


背景
- 最近参与了一项算法服务重构的工作,该算法服务是基于大模型对投标文件的审核,该服务主要调用大模型、文本切分、词嵌入服务以及对象存储。
- 重构前服务(下称旧服务),主要对外提供一个任务运行接口,运行整个算法pipeline,pipeline中包含许多住Chunk的审核点,为了提高效率采用“并行审核点、并行Chunk审核的方式”,并行度却决于大模型的并发量,私有化部署时并发量基本不超过100。
- 重构后服务(下称新服务),将逐chunk的审核步骤拆解为同步接口,由调用方串联全流程pipeline和并发度。
并发问题
显然易见,新服务的并发量需求比旧服务大得多;同时审核接口的耗时可能较长,这是因为审核需要调用多次大模型,当chunk文本较长时,接口耗时可能要一分钟以上。
- Fastapi通过Python的协程异步io(
Ayncio)实现高并发,协程的调度依赖python的事件循环(EventLoop),当一个协程长时间阻塞当前线程事件循环时,基于协程的高并发将会失效。 - 旧服务基于Python的requests库请求大模型,requests在等待响应期间会阻塞
EventLoop。 - 因此,要并发大量耗时较长的审核接口,Fastapi需要开启大量woker,例如要达到60并发,则需要60个进程。
异步io和协程
- 显然,这个算法服务IO密集型的,异步io协程在这样的场景能发挥很大的作用,能提高fastapi服务的并发量。
- Python的
Asyncio具有传染性,“异步不彻底等于彻底不异步”有点夸张但是不无道理,那么该服务中所有的io都要使用异步库,对于cpu密集型的步骤还需要利用线程池或者进程池实现异步。 - 因此旧服务中涉及到io库的都需要替换为异步版本
| 用途 | 同步版本 | 异步版本 |
|---|---|---|
| http客户端 | requests | aiohttp |
| Minio客户端 | mino | miniopy-async |
| 文件操作 | 内置io库 | aiofiles |
如果还需要操作redis,可以使用redis>=6.2.0,这个版本同时包含异步和同步的redis客户端,其异步客户端导入如下
import redis.asyncio as redis
- 这些库的使用本文不做详细讨论。
- 基于
Asyncio完成并发http请求,真的非常丝滑,比起"requests库+多线程"要方便高效得多,毕竟协程的切换和空间开销远远小于线程。 - 下面是基于协程的异步io的例子:
import asyncio
import aiofiles
import aiohttp
async def save(data: bytes, path):
async with aiofiles.open(path, mode="wb") as f:
await f.write(data)
async def wget(url, path) -> bytes:
"""
下载文件,异步保存
"""
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
response.raise_for_status()
data: bytes = await response.read()
asyncio.create_task(save(data, path))
return data
async def main():
"""
并发下载多个文件
"""
result = await asyncio.gather(
wget("url1", "path1"),
wget("url2", "path2"),
wget("url3", "path3"),
wget("url4", "path4"),
)
print(len(result))
性能测试
- 选取其中一个算法步骤接口,该接口请求了大模型,耗时共秒
- 每轮80并发请求,持续100轮,请求全部成功,测试结果如下:
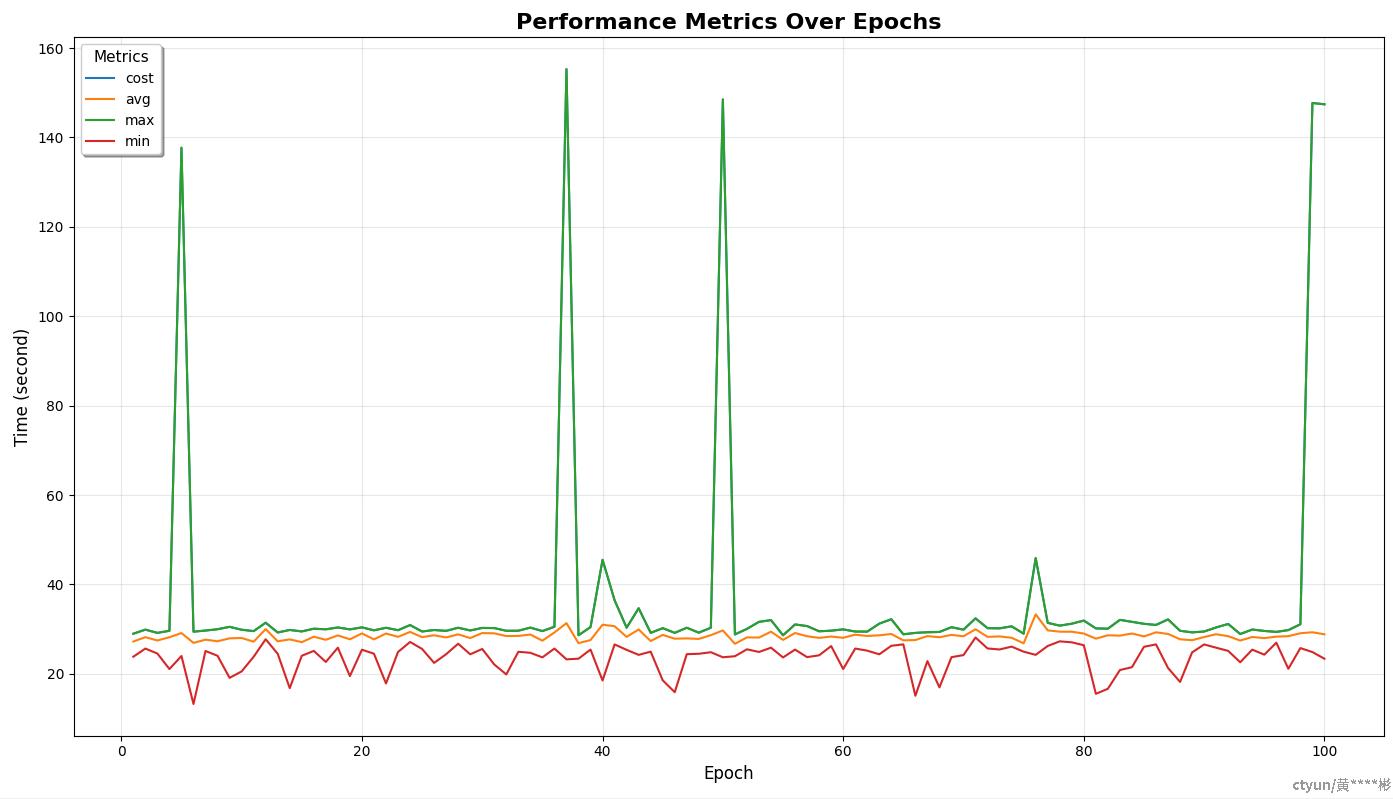
- 图中发现有接口耗时达到120秒以上,通过日志分支,原因是大模型服务无法响应导致请求超时导致(说明:算法同事不会因为单词大模型请求失败而认为整个审核接口失败),因此也看出,接口并发量如果继续加大,大模型服务可能将成为瓶颈
