


一、问题背景
dpvs(1.9.10) 部署在虚机环境中,使用的是宿主机 mellanox cx6 的 vf 网卡,做极端场景下的测试过程发现一个奇怪的 rss hash 抖动问题:打流的过程中,同时调用 rte_eth_dev_set_link_down / rte_eth_dev_set_link_up 操作修改 kni 接口状态,这期间一直可以收包,但是发现报文被送到了错误的核处理,导致长连接场景下出现连接异常。通过打日志发现,从down到up后会有几个包的mbuf->hash.rss是0或错误的值,之后稳定后会恢复正常,只有一开始的部分包 rss hash 值错误。另外,打开混杂模式的场景的会触发该问题,关闭混杂不会有此问题。使用 kni 接口不会有此问题,使用 virtio-user 接口会触发该问题。另外,pf 场景下不会有该问题(down/up 期间会断流),vf 场景下会出现此问题,现象非常奇怪。
二、问题分析
根据问题现象,反复排查代码发现问题,在 kni 初始化代码中发现一些蛛丝马迹:
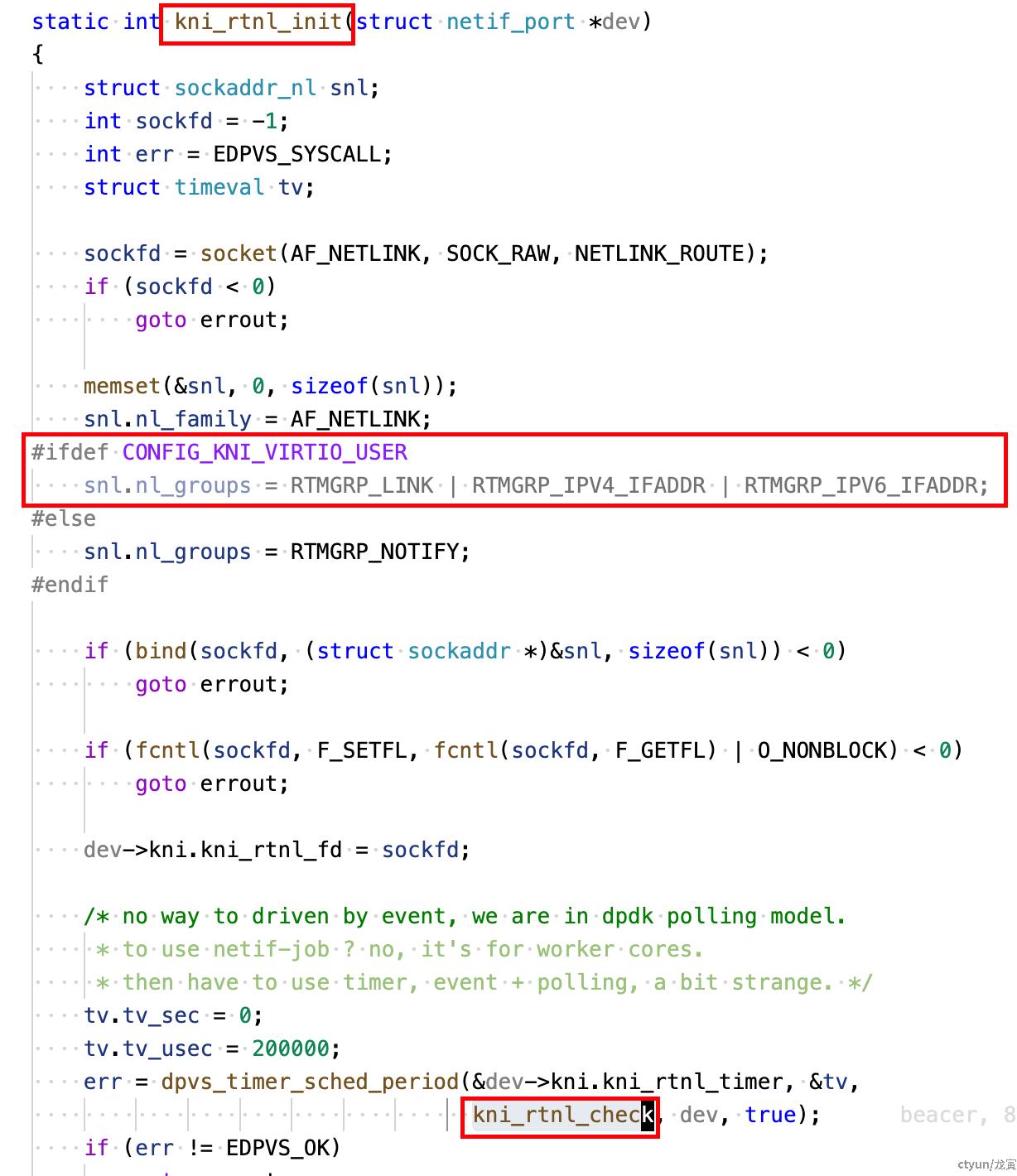
这个函数的职责是在给定的网口结构体(struct netif_port *dev)上建立并初始化一个 rtnetlink(路由/链路通知)套接字,然后把该套接字交给模块的轮询/定时器机制去定期检查和处理内核发来的网络事件(kni_rtnl_check)。
总体流程是:创建 AF_NETLINK/NETLINK_ROUTE 套接字 -> 配置要监听的组(nl_groups) -> bind 到本地 netlink 地址 -> 把套接字设置为非阻塞 -> 将文件描述符保存到 dev->kni.kni_rtnl_fd -> 用 dpvs_timer_sched_period 安排一个周期性定时器(200ms)去调用 kni_rtnl_check。
具体来说:snl.nl_groups 在有 CONFIG_KNI_VIRTIO_USER 时设置为 RTMGRP_LINK | RTMGRP_IPV4_IFADDR | RTMGRP_IPV6_IFADDR,这表示要接收链路变化和 IPv4/IPv6 地址变更事件;否则只注册 RTMGRP_NOTIFY(通知事件)。bind 操作把 socket 绑定到 netlink 地址,以便接收内核发来的消息。将套接字设置为非阻塞意味着随后通过定时器轮询读取时不会被阻塞。
通过执行 link down/up 操作之后,导致接口链路状态发生变化。dpvs 收到链路状态变化的事件之后会触发调用 kni_rtnl_check。通过查看 kni_rtnl_check 函数可以发现,该函数在收到链路状态变化的时间后会调用 kni_update_maddr 来更新 kni 设备的多播地址。
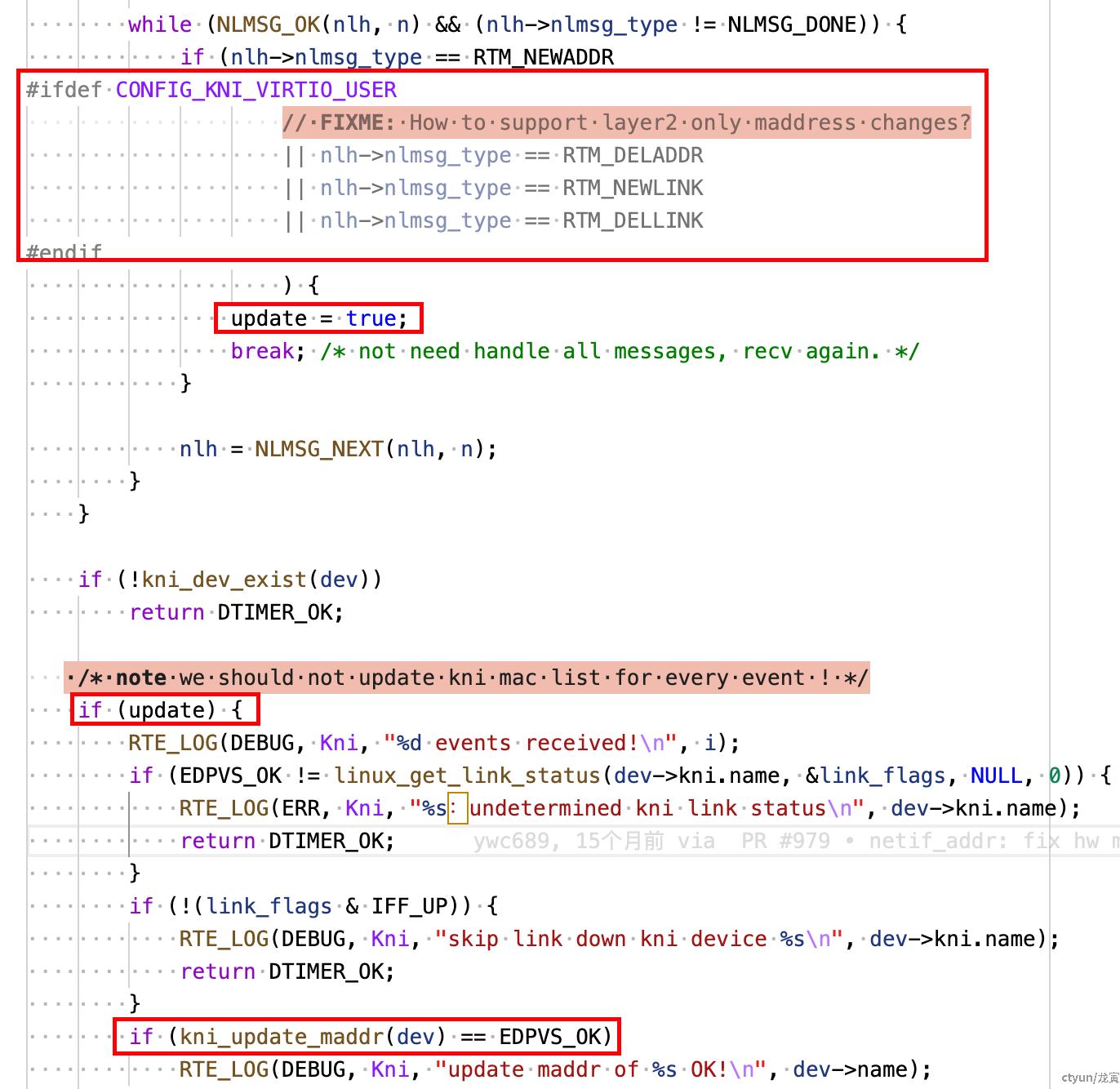
进一步分析代码 kni_update_maddr 代码,调用栈如下:
kni_update_maddr
-> kni_mc_list_cmp_set
-> __netif_set_mc_list
-> dev->netif_ops->op_set_mc_list
-> dpdk_set_mc_list
-> rte_eth_dev_set_mc_addr_list
-> dev->dev_ops->set_mc_addr_list
-> mlx5_set_mc_addr_list(针对 mellnaox 网卡)
最终会调用 mellanox 驱动注册的 mlx5_set_mc_addr_list 回调函数,如下所示:
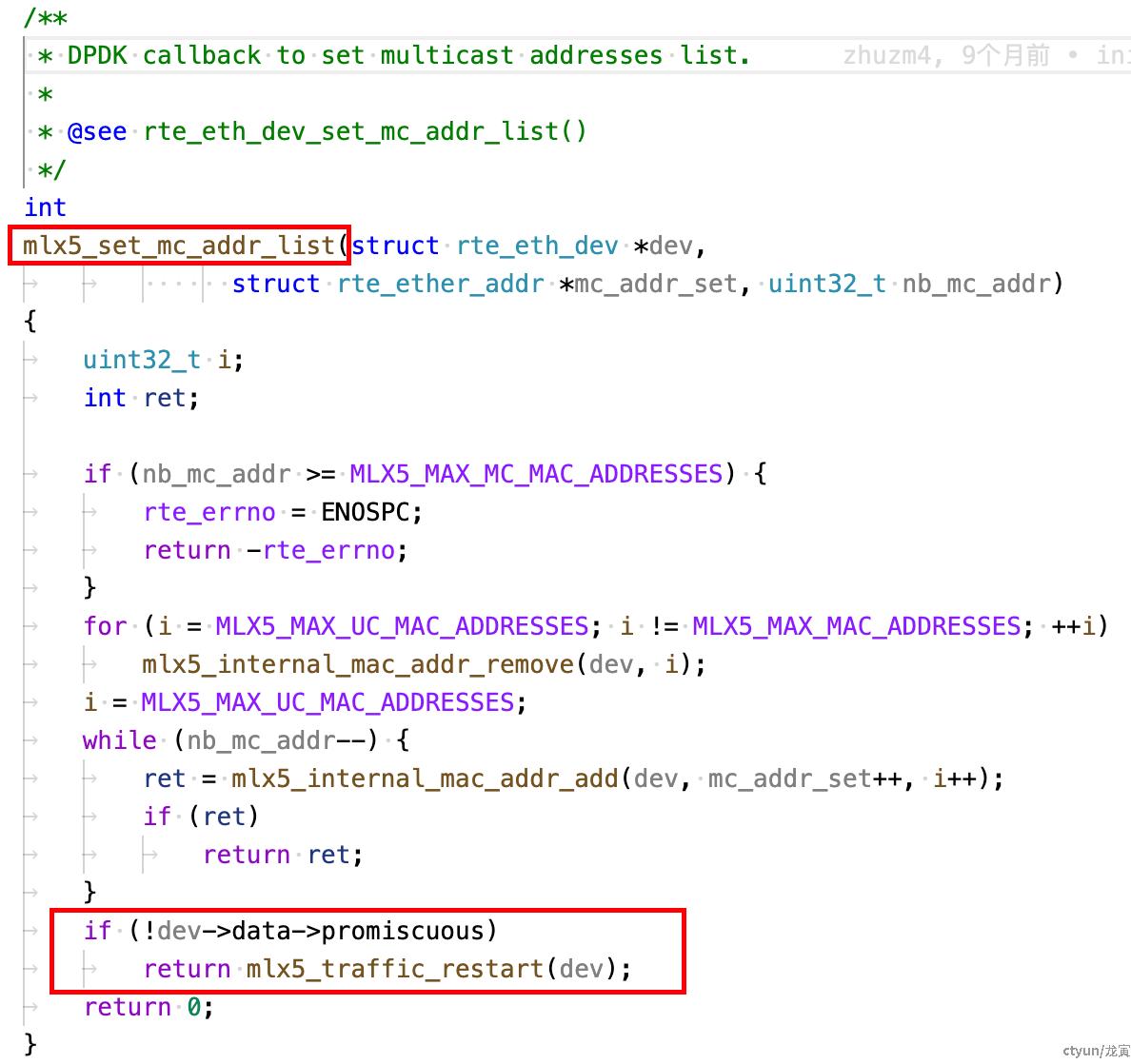
分析该函数可以看到:
关闭混杂的情况下,会调用 mlx5_traffic_restart,该函数会重置硬件默认规则(rss 配置也是以 flow 的形式下发到硬件),这就导致了,如果此时恰好 vf 口仍在收包,rss hash 就会受到影响。后面发现 dpdk 刷新组播地址,设置 mac 地址等,均是相同的处理逻(mlx5_set_mc_addr_list、mlx5_mac_addr_add、mlx5_mac_addr_remove 这些函数中都是这样的处理逻辑),如下所示:
三、分析结论
根据上面的分析,就可以完美解释上面的奇怪现象,总结如下:
(1)调用 rte_eth_dev_set_link_down / rte_eth_dev_set_link_up 操作修改 kni 接口状态,最终会触发调用接口更新 kni 设备的多播地址,更新的过程中,最终会调用 mlx5_traffic_restart 接口,该接口会重置 rss 配置,导致此时有流量过来的时候,rss hash 值出现短暂的错误问题;
(2)使用 kni 接口不会有此问题,使用 virtio-user 接口会触发该问题,这一点从 kni 初始化流程中也很好理解,使用 kni 接口的时候不会订阅链路状态的消息,不会有这种问题发生,只有使用 virtio-user 接口的场景下才会有这些处理逻辑。
(3)关闭混杂的情况下,会触发该问题,因为最终会调用到 mlx5_traffic_restart 接口。而打开混杂的场景下,不会调用 mlx5_traffic_restart 接口,自然不会触发该问题,这是代码本身的逻辑。
mlx 驱动的中的这段逻辑应该也是符合预期的:原因应该是 mlx 网卡驱动通过硬件流表来实现对 MAC/组播地址的精确过滤,所以当组播地址发生变更时,需要刷新硬件流表,以便只接收新的组播地址对应的数据包(规则中应该有匹配 mac或者组播地址的规则)。混杂模式开启的时候,硬件已经被配置为全收,所有包都能进来,不需要依赖流表去精确匹配 MAC/组播地址。组播地址的变化对流表没有影响,因为流表规则不会被用来过滤包,直接全收。
(4) 至于 pf 场景下不会有该问题(down/up 期间会断流),vf 场景下会出现此问题。这一点和 mlx 网卡本身相关,
查看 pf 配置,如下所示,可以看到这两个配置已经配置了 false。即软件层面 down 掉接口会触发硬件层面也 down 掉链路,这是针对 pf 的配置,vf 没有这类配置。所以软件层面进行 link-down 时,pf 层面会断流,但是 vf 层面不会断流。不断流此时就会有问题,导致重启过程中会重置硬件默认规则,此时 vf 恰好在收包时,就会有这样的情况出现。

