通用类
CDM有哪些优势?
| 优势项 | 用户自行开发 | CDM |
|---|---|---|
| 易使用 | 自行准备服务器资源,安装配置必要的软件并进行配置,等待时间长。 程序在读写两端会根据数据源类型,使用不同的访问接口,一般是数据源提供的对外接口,例如JDBC、原生API等,因此在开发脚本时需要依赖大量的库、SDK等,开发管理成本较高。 | CDM提供了Web化的管理控制台,通过Web页实时开通服务。 用户只需要通过可视化界面对数据源和迁移任务进行配置,服务会对数据源和任务进行全面的管理和维护,用户只需关注数据迁移的具体逻辑,而不用关心环境等问题,极大降低了开发维护成本。 CDM还提供了REST API,支持第三方系统调用和集成。 |
| 实时监控 | 需要自行选型开发。 | 您可以使用云监控服务监控您的CDM集群,执行自动实时监控、告警和通知操作,帮助您更好地了解CDM集群的各项性能指标。 |
| 免运维 | 需要自行开发完善运维功能,自行保证系统可用性,尤其是告警及通知功能,否则只能人工值守。 | 使用CDM服务,用户不需要维护服务器、虚拟机等资源。CDM的日志,监控和告警功能,有异常可以及时通知相关人员,避免7*24小时人工值守。 |
| 高效率 | 在迁移过程中,数据读写过程都是由一个单一任务完成的,受限于资源,整体性能较低,对于海量数据场景往往不能满足要求。 | CDM任务基于分布式计算框架,自动将任务切分为独立的子任务并行执行,能够极大提高数据迁移的效率。针对Hive、HBase、MySQL、DWS(数据仓库服务)数据源,使用高效的数据导入接口导入数据。 |
| 多种数据源支持 | 数据源类型繁杂,针对不同数据源开发不同的任务,脚本数量成千上万。 | 支持数据库、Hadoop、NoSQL、数据仓库、文件等多种类型的数据源。 |
| 多种网络环境支持 | 随着云计算技术的发展,用户数据可能存在于各种环境中,例如公有云、自建/托管IDC、混合场景等。在异构环境中进行数据迁移需要考虑网络连通性等因素,给开发和维护都带来较大难度。 | 无论数据是在用户本地自建的IDC中(Internet Data Center,互联网数据中心)、云服务中、第三方云中,或者使用ECS自建的数据库或文件系统中,CDM均可帮助用户轻松应对各种数据迁移场景,包括数据上云,云上数据交换,以及云上数据回流本地业务系统。 |
CDM有哪些安全防护?
CDM是一个完全托管的服务,提供了以下安全防护能力保护用户数据安全。
实例隔离:CDM服务的用户只能使用自己创建的实例,实例和实例之间是相互隔离的,不可相互访问。
系统加固:CDM实例的操作系统进行了特别的安全加固,攻击者无法从Internet访问CDM实例的操作系统。
密钥加密:用户在CDM上创建连接输入的各种数据源的密钥,CDM均采用高强度加密算法保存在CDM数据库。
无中间存储:数据在迁移的过程中,CDM只处理数据映射和转换,而不会存储任何用户数据或片段。
如何降低CDM使用成本?
如果是迁移公网的数据上云,可以使用NAT网关服务,实现CDM服务与子网中的其他弹性云主机共享弹性IP,可以更经济、更方便的通过Internet迁移本地数据中心或第三方云上的数据。
具体操作如下:
假设已经创建好了CDM集群(无需为CDM集群绑定专用弹性IP),记录下CDM集群所在的VPC和子网。
创建NAT网关,注意选择和CDM集群相同的VPC、子网。
创建完NAT网关后,回到NAT网关控制台列表,单击创建好的网关名称,然后选择“添加SNAT规则”。
选择子网和弹性IP,如果没有弹性IP,需要先申请一个。
完成之后,就可以到CDM控制台,通过Internet迁移公网的数据上云了。例如:迁移本地数据中心FTP服务器上的文件到OBS、迁移第三方云上关系型数据库到云服务RDS。
说明如果用户对本地数据源的访问通道做了SSL加密,则CDM无法通过弹性IP连接数据源。
CDM集群是否支持升级操作?
不支持。
CDM集群目前暂不支持升级操作,如果需要使用高版本集群则需要重新创建。
CDM迁移性能如何?
单个cdm.large规格实例理论上可以支持1TB~8TB/天的数据迁移。
但在实际使用中,实际传输速率受公网带宽、集群规格、文件读写速度、作业并发数设置、磁盘读写性能等因素影响。
CDM不同集群规格对应并发的作业数是多少?
CDM不同集群规格对应并发的作业数如表下表所示。
| 产品规格 | cdm.large | cdm.xlarge | cdm.4xlarge |
|---|---|---|---|
| 规格 | 节点数量:1个 vCPUs/内存:8核16GB 基准/最大带宽:0.8/3Gbit/s | 节点数量:1个 vCPUs/内存:16核32GB 基准/最大带宽:4/10Gbit/s | 节点数量:1个 vCPUs/内存:64核128GB 基准/最大带宽:36/40Gbit/s |
| 并发执行的作业数 | 30 | 100 | 300 |
包含但不限于以下情况,建议使用多个CDM集群进行业务分流:
作为不同的用途,例如用于数据迁移作业,或作为DataArts Studio管理中心连接代理。
给不同的业务部门使用,例如财务、网上商城等。
功能类
是否支持增量迁移?
CDM支持增量数据迁移。利用定时任务配置和时间宏变量函数等参数,可支持以下场景的增量数据迁移:
文件增量迁移
关系数据库增量迁移
使用时间宏变量完成增量同步
HBase/CloudTable增量迁移
是否支持字段转换?
支持,CDM支持以下字段转换器:
脱敏
去前后空格
字符串反转
字符串替换
表达式转换
在创建表/文件迁移作业的字段映射界面,可新建字段转换器,如图下图所示。
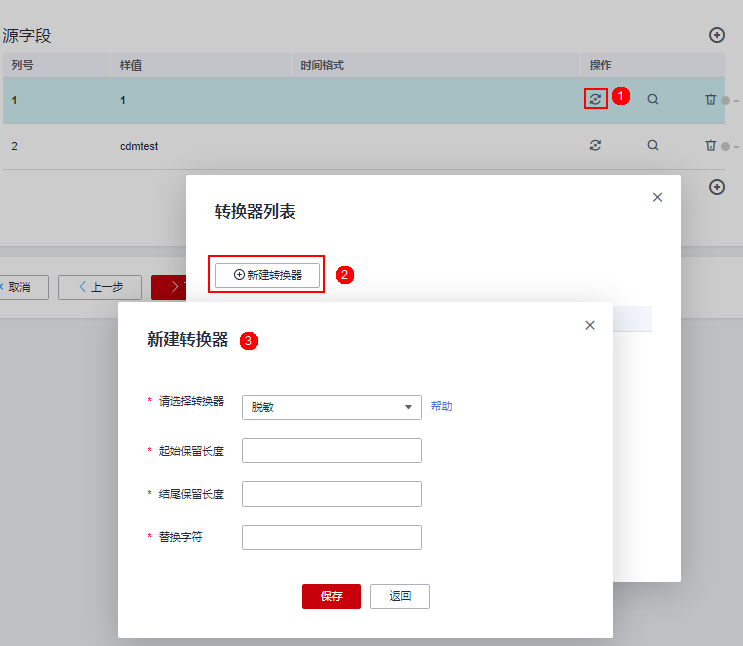
脱敏
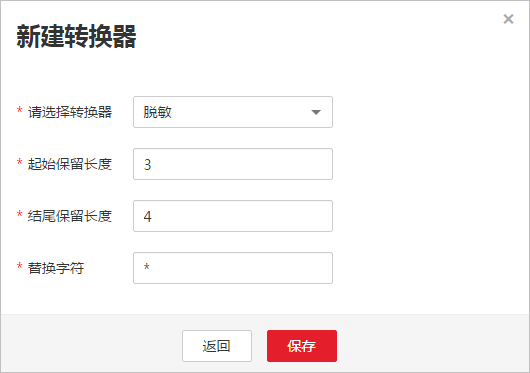
隐藏字符串中的关键信息,例如要将“12345678910”转换为“123***8910”,则配置如下:
“起始保留长度”为“3”。
“结尾保留长度”为“4”。
“替换字符”为“”。
如下图“字段脱敏”:
去前后空格
自动去字符串前后的空值,不需要配置参数。
字符串反转
自动反转字符串,例如将“ABC”转换为“CBA”,不需要配置参数。
字符串替换
替换字符串,需要用户配置被替换的对象,以及替换后的值。
表达式转换
使用JSP表达式语言(Expression Language)对当前字段或整行数据进行转换。JSP表达式语言可以用来创建算术和逻辑表达式。在表达式内可以使用整型数,浮点数,字符串,常量true、false和null。
表达式支持以下两个环境变量:
value:当前字段值。
row:当前行,数组类型。
表达式支持以下工具类:
StringUtils:字符串处理类,参考Java SDK代码的包结构“org.apache.commons.lang.StringUtils”。
DateUtils:日期工具类。
CommonUtils:公共工具类。
NumberUtils:字符串转数值类。
HttpsUtils:读取网络文件类。
应用举例:
如果当前字段为字符串类型,将字符串全部转换为小写,例如将“aBC”转换为“abc”。
表达式:StringUtils.lowerCase(value)将当前字段的字符串全部转为大写。
表达式:StringUtils.upperCase(value)如果当前字段值为“yyyy-MM-dd”格式的日期字符串,需要截取年,例如字段值为“2017-12-01”,转换后为“2017”。
表达式:StringUtils.substringBefore(value,"-")如果当前字段值为数值类型,转换后值为当前值的两倍。
表达式:value*2如果当前字段值为“true”,转换后为“Y”,其它值则转换后为“N”。
表达式:value=="true"?"Y":"N"如果当前字段值为字符串类型,当为空时,转换为“Default”,否则不转换。
表达式:empty value? "Default":value如果想将日期字段格式从“2018/01/05 15:15:05”转换为“2018-01-05 15:15:05”。
表达式:DateUtils.format(DateUtils.parseDate(value,"yyyy/MM/dd HH:mm:ss"),"yyyy-MM-dd HH:mm:ss")获取一个36位的UUID(Universally Unique Identifier,通用唯一识别码)。
表达式:CommonUtils.randomUUID()如果当前字段值为字符串类型,将首字母转换为大写,例如将“cat”转换为“Cat”。
表达式:StringUtils.capitalize(value)如果当前字段值为字符串类型,将首字母转换为小写,例如将“Cat”转换为“cat”。
表达式:StringUtils.uncapitalize(value)如果当前字段值为字符串类型,使用空格填充为指定长度,并且将字符串居中,当字符串长度不小于指定长度时不转换,例如将“ab”转换为长度为4的“ab”。
表达式:StringUtils.center(value,4)删除字符串末尾的一个换行符(包括“\n”、“\r”或者“\r\n”),例如将“abc\r\n\r\n”转换为“abc\r\n”。
表达式:StringUtils.chomp(value)如果字符串中包含指定的字符串,则返回布尔值true,否则返回false。例如“abc”中包含“a”,则返回true。
表达式:StringUtils.contains(value,"a")如果字符串中包含指定字符串的任一字符,则返回布尔值true,否则返回false。例如“zzabyycdxx”中包含“z”或“a”任意一个,则返回true。
表达式:StringUtils.containsAny("value","za")如果字符串中不包含指定的所有字符,则返回布尔值true,包含任意一个字符则返回false。例如“abz”中包含“xyz”里的任意一个字符,则返回false。
表达式:StringUtils.containsNone(value,"xyz")如果当前字符串只包含指定字符串中的字符,则返回布尔值true,包含任意一个其它字符则返回false。例如“abab”只包含“abc”中的字符,则返回true。
表达式:StringUtils.containsOnly(value,"abc")如果字符串为空或null,则转换为指定的字符串,否则不转换。例如将空字符转换为null。
表达式:StringUtils.defaultIfEmpty(value,null)如果字符串以指定的后缀结尾(包括大小写),则返回布尔值true,否则返回false。例如“abcdef”后缀不为null,则返回false。
表达式:StringUtils.endsWith(value,null)如果字符串和指定的字符串完全一样(包括大小写),则返回布尔值true,否则返回false。例如比较字符串“abc”和“ABC”,则返回false。
表达式:StringUtils.equals(value,"ABC")从字符串中获取指定字符串的第一个索引,没有则返回整数-1。例如从“aabaabaa”中获取“ab”的第一个索引1。
表达式:StringUtils.indexOf(value,"ab")从字符串中获取指定字符串的最后一个索引,没有则返回整数-1。例如从“aFkyk”中获取“k”的最后一个索引4。
表达式:StringUtils.lastIndexOf(value,"k")从字符串中指定的位置往后查找,获取指定字符串的第一个索引,没有则转换为“-1”。例如“aabaabaa”中索引3的后面,第一个“b”的索引是5。
表达式:StringUtils.indexOf(value,"b",3)从字符串获取指定字符串中任一字符的第一个索引,没有则返回整数-1。例如从“zzabyycdxx”中获取“z”或“a”的第一个索引0。
表达式:StringUtils.indexOfAny(value,"za")如果字符串仅包含Unicode字符,返回布尔值true,否则返回false。例如“ab2c”中包含非Unicode字符,返回false。
表达式:StringUtils.isAlpha(value)如果字符串仅包含Unicode字符或数字,返回布尔值true,否则返回false。例如“ab2c”中仅包含Unicode字符和数字,返回true。
表达式:StringUtils.isAlphanumeric(value)如果字符串仅包含Unicode字符、数字或空格,返回布尔值true,否则返回false。例如“ab2c”中仅包含Unicode字符和数字,返回true。
表达式:StringUtils.isAlphanumericSpace(value)如果字符串仅包含Unicode字符或空格,返回布尔值true,否则返回false。例如“ab2c”中包含Unicode字符和数字,返回false。
表达式:StringUtils.isAlphaSpace(value)如果字符串仅包含ASCII可打印字符,返回布尔值true,否则返回false。例如“!ab-c~”返回true。
表达式:StringUtils.isAsciiPrintable(value)如果字符串为空或null,返回布尔值true,否则返回false。
表达式:StringUtils.isEmpty(value)如果字符串中仅包含Unicode数字,返回布尔值true,否则返回false。
表达式:StringUtils.isNumeric(value)获取字符串最左端的指定长度的字符,例如获取“abc”最左端的2位字符“ab”。
表达式:StringUtils.left(value,2)获取字符串最右端的指定长度的字符,例如获取“abc”最右端的2位字符“bc”。
表达式:StringUtils.right(value,2)将指定字符串拼接至当前字符串的左侧,需同时指定拼接后的字符串长度,如果当前字符串长度不小于指定长度,则不转换。例如将“yz”拼接到“bat”左侧,拼接后长度为8,则转换后为“yzyzybat”。
表达式:StringUtils.leftPad(value,8,"yz")将指定字符串拼接至当前字符串的右侧,需同时指定拼接后的字符串长度,如果当前字符串长度不小于指定长度,则不转换。例如将“yz”拼接到“bat”右侧,拼接后长度为8,则转换后为“batyzyzy”。
表达式:StringUtils.rightPad(value,8,"yz")如果当前字段为字符串类型,获取当前字符串的长度,如果该字符串为null,则返回0。
表达式:StringUtils.length(value)如果当前字段为字符串类型,删除其中所有的指定字符串,例如从“queued”中删除“ue”,转换后为“qd”。
表达式:StringUtils.remove(value,"ue")如果当前字段为字符串类型,移除当前字段末尾指定的子字符串。指定的子字符串若不在当前字段的末尾,则不转换,例如移除当前字段“www.ctyun.cn”后的“.cn”。
表达式:StringUtils.removeEnd(value,".com")如果当前字段为字符串类型,移除当前字段开头指定的子字符串。指定的子字符串若不在当前字段的开头,则不转换,例如移除当前字段“www.ctyun.cn”前的“www.”。
表达式:StringUtils.removeStart(value,"www.")如果当前字段为字符串类型,替换当前字段中所有的指定字符串,例如将“aba”中的“a”用“z”替换,转换后为“zbz”。
表达式:StringUtils.replace(value,"a","z")如果当前字段为字符串类型,一次替换字符串中的多个字符,例如将字符串“hello”中的“h”用“j”替换,“o”用“y”替换,转换后为“jelly”。
表达式:StringUtils.replaceChars(value,"ho","jy")如果字符串以指定的前缀开头(区分大小写),则返回布尔值true,否则返回false,例如当前字符串“abcdef”以“abc”开头,则返回true。
表达式:StringUtils.startsWith(value,"abc")如果当前字段为字符串类型,去除字段中所有指定的字符,例如去除“abcyx”中所有的“x”、“y”和“z”,转换后为“abc”。
表达式:StringUtils.strip(value,"xyz")如果当前字段为字符串类型,去除字段末尾所有指定的字符,例如去除当前字段末尾的所有空格。
表达式:StringUtils.stripEnd(value,null)如果当前字段为字符串类型,去除字段开头所有指定的字符,例如去除当前字段开头的所有空格。
表达式:StringUtils.stripStart(value,null)如果当前字段为字符串类型,获取字符串指定位置后(不包括指定位置的字符)的子字符串,指定位置如果为负数,则从末尾往前计算位置。例如获取“abcde”第2个字符后的字符串,则转换后为“cde”。
表达式:StringUtils.substring(value,2)如果当前字段为字符串类型,获取字符串指定区间的子字符串,区间位置如果为负数,则从末尾往前计算位置。例如获取“abcde”第2个字符后、第5个字符前的字符串,则转换后为“cd”。
表达式:StringUtils.substring(value,2,5)如果当前字段为字符串类型,获取当前字段里第一个指定字符后的子字符串。例如获取“abcba”中第一个“b”之后的子字符串,转换后为“cba”。
表达式:StringUtils.substringAfter(value,"b")如果当前字段为字符串类型,获取当前字段里最后一个指定字符后的子字符串。例如获取“abcba”中最后一个“b”之后的子字符串,转换后为“a”。
表达式:StringUtils.substringAfterLast(value,"b")如果当前字段为字符串类型,获取当前字段里第一个指定字符前的子字符串。例如获取“abcba”中第一个“b”之前的子字符串,转换后为“a”。
表达式:StringUtils.substringBefore(value,"b")如果当前字段为字符串类型,获取当前字段里最后一个指定字符前的子字符串。例如获取“abcba”中最后一个“b”之前的子字符串,转换后为“abc”。
表达式:StringUtils.substringBeforeLast(value,"b")如果当前字段为字符串类型,获取嵌套在指定字符串之间的子字符串,没有匹配的则返回null。例如获取“tagabctag”中“tag”之间的子字符串,转换后为“abc”。
表达式:StringUtils.substringBetween(value,"tag")如果当前字段为字符串类型,删除当前字符串两端的控制字符(char≤32),例如删除字符串前后的空格。
表达式:StringUtils.trim(value)将当前字符串转换为字节,如果转换失败,则返回0。
表达式:NumberUtils.toByte(value)将当前字符串转换为字节,如果转换失败,则返回指定值,例如指定值配置为1。
表达式:NumberUtils.toByte(value,1)将当前字符串转换为Double数值,如果转换失败,则返回0.0d。
表达式:NumberUtils.toDouble(value)将当前字符串转换为Double数值,如果转换失败,则返回指定值,例如指定值配置为1.1d。
表达式:NumberUtils.toDouble(value,1.1d)将当前字符串转换为Float数值,如果转换失败,则返回0.0f。
表达式:NumberUtils.toFloat(value)将当前字符串转换为Float数值,如果转换失败,则返回指定值,例如配置指定值为1.1f。
表达式:NumberUtils.toFloat(value,1.1f)将当前字符串转换为Int数值,如果转换失败,则返回0。
表达式:NumberUtils.toInt(value)将当前字符串转换为Int数值,如果转换失败,则返回指定值,例如配置指定值为1。
表达式:NumberUtils.toInt(value,1)将字符串转换为Long数值,如果转换失败,则返回0。
表达式:NumberUtils.toLong(value)将当前字符串转换为Long数值,如果转换失败,则返回指定值,例如配置指定值为1L。
表达式:NumberUtils.toLong(value,1L)将字符串转换为Short数值,如果转换失败,则返回0。
表达式:NumberUtils.toShort(value)将当前字符串转换为Short数值,如果转换失败,则返回指定值,例如配置指定值为1。
表达式:NumberUtils.toShort(value,1)将当前IP字符串转换为Long数值,例如将“10.78.124.0”转换为LONG数值是“172915712”。
表达式:CommonUtils.ipToLong(value)从网络读取一个IP与物理地址映射文件,并存放到Map集合,这里的URL是IP与地址映射文件存放地址,例如“http://10.114.205.45:21203/sqoop/IpList.csv”。
表达式:HttpsUtils.downloadMap("url")将IP与地址映射对象缓存起来并指定一个key值用于检索,例如“ipList”。
表达式:CommonUtils.setCache("ipList",HttpsUtils.downloadMap("url"))取出缓存的IP与地址映射对象。
表达式:CommonUtils.getCache("ipList")判断是否有IP与地址映射缓存。
表达式:CommonUtils.cacheExists("ipList")根据指定的偏移类型(month/day/hour/minute/second)及偏移量(正数表示增加,负数表示减少),将指定格式的时间转换为一个新时间,例如将“2019-05-21 12:00:00”增加8个小时。
表达式:DateUtils.getCurrentTimeByZone("yyyy-MM-dd HH:mm:ss",value, "hour", 8)
Hadoop类型的数据源进行数据迁移时,建议使用的组件版本有哪些?
建议使用的组件版本既可以作为目的端使用,也可以作为源端使用详见下表。
Hadoop类型 组件 说明 MRS/Apache/FusionInsight HD
Hive
暂不支持2.x版本,建议使用的版本:
l 1.2.X
l 3.1.X
HDFS
建议使用的版本:
l 2.8.X
l 3.1.X
Hbase
建议使用的版本:
l 2.1.X
l 1.3.X
数据源为Hive时支持哪些数据格式?
云数据迁移服务支持从Hive数据源读写的数据格式包括SequenceFile、TextFile、ORC、Parquet。
如有疑问,请联系您的客户经理,或致电天翼云官方客服:400-810-9889。
是否支持同步作业到其他集群?
CDM虽然不支持直接在不同集群间迁移作业,但是通过批量导出、批量导入作业的功能,可以间接实现集群间的作业迁移,方法如下:
将CDM集群1中的所有作业批量导出,将作业的JSON文件保存到本地。
由于安全原因,CDM导出作业时没有导出连接密码,连接密码全部使用“Add password here”替换。在本地编辑JSON文件,将“Add password here”替换为对应连接的正确密码。
将编辑好的JSON文件批量导入到CDM集群2,实现集群1和集群2之间的作业同步。
是否支持批量创建作业?
CDM可以通过批量导入的功能,实现批量创建作业,方法如下:
手动创建一个作业。
导出作业,将作业的JSON文件保存到本地。
编辑JSON文件,参考该作业的配置,在JSON文件中批量复制出更多作业。
将JSON文件导入CDM集群,实现批量创建作业。
是否支持批量调度作业?
支持。
访问DataArts Studio服务的数据开发模块。
在数据开发主界面的左侧导航栏,选择“数据开发 > 作业开发”,新建作业。
拖动多个CDM Job节点至画布,然后再编排作业。
如何备份CDM作业?
可以,如果用户长时间不需要使用CDM集群,可以将CDM集群停掉或删除来降低成本。
删除前,用户可以先通过CDM的批量导出功能,把所有作业脚本保存到本地,仅在需要的时候再重新创建集群、重新导入作业,实现作业备份。
如果HANA集群只有部分节点和CDM集群网络互通,应该如何配置连接?
如果HANA集群只有部分节点和CDM网络互通,为确保CDM正常连接HANA集群,则需要进行如下配置:
关闭HANA集群的Statement Routing开关。但须注意,关闭Statement Routing,会增加配置节点的压力。
新建HANA连接时,在高级属性中添加属性“distribution”,并将值置为“off”。
完成配置后,CDM即可正常连接HANA集群。
如何使用Java调用CDM的Rest API创建数据迁移作业?
CDM提供了Rest API,可以通过程序调用实现自动化的作业创建或执行控制。
这里以CDM迁移MySQL数据库的表city1的数据到DWS的表city2为例,介绍如何使用Java调用CDM服务的REST API创建、启动、查询、删除该CDM作业。
需要提前准备以下数据:
云账号的用户名、账号名和项目ID。
创建一个CDM集群,并获取集群ID。
获取方法:在集群管理界面,单击CDM集群名称可查看集群ID,例如“c110beff-0f11-4e75-8b10-da7cd882b0ef”。
创建一个MySQL数据库和一个DWS数据库,并创建好表city1和表city2,创表语句如下:
MySQL: create table city1(code varchar(10),name varchar(32)); insert into city1 values('NY','New York'); DWS: create table city2(code varchar(10),name varchar(32));在CDM集群下,创建连接到MySQL的连接,例如连接名称为“mysqltestlink”。创建连接到DWS的连接,例如连接名称为“dwstestlink”。
运行下述代码,依赖HttpClient包,建议使用4.5版本。Maven配置如下:
<project> <modelVersion>4.0.0</modelVersion> <groupId>cdm</groupId> <artifactId>cdm-client</artifactId> <version>1</version> <dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5</version> </dependency> </dependencies> </project>
代码示例
使用Java调用CDM服务的REST API创建、启动、查询、删除CDM作业的代码示例如下:
package cdmclient;
import java.io.IOException;
import org.apache.http.Header;
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpDelete;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.methods.HttpPut;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class CdmClient {
private final static String DOMAIN_NAME="云账号名";
private final static String USER_NAME="云用户名";
private final static String USER_PASSWORD="云用户密码";
private final static String PROJECT_ID="项目ID";
private final static String CLUSTER_ID="CDM集群ID";
private final static String JOB_NAME="作业名称";
private final static String FROM_LINKNAME="源连接名称";
private final static String TO_LINKNAME="目的连接名称";
private final static String IAM_ENDPOINT="IAM的Endpoint";
private final static String CDM_ENDPOINT="CDM的Endpoint";
private CloseableHttpClient httpclient;
private String token;
public CdmClient() {
this.httpclient = createHttpClient();
this.token = login();
}
private CloseableHttpClient createHttpClient() {
CloseableHttpClient httpclient =HttpClients.createDefault();
return httpclient;
}
private String login(){
HttpPost httpPost = new HttpPost("https://"+IAM_ENDPOINT+"/v3/auth/tokens");
String json =
"{\r\n"+
"\"auth\": {\r\n"+
"\"identity\": {\r\n"+
"\"methods\": [\"password\"],\r\n"+
"\"password\": {\r\n"+
"\"user\": {\r\n"+
"\"name\": \""+USER_NAME+"\",\r\n"+
"\"password\": \""+USER_PASSWORD+"\",\r\n"+
"\"domain\": {\r\n"+
"\"name\": \""+DOMAIN_NAME+"\"\r\n"+
"}\r\n"+
"}\r\n"+
"}\r\n"+
"},\r\n"+
"\"scope\": {\r\n"+
"\"project\": {\r\n"+
"\"name\": \"PROJECT_NAME\"\r\n"+
"}\r\n"+
"}\r\n"+
"}\r\n"+
"}\r\n";
try {
StringEntity s = new StringEntity(json);
s.setContentEncoding("UTF-8");
s.setContentType("application/json");
httpPost.setEntity(s);
CloseableHttpResponse response = httpclient.execute(httpPost);
Header tokenHeader = response.getFirstHeader("X-Subject-Token");
String token = tokenHeader.getValue();
System.out.println("Login successful");
return token;
} catch (Exception e) {
throw new RuntimeException("login failed.", e);
}
}
/*创建作业*/
public void createJob(){
HttpPost httpPost = new HttpPost("https://"+CDM_ENDPOINT+"/cdm/v1.0/"+PROJECT_ID+"/clusters/"+CLUSTER_ID+"/cdm/job");
/**此处JSON信息比较复杂,可以先在作业管理界面上创建一个作业,然后单击作业后的“作业JSON定义”,复制其中的JSON内容,格式化为Java字符串语法,然后粘贴到此处。
*JSON消息体中一般只需要替换连接名、导入和导出的表名、导入导出表的字段列表、源表中用于分区的字段。**/
String json =
"{\r\n"+
"\"jobs\": [\r\n"+
"{\r\n"+
"\"from-connector-name\": \"generic-jdbc-connector\",\r\n"+
"\"name\": \""+JOB_NAME+"\",\r\n"+
"\"to-connector-name\": \"generic-jdbc-connector\",\r\n"+
"\"driver-config-values\": {\r\n"+
"\"configs\": [\r\n"+
"{\r\n"+
"\"inputs\": [\r\n"+
"{\r\n"+
"\"name\": \"throttlingConfig.numExtractors\",\r\n"+
"\"value\": \"1\"\r\n"+
"}\r\n"+
"],\r\n"+
"\"validators\": [],\r\n"+
"\"type\": \"JOB\",\r\n"+
"\"id\": 30,\r\n"+
"\"name\": \"throttlingConfig\"\r\n"+
"}\r\n"+
"]\r\n"+
"},\r\n"+
"\"from-link-name\": \""+FROM_LINKNAME+"\",\r\n"+
"\"from-config-values\": {\r\n"+
"\"configs\": [\r\n"+
"{\r\n"+
"\"inputs\": [\r\n"+
"{\r\n"+
"\"name\": \"fromJobConfig.schemaName\",\r\n"+
"\"value\": \"sqoop\"\r\n"+
"},\r\n"+
"{\r\n"+
"\"name\": \"fromJobConfig.tableName\",\r\n"+
"\"value\": \"city1\"\r\n"+
"},\r\n"+
"{\r\n"+
"\"name\": \"fromJobConfig.columnList\",\r\n"+
"\"value\": \"code&name\"\r\n"+
"},\r\n"+
"{\r\n"+
"\"name\": \"fromJobConfig.partitionColumn\",\r\n"+
"\"value\": \"code\"\r\n"+
"}\r\n"+
"],\r\n"+
"\"validators\": [],\r\n"+
"\"type\": \"JOB\",\r\n"+
"\"id\": 7,\r\n"+
"\"name\": \"fromJobConfig\"\r\n"+
"}\r\n"+
"]\r\n"+
"},\r\n"+
"\"to-link-name\": \""+TO_LINKNAME+"\",\r\n"+
"\"to-config-values\": {\r\n"+
"\"configs\": [\r\n"+
"{\r\n"+
"\"inputs\": [\r\n"+
"{\r\n"+
"\"name\": \"toJobConfig.schemaName\",\r\n"+
"\"value\": \"sqoop\"\r\n"+
"},\r\n"+
"{\r\n"+
"\"name\": \"toJobConfig.tableName\",\r\n"+
"\"value\": \"city2\"\r\n"+
"},\r\n"+
"{\r\n"+
"\"name\": \"toJobConfig.columnList\",\r\n"+
"\"value\": \"code&name\"\r\n"+
"}, \r\n"+
"{\r\n"+
"\"name\": \"toJobConfig.shouldClearTable\",\r\n"+
"\"value\": \"true\"\r\n"+
"}\r\n"+
"],\r\n"+
"\"validators\": [],\r\n"+
"\"type\": \"JOB\",\r\n"+
"\"id\": 9,\r\n"+
"\"name\": \"toJobConfig\"\r\n"+
"}\r\n"+
"]\r\n"+
"}\r\n"+
"}\r\n"+
"]\r\n"+
"}\r\n";
try {
StringEntity s = new StringEntity(json);
s.setContentEncoding("UTF-8");
s.setContentType("application/json");
httpPost.setEntity(s);
httpPost.addHeader("X-Auth-Token", this.token);
httpPost.addHeader("X-Language", "en-us");
CloseableHttpResponse response = httpclient.execute(httpPost);
int status = response.getStatusLine().getStatusCode();
if(status == 200){
System.out.println("Create job successful.");
}else{
System.out.println("Create job failed.");
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity));
}
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("Create job failed.", e);
}
}
/*启动作业*/
public void startJob(){
HttpPut httpPut = new HttpPut("https://"+CDM_ENDPOINT+"/cdm/v1.0/"+PROJECT_ID+"/clusters/"+CLUSTER_ID+"/cdm/job/"+JOB_NAME+"/start");
String json = "";
try {
StringEntity s = new StringEntity(json);
s.setContentEncoding("UTF-8");
s.setContentType("application/json");
httpPut.setEntity(s);
httpPut.addHeader("X-Auth-Token", this.token);
httpPut.addHeader("X-Language", "en-us");
CloseableHttpResponse response = httpclient.execute(httpPut);
int status = response.getStatusLine().getStatusCode();
if(status == 200){
System.out.println("Start job successful.");
}else{
System.out.println("Start job failed.");
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity));
}
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("Start job failed.", e);
}
}
/*循环查询作业运行状态,直到作业运行结束。*/
public void getJobStatus(){
HttpGet httpGet = new HttpGet("https://"+CDM_ENDPOINT+"/cdm/v1.0/"+PROJECT_ID+"/clusters/"+CLUSTER_ID+"/cdm/job/"+JOB_NAME+"/status");
try {
httpGet.addHeader("X-Auth-Token", this.token);
httpGet.addHeader("X-Language", "en-us");
boolean flag = true;
while(flag){
CloseableHttpResponse response = httpclient.execute(httpGet);
int status = response.getStatusLine().getStatusCode();
if(status == 200){
HttpEntity entity = response.getEntity();
String msg = EntityUtils.toString(entity);
if(msg.contains("\"status\":\"SUCCEEDED\"")){
System.out.println("Job succeeded");
break;
}else if (msg.contains("\"status\":\"FAILED\"")){
System.out.println("Job failed.");
break;
}else{
Thread.sleep(1000);
}
}else{
System.out.println("Get job status failed.");
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity));
break;
}
}
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("Get job status failed.", e);
}
}
/*删除作业*/
public void deleteJob(){
HttpDelete httpDelte = new HttpDelete("https://"+CDM_ENDPOINT+"/cdm/v1.0/"+PROJECT_ID+"/clusters/"+CLUSTER_ID+"/cdm/job/"+JOB_NAME);
try {
httpDelte.addHeader("X-Auth-Token", this.token);
httpDelte.addHeader("X-Language", "en-us");
CloseableHttpResponse response = httpclient.execute(httpDelte);
int status = response.getStatusLine().getStatusCode();
if(status == 200){
System.out.println("Delete job successful.");
}else{
System.out.println("Delete job failed.");
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity));
}
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("Delete job failed.", e);
}
}
/*关闭*/
public void close(){
try {
httpclient.close();
} catch (IOException e) {
throw new RuntimeException("Close failed.", e);
}
}
public static void main(String[] args){
CdmClient cdmClient = new CdmClient();
cdmClient.createJob();
cdmClient.startJob();
cdmClient.getJobStatus();
cdmClient.deleteJob();
cdmClient.close();
}
}如何将云下内网或第三方云上的私网与CDM连通?
很多企业会把关键数据源建设在内网,例如数据库、文件服务器等。由于CDM运行在云上,如果要通过CDM迁移内网数据到云上的话,可以通过以下几种方式连通内网和CDM的网络:
如果目标数据源为云下的数据库,则需要通过公网或者专线打通网络。通过公网互通时,需确保CDM集群已绑定EIP、CDM云上安全组出方向放通云下数据源所在的主机、数据源所在的主机可以访问公网且防火墙规则已开放连接端口。
在本地数据中心和云服务VPC之间建立VPN通道。
通过NAT(网络地址转换,Network
Address Translation)或端口转发,以代理的方式访问。
这里重点介绍如何通过端口转发工具来实现访问内部数据,流程如下:
找一台windows机器作为网关,该机器必须可以直接访问Internet,同时可以访问内网。
在该机器上安装端口映射工具(IPOP)。
通过端口映射工具(IPOP)配置端口映射。
说明长时间将内网数据库暴露在公网会有安全风险,迁移数据完成后,请及时停止端口映射。
场景描述
这里假设是将内网MySQL迁移到云服务DWS。
图中的内网既可以是企业自己的数据中心,也可以是在第三方云的虚拟数据中心私网。
如下图“网络拓扑样例”:
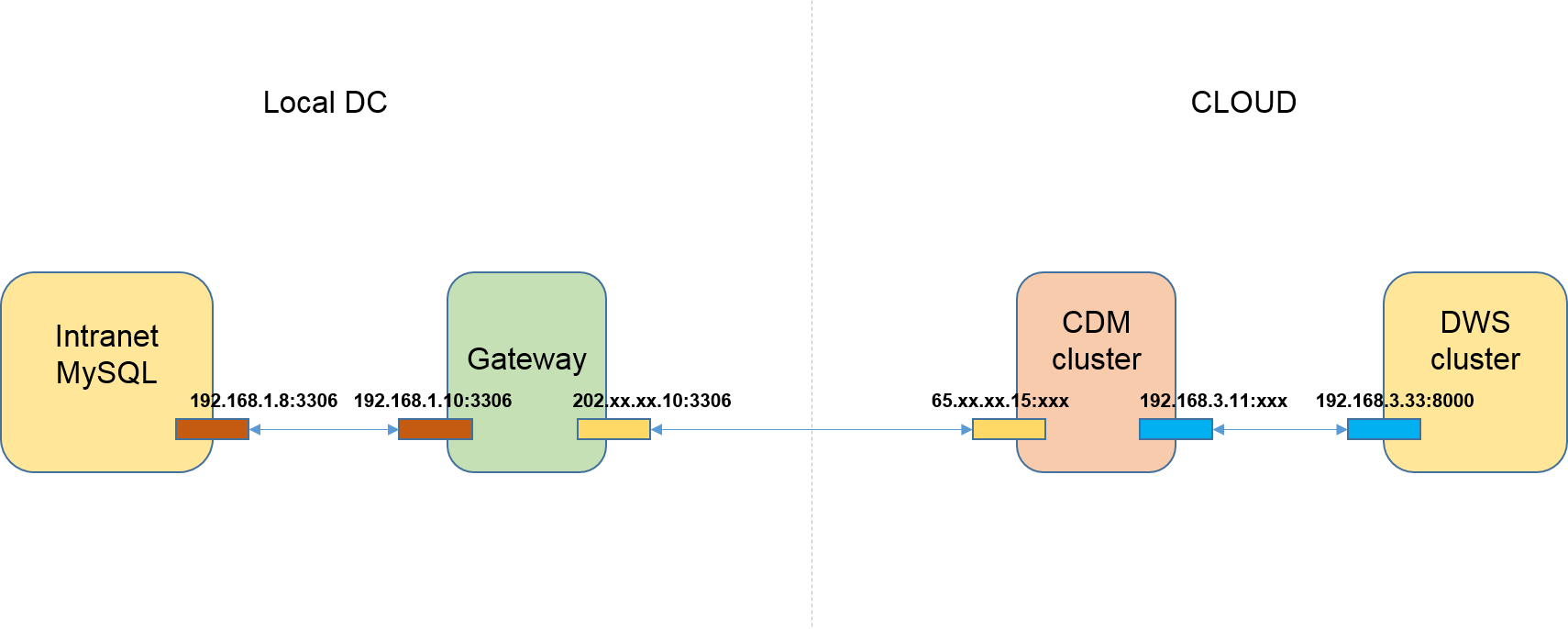
操作步骤
1.找一台Windows机器作为网关机,该机器同时配置内网和外网IP。通过以下测试来确保网关机器的服务要求:
a.在该机器上ping内网MySQL地址可以ping通,例如:ping 192.168.1.8。
b.在另外一台可上网的机器上ping网关机的公网地址可以ping通,例如ping 202.xx.xx.10。
2.下载端口映射工具IPOP,在网关机上安装IPOP。
3.运行端口映射工具,选择“端口映射”,如图下图配置端口映射所示。
本地地址、本地端口:配置为网关机的公网地址和端口(后续在CDM上创建MySQL连接时输入这个地址和端口)。
映射地址、映射端口:配置为内网MySQL的地址和端口。
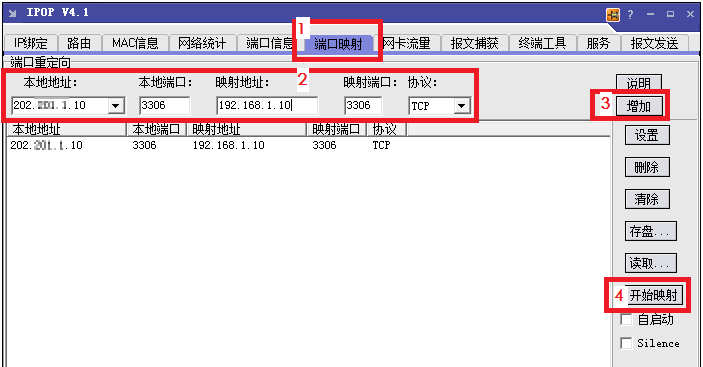
4.单击“增加”,添加端口映射关系。
5.单击“开始映射”,这时才会真正开始映射,接收数据包。
至此,就可以在CDM上通过弹性IP读取本地内网MySQL的数据,然后导入到云服务DWS中。
说明1. CDM要访问本地数据源,也必须给CDM集群配置EIP。
2. 一般云服务DWS默认也是只允许VPC内部访问,创建CDM集群时,必须将CDM的VPC与DWS配置一致,且推荐在同一个内网和安全组,如果不同,还需要配置允许两个安全组之间的数据访问。
3. 端口映射不仅可以用于迁移内网数据库的数据,还可以迁移例如SFTP服务器上的数据。
4. Linux机器也可以通过IPTABLE实现端口映射。
5. 内网中的FTP通过端口映射到公网时,需要检查是否启用了PASV模式。这种情况下客户端和服务端建立连接的时候是走的随机端口,所以除了配置21端口映射外,还需要配置PASV模式的端口范围映射,例如vsftp通过配置pasv_min_port和pasv_max_port指定端口范围。
CDM迁移作业的抽取并发数应该如何设置?
CDM迁移作业的抽取并发数,与集群规格和表大小有关。并发抽取数取值范围为1-300,若配置过大,则以队列的形式进行排队。
建议每1CUs(1CUs=1核4G)配置为4,如下表“抽取并发数参考配置”所示,您也可以根据实际情况进行调整。另外,每行数据大小为1MB以下的可以多并发抽取,超过1MB的建议单线程抽取数据。
说明l 迁移的目的端为文件时,CDM不支持多并发,此时应配置为单进程抽取数据。l 单作业的抽取并发数,受到作业“配置管理”中所配置的“最大抽取并发数”影响。“最大抽取并发数”配置的是抽取并发总数。
| CDM集群规格 | vCPUs/内存 | 抽取并发数参考配置 |
|---|---|---|
| cdm.large | 8核16GB | 16 |
| cdm.xlarge | 16核32GB | 32 |
| cdm.4xlarge | 64核128GB | 128 |
CDM是否支持动态数据实时迁移功能?
不支持。
如果源端在迁移过程中写数据,可能会出现报错。
故障处理类
问题描述
使用CDM从OBS导入数据到SQL Server时,作业运行失败,错误提示为:Unable to execute the SQL statement. Cause : 将截断字符串或二进制数据。
原因分析
用户OBS中的数据超出了SQL Server数据库的字段长度限制。
解决方法
在SQL Server数据库中建表时,将数据库字段改大,长度不能小于源端OBS中的数据长度。
Oracle迁移到DWS报错ORA-01555
问题现象
使用CDM迁移Oracle数据至DWS,报错图下图所示。
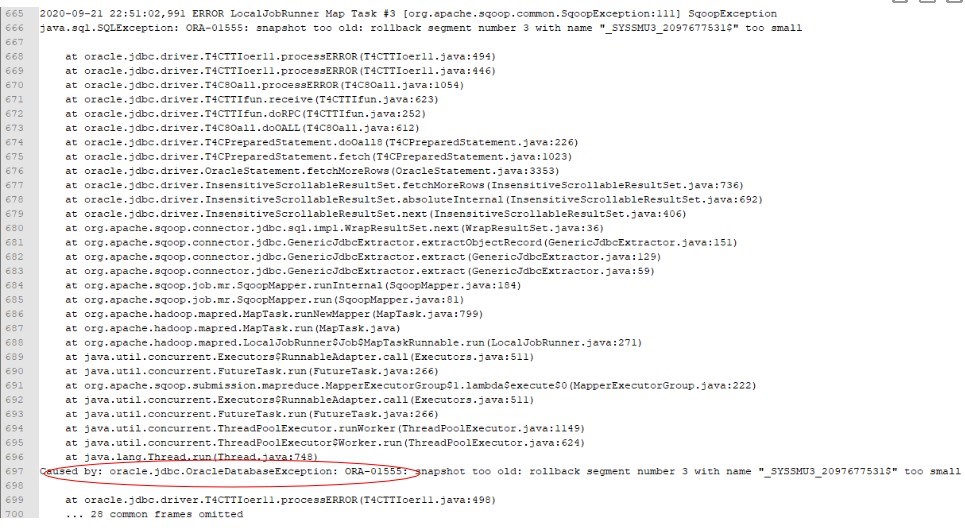
原因分析
数据迁移,整表查询且该表数据量大,那么查询时间较长。
查询过程中,其他用户频繁进行commit操作。
Oracel的RBS(rollbackspace 回滚时使用的表空间 )较小,造成迁移任务没有完成,源库已更新,回滚超时。
建议与总结
调小每次查询的数据量。
通过修改数据库配置调大Oracle的RBS。
MongoDB连接迁移失败时如何处理?
在默认情况下,userAdmin角色只具备对角色和用户的管理,不具备对库的读和写权限。
当用户选择MongoDB连接迁移失败时,用户需查看MongoDB连接中用户的权限信息,确保对指定库具备ReadWrite权限。
Hive迁移作业长时间卡住怎么办?
为避免Hive迁移作业长时间卡住,可手动停止迁移作业后,通过编辑Hive连接增加如下属性设置:
属性名称:hive.server2.idle.operation.timeout
值:10m
如下图所示

使用CDM迁移数据由于字段类型映射不匹配导致报错怎么处理?
问题描述
MySQL迁移时报错:Unable to connect to the database server. Cause: connect timed out.
原因分析
这种情况是由于表数据量较大,并且源端通过where语句过滤,但并非索引列,或列值不离散,查询会全表扫描,导致JDBC连接超时。例如图“非索引列”所示c_date字段为非索引列。
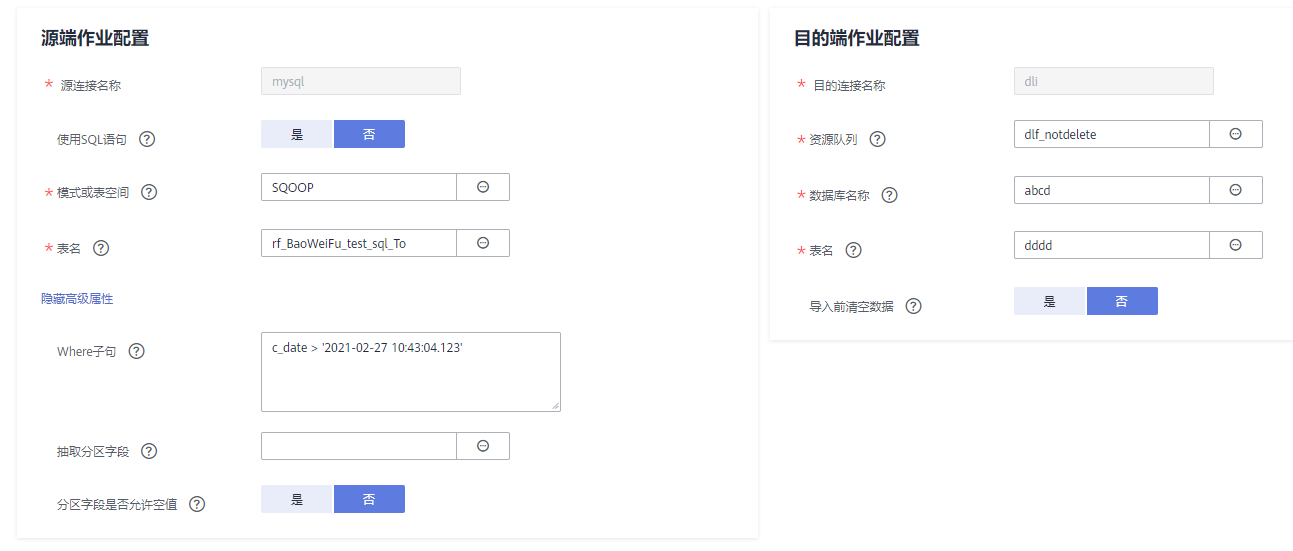
解决方案
优先联系DBA修改表结构,将需要过滤的列配置为索引列,然后重试。
如果由于数据不离散,导致还是失败请参考2~4,通过增大JDBC超时时间解决。根据作业找到对应的MySQL连接名称,查找连接信息。
如下图图连接信息
单击“连接管理”,在“操作”列中,单击“连接”进行编辑。
如下图连接

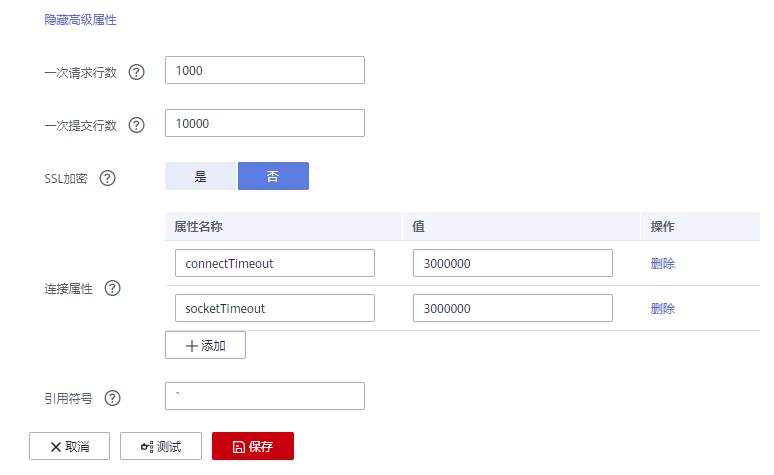
打开高级属性,在“连接属性”中建议新增“connectTimeout”与“socketTimeout”参数及参数值,单击“保存”。
如下图编辑高级属性:
创建了Hive到DWS类型的连接,进行CDM传输任务失败时如何处理?
建议清空历史数据后再次尝试该任务。在使用CDM迁移作业的时候需要配置清空历史数据,然后再做迁移,可大大降低任务失败的概率。
如何使用CDM服务将MySQL的数据导出成SQL文件,然后上传到OBS桶?
CDM服务暂不支持该操作。
建议通过手动导出MySQL的数据文件,然后在服务器上开启SFTP服务,然后新建CDM作业,源端是SFTP协议,目的端是OBS,将文件传过去。
如何处理CDM从OBS迁移数据到DLI出现迁移中断失败的问题?
此类作业问题表现为配置了脏数据写入,但并无脏数据。
这种情况下需要调低并发任务数,即可避免此类问题。
如何处理CDM连接器报错“配置项 [linkConfig.iamAuth] 不存在”?
此问题归因为:客户证书过期。
客户证书过期,需要完成更新证书操作,完成后重新配置连接器即可。
创建数据连接时报错“配置项[linkConfig.createBackendLinks]不存在”或创建作业时报错“配置项 [throttlingConfig.concurrentSubJobs] 不存在”怎么办?
当同时存在多个不同版本的集群,先在低版本CDM集群创建数据连接或保存作业时后,再进入高版本CDM集群时,会偶现此类故障。
需手动清理浏览器缓存,即可避免此类问题。
新建MRS Hive连接时,提示:CORE_0031:Connect time out. (Cdm.0523) 怎么解决?
新建MRS Hive连接时,提示无法下载配置文件,实际是用户权限不足。建议您新建一个业务用户,给对应的权限后重试即可。
如果要创建MRS安全集群的数据连接,不能使用admin用户。因为admin用户是默认的管理页面用户,这个用户无法作为安全集群的认证用户来使用。您可以创建一个新的MRS用户,然后在创建MRS数据连接时,“用户名”和“密码”填写为新建的MRS用户及其密码。
说明l 如果CDM集群为2.9.0版本及之后版本,且MRS集群为3.1.0及之后版本,则所创建的用户至少需具备Manager_viewer的角色权限才能在CDM创建连接;如果需要对MRS组件的库、表、列进行操作,还需要参考MRS文档添加对应组件的库、表、列操作权限。l 如果CDM集群为2.9.0之前的版本,或MRS集群为3.1.0之前的版本,则所创建的用户需要具备Manager_administrator或System_administrator权限,才能在CDM创建连接。l 仅具备Manager_tenant或Manager_auditor权限,无法创建连接。
迁移时已选择表不存在时自动创表,提示“CDM not support auto create empty table with no column”怎么处理?
这是由于数据库表名中含有特殊字符导致识别出语法错误,按数据库对象命名规则重新命名后恢复正常。
例如,DWS数据仓库中的数据表命名需要满足以下约束:长度不超过63个字符,以字母或下划线开头,中间字符可以是字母、数字、下划线、$、#。
创建Oracle关系型数据库迁移作业时,无法获取模式名怎么处理?
这是由于可能上传了暂不支持的最新ORACLE_8驱动(如Oracle Database 21c (21.3) drivers)。
解决此问题,推荐使用Oracle Database 12c中的ojdbc8.jar驱动。

