG_FLAT_NODE_MEM_MAP */
}
该函数的主要功能是为 struct page 分配内存空间。这里主要分析平坦内存模型
- A: 计算需要分配的 size, 然后调用 alloc_bootmem_node() 分配对应的页。注意,这里所有的计算都按最大分配阶对齐(为什么呢??)
- B: 将 struct page 记录到 全局数组 mem_map 中。
free_area_init_core()
free_area_init_core 会对 zone 进行系统的初始化。我们暂时仅关注和 zone->frea_area相关的,直接来看 zone_init_free_lists 函数
static void __meminit zone_init_free_lists(struct pglist_data *pgdat,
struct zone *zone, unsigned long size)
{
int order, t;
for_each_migratetype_order(order, t) {
INIT_LIST_HEAD(&zone->free_area[order].free_list[t]);
zone->free_area[order].nr_free = 0;
}
}
代码比较简介。就是初始化 zone->free_area 链表头和 nr_free
mem_init
mem_init 所有的重点就一个,将 bootmem 管理的内存,释放到 buddy 子系统。
void __init mem_init(void)
{
...
/* this will put all low memory onto the freelists */
totalram_pages += free_all_bootmem();
...
}
free_all_bootmem
free_all_bootmem() 实现是调用 free_all_bootmem_core()
static unsigned long __init free_all_bootmem_core(pg_data_t *pgdat)
{
struct page *page;
unsigned long pfn;
bootmem_data_t *bdata = pgdat->bdata;
unsigned long i, count, total = 0;
unsigned long idx;
unsigned long *map;
int gofast = 0;
count = 0;
/* first extant page of the node */
pfn = PFN_DOWN(bdata->node_boot_start);
idx = bdata->node_low_pfn - pfn;
map = bdata->node_bootmem_map;
/* Check physaddr is O(LOG2(BITS_PER_LONG)) page aligned */
if (bdata->node_boot_start == 0 ||
ffs(bdata->node_boot_start) - PAGE_SHIFT > ffs(BITS_PER_LONG))
gofast = 1; --- A
for (i = 0; i < idx; ) { --- B
unsigned long v = ~map[i / BITS_PER_LONG]; --- B1
if (gofast && v == ~0UL) { --- B2
int order;
page = pfn_to_page(pfn);
count += BITS_PER_LONG;
order = ffs(BITS_PER_LONG) - 1;
__free_pages_bootmem(page, order);
i += BITS_PER_LONG;
page += BITS_PER_LONG;
} else if (v) { --- B3
unsigned long m;
page = pfn_to_page(pfn);
for (m = 1; m && i < idx; m<<=1, page++, i++) { --- B3.1
if (v & m) {
count++;
__free_pages_bootmem(page, 0);
}
}
} else {
i += BITS_PER_LONG;
}
pfn += BITS_PER_LONG;
}
total += count;
/* Now free the allocator bitmap itself, it's not needed anymore */
page = virt_to_page(bdata->node_bootmem_map); --- C
count = 0;
idx = (get_mapsize(bdata) + PAGE_SIZE-1) >> PAGE_SHIFT;
for (i = 0; i < idx; i++, page++) {
__free_pages_bootmem(page, 0);
count++;
}
total += count;
bdata->node_bootmem_map = NULL;
return total;
}
将 bootmem 内存释放到伙伴系统,最重要的函数是 __free_pages_bootmem():
- A & B2: 是否能快速释放到 zone->free_area 指定 order 的链表。这里为什么会有这样算法后续分析
- B: index 就是 bit 的索引,每一个 bit 代表一个 page.
- B1: 这里以 Long 数据长度为基本单位处理。由于仅释放 bootmem 中未分配的页,故取反就可以知道该组page有没有空闲 page 需要释放。若该组page都已经被使用,取反就是0
- B3: 遍历该组 page 中哪个bit 为 0,然后调用 __free_pages_bootmem 进行释放。这里空闲的page都会释放到 order=0 的阶数。然后根据让伙伴算法自己来选择是否合并。
- C: 释放 bootmem bitmap 本身所在的页。
__free_pages_bootmem()
void fastcall __init __free_pages_bootmem(struct page *page, unsigned int order)
{
if (order == 0) {
__ClearPageReserved(page);
set_page_count(page, 0);
set_page_refcounted(page);
__free_page(page);
} else {
int loop;
prefetchw(page);
for (loop = 0; loop < BITS_PER_LONG; loop++) {
struct page *p = &page[loop];
if (loop + 1 < BITS_PER_LONG)
prefetchw(p + 1);
__ClearPageReserved(p);
set_page_count(p, 0);
}
set_page_refcounted(page);
__free_pages(page, order);
}
}
参考 页释放[^1],核心是调用 __free_page()
页分配
概述
根据需求,页的分配提供一些经过 wrapped APIs, 本章仅分析所有API都会调用的核心函数:__alloc_pages
struct page *__alloc_pages(gfp_t gfp_mask, unsigned int order, struct zonelist *zonelist);
分配页的过程需要考虑很多复杂的情况
- 正常分配:相对简单,也是初始学习重点分析的流程
- 内存快耗尽时分配动作,需要和 kswap 配合
最简流程
本节主要从 "最简单" 分配流程入手,研究伙伴系统的核心
调用链:get_page_from_freelist() ->buffered_rmqueue() -> __rmqueue()
get_page_from_freelist
[linux-2.6.24/mm/page_alloc.c]
struct page * fastcall __alloc_pages(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist)
{
......
restart:
z = zonelist->zones; /* the list of zones suitable for gfp_mask */
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, order,
zonelist, ALLOC_WMARK_LOW|ALLOC_CPUSET);
if (page)
goto got_pg;
got_pg:
return page;
}
get_page_from_freelist
static struct page * get_page_from_freelist(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, int alloc_flags)
{
zonelist_scan:
z = zonelist->zones;
do {
... //忽略 NUMA, watermark 相关检测
zone = *z;
page = buffered_rmqueue(zonelist, zone, order, gfp_mask);
if (page)
break;
...
} while (*(++z) != NULL);
return page;
}
buffered_rmqueue
[mm/page_alloc.c]
static struct page *buffered_rmqueue(struct zonelist *zonelist,
struct zone *zone, int order, gfp_t gfp_flags)
{
...
again:
cpu = get_cpu();
if (likely(order == 0)) {
... //先尝试从本地CPU cache 中分配,失败在调用 rmqueue_bulk
} else {
spin_lock_irqsave(&zone->lock, flags); //关中断
page = __rmqueue(zone, order, migratetype);
spin_unlock(&zone->lock);
}
...
if (prep_new_page(page, order, gfp_flags)) //设置page->flags
goto again;
return page;
}
对于单页的分配(order == 0),优先考虑从本地 CPU Cache 中获取。多个页的分配则调用 __rmqueue
__rmqueue 是伙伴系统的核心,我们单独开一小节分析
__rmqueue
__rmqueue 是进入伙伴系统的核心入口
static struct page *__rmqueue(struct zone *zone, unsigned int order,
int migratetype)
{
struct page *page;
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page))
page = __rmqueue_fallback(zone, order, migratetype);
return page;
}
代码比较简洁
- __rmqueue_smallest: 在最适合的 zone 分配
- __rmqueue_fallback: 合适的 zone 不满足分配请求,fallback到备用列表
__rmqueue_smallest
static struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area * area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype])) --- A
continue;
page = list_entry(area->free_list[migratetype].next, struct page, lru); --- B
list_del(&page->lru);
rmv_page_order(page); //page->flag 相关设置
area->nr_free--;
__mod_zone_page_state(zone, NR_FREE_PAGES, - (1UL << order)); //统计信息更新
expand(zone, page, order, current_order, area, migratetype); --- C
return page;
}
return NULL;
}
代码会从低到高,遍历 free_area[] 直到找到合适的 page
- A: 通过判断链表为空,来确认该 order 下,有没有充足的页可供分配
- B: 从原有的链表下取出第一个单元。并更新 free_area
- C: 对取出的单元,可能对应 order 更高。需要考虑将更高 order 拆分,加入到低阶的链表。
expand
继续研究伙伴系统细节,如何拆分
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
while (high > low) { --- A
area--; -- A //移动到更低阶的 order 链表
high--;
size >>= 1; --- C // order 阶数就是两倍的关系
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
}
}
代码很简介:
-
A:若 order 相等 (high == low), 不用拆分合并,直接返回。进入循环,则是 high > low, 需要拆分
-
B: 找到合适的链表头。
- area--: 先移动到低阶的 order 链表, 传入的 area 是高阶
-
C: 拆分合并
- size/2: 因为 order 阶数就是两倍的关系。从高逐级到低,必然是不停除以 2 的过程
- list_add(): 注意这里是 page[size], 意思是地址较低的page,继续执行该循环、拆分。地址较高的page,就加入到当前 order 链表中了
- set_page_order(): 同样 page[size]。对于高地址page, 更新其page对应的flag。建立和伙伴系统的联系
页释放
概述
页的释放函数核心入口是__free_pages
__free_pages
__free_pages
fastcall void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page)) {
if (order == 0)
free_hot_page(page);
else
__free_pages_ok(page, order);
}
}
和分配函数 buffered_rmqueue 相呼应
- 当释放的数量位1页时,调用 free_hot_page 释放到 per-cpu 的缓存中。这种策略被称之为惰性合并,用于防止大量可能白费时间的合并
- 大于 1 页调用 __free_pages_ok() 释放
__free_pages_ok
核心是调用 free_one_page() 里面的 __free_one_page()
static void __free_pages_ok(struct page *page, unsigned int order)
{
...
local_irq_save(flags);
free_one_page(page_zone(page), page, order);
local_irq_restore(flags);
...
}
static void free_one_page(struct zone *zone, struct page *page, int order)
{
spin_lock(&zone->lock);
zone_clear_flag(zone, ZONE_ALL_UNRECLAIMABLE);
zone->pages_scanned = 0;
__free_one_page(page, zone, order);
spin_unlock(&zone->lock);
}
__free_one_page
static inline void __free_one_page(struct page *page,
struct zone *zone, unsigned int order)
{
unsigned long page_idx;
int order_size = 1 << order;
int migratetype = get_pageblock_migratetype(page);
...
page_idx = page_to_pfn(page) & ((1 << MAX_ORDER) - 1); --- A
while (order < MAX_ORDER-1) { --- B
unsigned long combined_idx;
struct page *buddy;
buddy = __page_find_buddy(page, page_idx, order); --- B1
if (!page_is_buddy(page, buddy, order))
break; /* Move the buddy up one level. */
list_del(&buddy->lru); --- B2
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
combined_idx = __find_combined_index(page_idx, order); --- B3
page = page + (combined_idx - page_idx);
page_idx = combined_idx;
order++;
}
set_page_order(page, order); --- C
list_add(&page->lru,
&zone->free_area[order].free_list[migratetype]);
zone->free_area[order].nr_free++;
}
代码主要工作如下:
-
A: 根据 page 寻找 pfn。对于
-
B: 释放时要考虑合并操作。及将连续低阶 order 组合,放到高阶链表中。
- B1: 调用 __page_find_buddy 寻找该 page 对应的伙伴。这里寻找仅仅是根据 page_idx。故找到的伙伴未必可以合并,需要调用 page_is_buddy 验明真身。
- B2: 找到伙伴后,需要将伙伴从伙伴系统中移除
- B3: 将伙伴和需要释放的 page 合并
-
C: 当找到合适 order 的area, 且合并工作已经完成,则将该单元加入的对应的链表,并设置属性。
Pfn, Page, Buddy
Page 和 Buddy 相关的辅助函数主要在 free_page 时使用用到
page_to_pfn
#if defined(CONFIG_FLATMEM)
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
ARCH_PFN_OFFSET)
#else if....
page 和 pfn 之间的转换和内存模型有很大的关系。
- 平坦内存模型:所有 page 会存放到数组 mem_map 中。pfn 即是相对于 mem_map 的偏移
__page_find_buddy()
/*
* Locate the struct page for both the matching buddy in our
* pair (buddy1) and the combined O(n+1) page they form (page).
*
* 1) Any buddy B1 will have an order O twin B2 which satisfies
* the following equation:
* B2 = B1 ^ (1 << O)
* For example, if the starting buddy (buddy2) is #8 its order
* 1 buddy is #10:
* B2 = 8 ^ (1 << 1) = 8 ^ 2 = 10
*
* 2) Any buddy B will have an order O+1 parent P which
* satisfies the following equation:
* P = B & ~(1 << O)
*
* Assumption: *_mem_map is contiguous at least up to MAX_ORDER
*/
static inline struct page *
__page_find_buddy(struct page *page, unsigned long page_idx, unsigned int order)
{
unsigned long buddy_idx = page_idx ^ (1 << order);
return page + (buddy_idx - page_idx);
}
这里的核心是异或运算: 0 ^ A = A; A ^ A = 0, 故异或可以使对应 bit 位翻转
-
buddy 的 page_index 一定和该 page 相邻:前 或 后。且对应 index 一定是在 order 对应 bit 上 +1 或 -1
-
通过翻转 order 对应 bit 位。可以快速找到 buddy。例如
- 若 page_idx 对应 order 位为1, 其 buddy 对应的 order 为0。例如page_idx=0b101,order=1, buddy_idx=0b100
- 若 page_idx 对应 order 位为0, 其 buddy 对应的 order 为1。例如page_idx=0b100,order=1, buddy_idx=0b101
-
从上述案例可以看到
- buddy 并不是任何 page_index 都行。buddy_idx 和 page_index 只能在对应 order 所在 bit 不一样。例如page_idx=0b101,order=1, buddy_idx不能是0b110。
page_is_buddy
这个函数比较简单。不做过多分析
static inline int page_is_buddy(struct page *page, struct page *buddy, int order)
{
if (!pfn_valid_within(page_to_pfn(buddy)))
return 0;
if (page_zone_id(page) != page_zone_id(buddy))
return 0;
if (PageBuddy(buddy) && page_order(buddy) == order) {
BUG_ON(page_count(buddy) != 0);
return 1;
}
return 0;
}
__find_combined_index
__find_combined_index
对应 order 所在 bit 清零。即选择page_index 较低的页
static inline unsigned long __find_combined_index(unsigned long page_idx, unsigned int order)
{
return (page_idx & ~(1 << order));
}
总结
buddy 并不是任何 page_index 都行。buddy_idx 和 page_index 只能在对应 order 所在 bit 不一样。例如page_idx=0b101,order=1, buddy_idx不能是0b110。
参考
《深入linux内核架构》
