背景
推理计算图的优化可分为离线和在线两个阶段。
离线优化是指在推理任务开始之前,对神经网络的计算图进行静态的优化。这种优化是在模型部署前完成的,确保模型在部署后能够高效运行。
在线优化是指在推理过程中,动态调整计算图或执行策略,以适应输入数据、硬件资源或运行环境的变化。与离线优化不同,在线优化通常发生在推理阶段,根据实际运行情况实时进行优化调整。
离线优化可以对整个计算图进行深入分析,基于全局的视角进行复杂的优化。由于优化在模型部署前完成,因此推理过程中不会消耗额外的计算资源。离线优化可以针对具体的硬件进行高度定制,更容易控制优化对模型精度的影响。
在线优化可以根据运行时的实际情况进行动态适应调整,可以支持动态计算图,并根据硬件资源的当前状态灵活调度。但动态优化会增加运行时的开销,可能导致额外的延迟,并且在线优化通常较为简单,优化深度有限。
为了实现可针对硬件进行高度定制的全局深度优化,并且不增加运行时的开销,故选择离线优化方案。
离线优化模块
离线优化模块的挑战
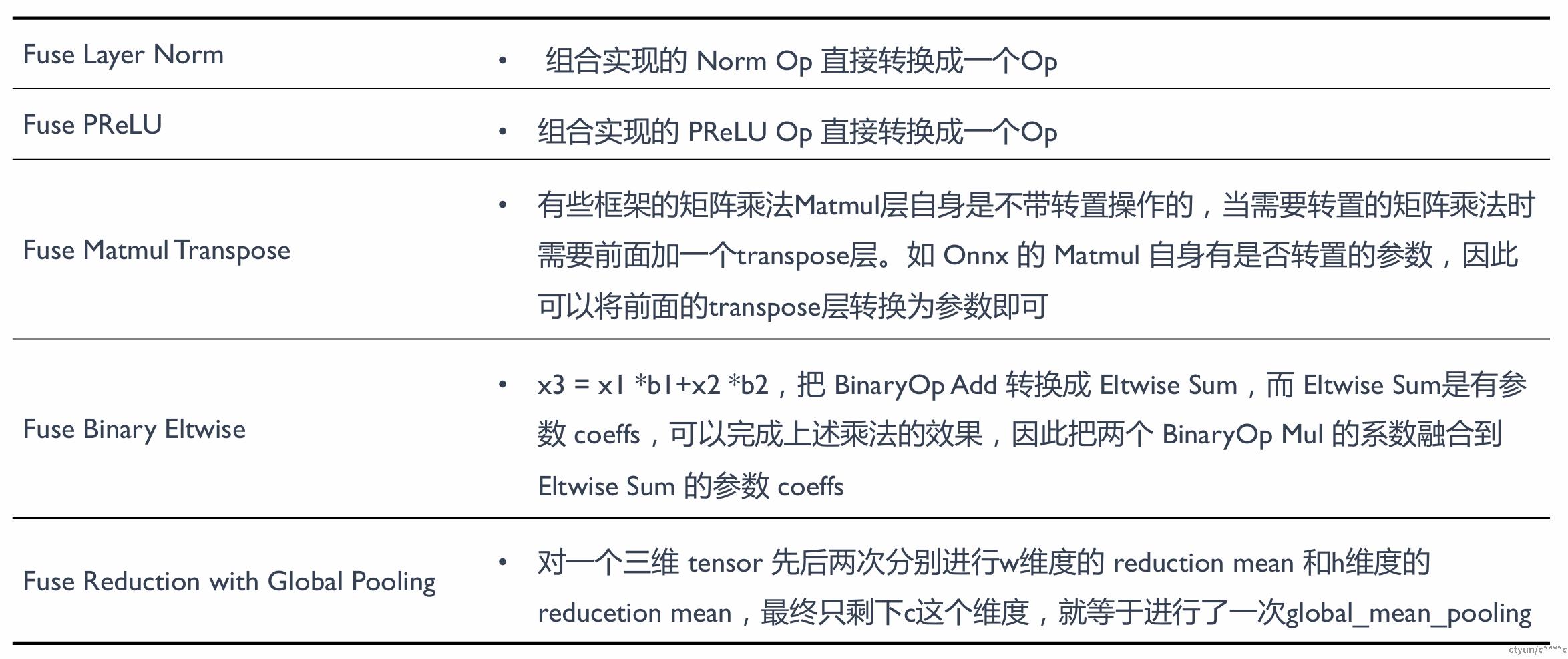
- 结构冗余:神经网络模型结构中的无效计算节点、重复的计算子图、相同的结构模块,可以在保留相同计算图语义情况下无损去除的冗余类型;
- 精度冗余:推理引擎数据单元是张量,一般为 FP32 浮点数,FP32 表示的特征范围在某些场景存在冗余,可压缩到 FP16/INT8 甚至更低;数据中可能存大量 0 或者重复数据。
- 算法冗余:算子或者 Kernel 层面的实现算法本身存在计算冗余,比如均值模糊的滑窗与拉普拉斯的滑窗实现方式相同。
- 读写冗余:在一些计算场景重复读写内存,或者内存访问不连续导致不能充分利用硬件缓存,产生多余的内存传输。
离线优化模块的解决方案
针对于结构冗余:一般会对计算图进行优化,例如算子融合、算子替换、常量折叠等。
- 算子融合(Operator Fusion):算子融合是指在计算图中,将多个相邻的算子(operations)融合成一个新的算子。这样可以减少运算过程中的数据传输和临时存储,从而提高计算效率。例如,如果有两个连续的矩阵乘法操作,可以将它们融合为一个新的操作,从而减少一次数据读写。这在 GPU 等并行计算设备上特别有用,因为它们的数据传输成本相对较高。
- 算子替换(Operator Substitution):算子替换是指在计算图中,用一个效率更高的算子替换原有的算子。例如,如果一个算子是通过多个基础操作组成的,那么可能存在一个复杂但效率更高的算子可以替换它。这样可以减少计算的复杂性,提高计算效率。
- 常量折叠(Constant Folding):常量折叠是指在计算图的优化过程中,预先计算出所有可以确定的常量表达式的结果,然后用这个结果替换原有的表达式。这样可以减少运行时的计算量。例如,如果计算图中有一个操作是3*4,那么在优化过程中,可以将这个操作替换为12。
针对于精度冗余:一般会对算子进行优化,例如量化、稀疏化、低秩近似等。
针对于算法冗余:一般会统一算子/计算图的表达,例如 kernel 提升泛化性等。
针对于读写冗余:一般会通过数据排布的优化和内存分配的优化进行解决。
计算图
目前主流的 AI 框架都选择使用计算图来抽象神经网络计算表达,通过通用的数据结构(张量)来理解、表达和执行神经网络模型,通过计算图可以把 AI 系统化的问题形象地表示出来。在 AI 框架中,计算图就是一个表示运算的有向无环图(Directed Acyclic Graph,DAG)。
计算图(Computation Graph):被定义为有向图,计算图是表达和评估数学表达式的一种方式。普通计算图节点表示数据,如向量、矩阵、张量;边表示具体执行的运算,如加、减、乘、除和卷积等。
以公式为例:
f(x1, x2) = ln(x1) + x1x2 - sin(x2)
对上述公式转换为对应的计算图。
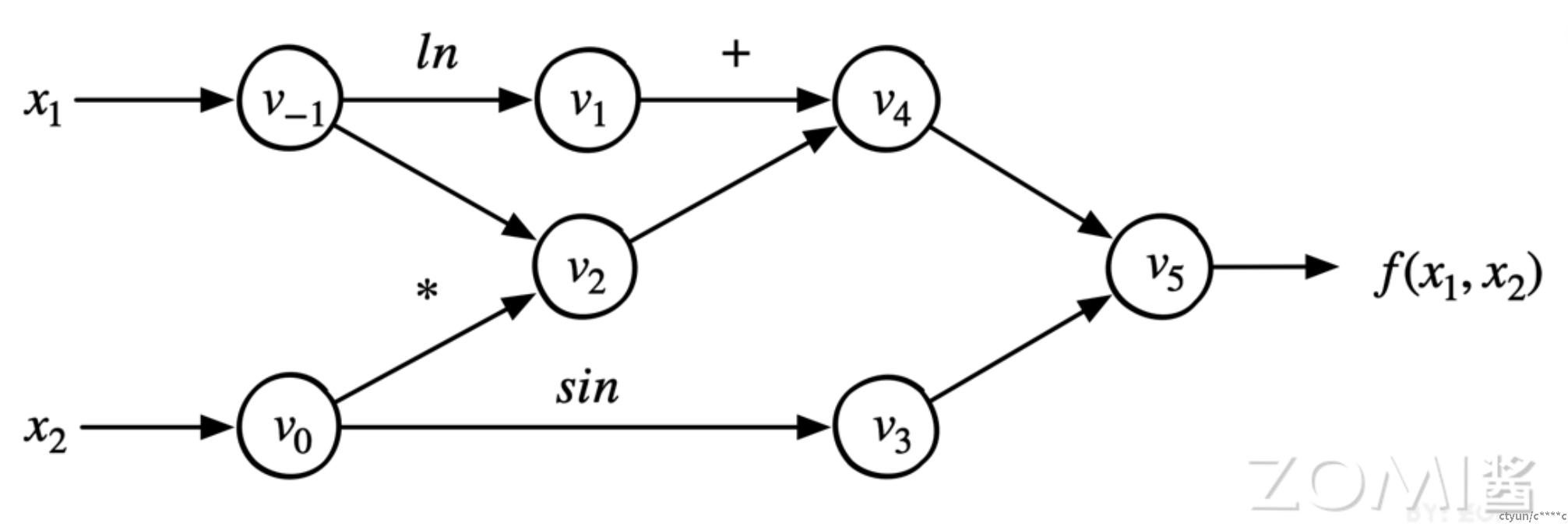
在 AI 框架中计算图的基本组成稍有不同,有两个主要的元素:1)基本数据结构张量和 2)基本计算单元算子。
-
基本数据结构张量:张量通过shape来表示张量的具体形状,决定在内存中的元素大小和元素组成的具体形状;其元素类型决定了内存中每个元素所占用的字节数和实际的内存空间大小
-
基本运算单元算子:具体在加速器 GPU/NPU 中执行运算的是由最基本的代数算子组成,另外还会根据深度学习结构组成复杂算子。每个算子接受的输入输出不同,如 Conv 算子接受 3 个输入 Tensor,1 个输出 Tensor
在 AI 框架中计算图节点代表 Operator 具体的计算操作(即算子),边代表 Tensor 张量。整个计算图能够有效地表达神经网络模型的计算逻辑和状态。
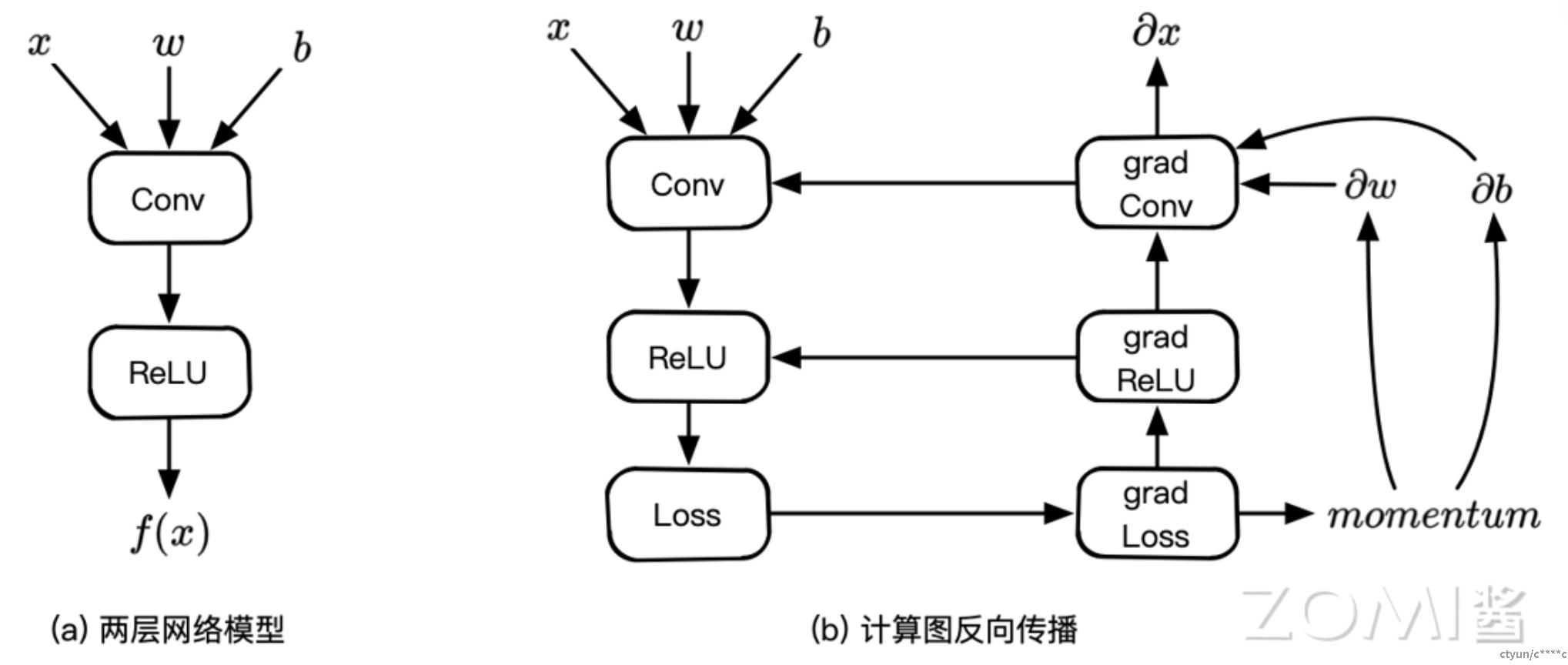
以一个卷积、一个激活的神经网络模型的正向和反向为例,其前向的计算公式为:
f(x)=ReLU(Conv(w,x,b))
反向计算微分的时候,需要加上损失函数:
Loss(x,x')=f(x)-x'
其在AI 框架中的计算图如下:
图优化基本方案
在推理引擎计算图的优化中,更多的是采用预先写好的模板,而不是通过 AI 编译去实现的。常见的推理引擎如 TensorIR、ONNX Runtime等,大部分都是基于已经预先写好的模板进行转换的,主要目的就是减少计算图中的冗余的计算。
因此衍生出了各种各样的图优化的技术。基于模板的方式,其缺点主要在于需要根据先验的知识来实现图的优化,相比于模型本身的复杂度而言注定是稀疏的,无法完全去除结构冗余。
基础优化,主要是对计算图进行一些基本的优化操作,这些操作主要保留了计算图的原有语义,亦即在优化过程中,不会改变计算图的基本结构和运算逻辑,只是在一定程度上提高了计算图的运行效率。基础优化主要包括以下几种:
- 常量折叠:主要用于处理计算图中的常量节点。在计算图中,如果有一些节点的值在编译时就已经确定了,那么这些节点就可以被称为常量节点。常量折叠就是在编译时就对这些常量节点进行计算,然后把计算结果存储起来,替换原来的常量节点,这样可以在运行时节省计算资源。
#Before optimization
x = 2, y = 3, z = x * y
#After constant folding
z = 6 - 冗余节点消除:在计算图中,可能会有一些冗余的节点,这些节点在运算过程中并没有起到任何作用,只是增加了计算的复杂度。冗余节点消除就是找出这些冗余节点,然后从计算图中移除它们,从而简化计算图的结构,提高运行效率。
#Before optimization
x = a + b, y = c + d, z = x
#After constant folding
z = a + b - 算子融合:算子融合是一种常用的图优化技术,它主要是将计算图中的多个运算节点融合为一个节点,从而减少运算节点的数量,提高运算效率。在基础优化中,算子融合通常只会融合有限数量的算子,以防止融合过多导致的运算复杂度增加。
#Before optimization
x = a + b, y = x * c
#After constant folding
y = (a + b) * c - 算子替换:如果可以找到一个等效但更高效的算子来完成相同的计算任务,就可以将原算子替换为这个更高效的算子。例如,将高精度的计算替换为低精度计算。
- 算子前移:如果有些算子的输入无关于程序的其它部分,那么这个算子可以前移执行,这样可以减少运行时的计算负担。
- 其他扩展优化:扩展优化主要是针对特定硬件进行优化的。不同的硬件设备其架构和运行机制都有所不同,因此,相应的优化方式也会有所不同。扩展优化就是根据这些硬件设备的特性,采用一些特殊且复杂的kernel融合优化策略和方法,以提高计算图在这些设备上的运行效率。例如,对于支持并行计算的 CUDA 设备,可以通过算子融合的方式将多个独立的运算操作合并成一个操作,从而充分利用 CUDA 设备的并行计算能力。
常量折叠

冗余节点消除
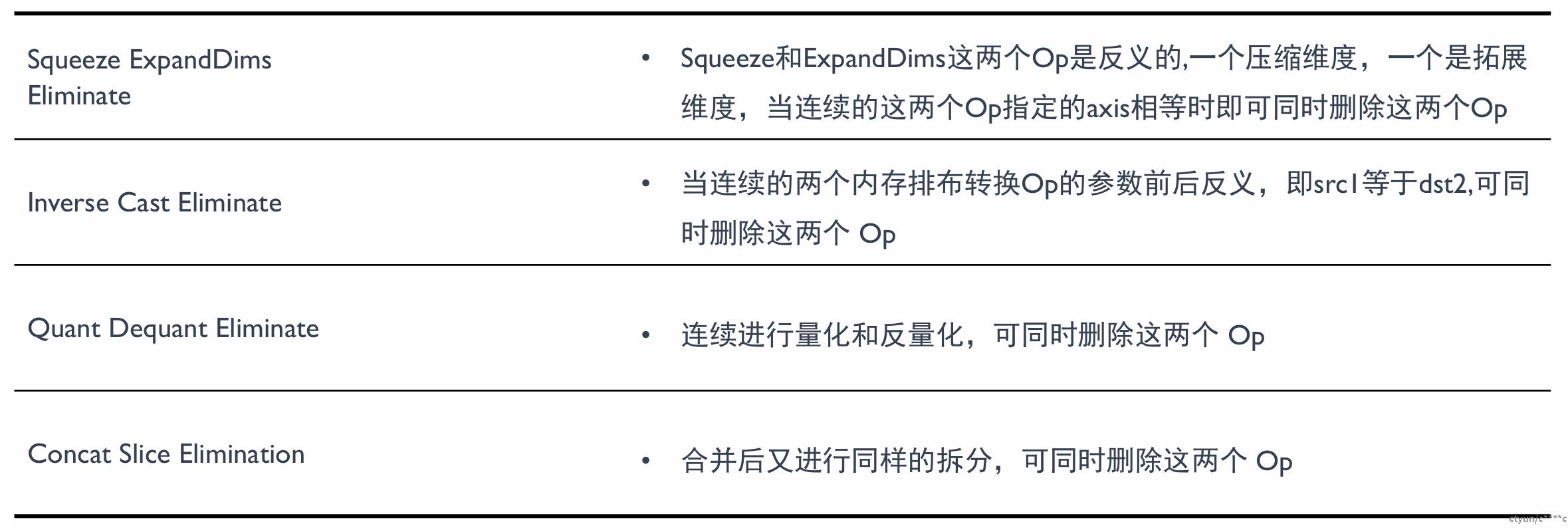
算子本身无意义(有些 Op 本身不参与计算,在推理阶段可以直接去掉对结果没有影响)

算子参数无意义(有些 Op 本身是有意义,但是设置成某些参数后就变成了无意义了的 Op)

算子位置无意义(一些 Op 在计算图中特殊位置会变得多余无意义)


算子前后反义(前后两个相邻 Op 进行操作时,语义相反的两个 Op 都可以删除)
公共子图

算子融合
算子融合(Operator Fusion)是深度学习中一种常见的优化技术,主要用于减少 GPU 内存访问,从而提高模型的执行效率。在神经网络模型中,一个模型通常由多个算子(例如卷积、激活函数、池化等)组成,这些算子的计算过程中会涉及到大量的数据的读取和写入。如果能将多个算子融合为一个复合算子,就可以减少内存访问次数,从而提高模型的运行效率。


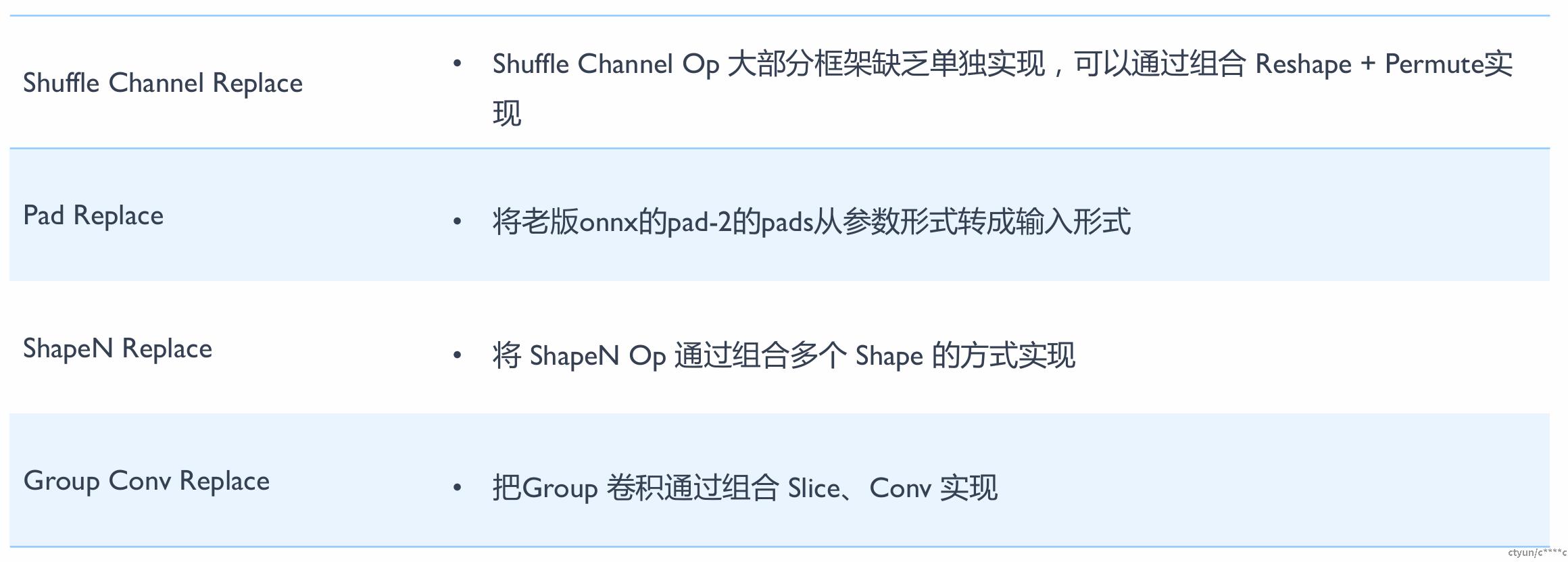
算子替换
算子替换(Operator Substitution)是一种神经网络模型优化技术,主要用于改善模型的计算效率和性能。这种技术是将模型中的某些算子替换为功能相同或相似,但计算效率更高或对特定硬件优化更好的算子。
算子替换需要保证替换后的模型在功能上与原模型尽可能接近,以保证模型的性能不会因为算子的替换而有所下降。算子替换的原理是通过合并同类项、提取公因式等数学方法,将算子的计算公式加以简化,并将简化后的计算公式映射到某类算子上。算子替换可以达到降低计算量、降低模型大小的效果。在实际应用中,算子替换通常与其他优化技术如算子融合等结合使用,以达到最佳的优化效果。

算子前移
在神经网络模型优化中,算子前移通常指的是将某些计算过程提前进行,以减少重复计算并提高模型的运行效率。
算子前移是一种常见的神经网络模型优化技术,它可以有效地减少计算量,提高模型的运行效率。然而,算子前移也需要考虑到模型的计算顺序和数据依赖性,不能随意地将计算过程提前。
Slice and Mul:移动slice算子到计算图前,减少冗余计算。
Bit shift and Reduce Sum:利用算术简化中的交换律,对计算的算子进行交换减少数据的传输和访存次数。

其他图优化