什么是Llama2
Meta在7月18日发布了可以免费用于学术研究或商业用途的Llama2开源大语言模型。
!
Llama的训练方法是先进行无监督预训练,再进行有监督微调,训练奖励模型,根据人类反馈进行强化学习。 Llama 2的训练数据比Llama 1多40%,用了2万亿个tokens进行训练,并且上下文长度是Llama 1的两倍。 目前提供7B 、13B、70B三种参数量的版本。

根据Meta公布的官方数据,Llama 2在许多基准测试上都优于其他开源语言模型,包括推理、编程、对话能力和知识测试,在帮助性、安全性方面甚至比部分闭源模型要好。

Llama 2-Chat在Llama 2的基础上针对聊天对话场景进行了微调和安全改进,使用 SFT (监督微调) 和 RLHF (人类反馈强化学习)进行迭代优化,以便更好的和人类偏好保持一致,提高安全性。
Llama 2-Chat更专注于聊天机器人领域,主要应用于以下几个方面:
客户服务:Llama 2-Chat可以用于在线客户服务,回答关于产品、服务的常见问题,并向用户提供帮助和支持。
社交娱乐:Llama 2-Chat可以作为一个有趣的聊天伙伴,与用户进行随意、轻松的对话,提供笑话、谜语、故事等娱乐内容,增加用户的娱乐体验。
个人助理:Llama 2-Chat可以回答一些日常生活中的问题,如天气查询、时间设置、提醒事项等,帮助用户解决简单的任务和提供一些实用的功能。
心理健康:Llama 2-Chat可以作为一个简单的心理健康支持工具,可以与用户进行交流,提供情绪调节、压力缓解的建议和技巧,为用户提供安慰和支持。
在GPU云主机上搭建模型运行环境
步骤一:创建1台未配置驱动的GPU云主机
进入创建云主机页面。
点击天翼云门户首页的“控制中心”,输入登录的用户名和密码,进入控制中心页面。
单击“服务列表>弹性云主机”,进入主机列表页。
单击“创建云主机”,进入弹性云主机创建页。
进行基础配置。
根据业务需求配置“计费模式”、“地域”、“企业项目”、“虚拟私有云”、“实例名称”、“主机名称”等。
选择规格。此处选择"CPU架构"为"X86"、"分类"为"GPU加速/AI加速型"、"规格族"为"GPU计算加速型p2v"、"规格"为"p2v.4xlarge.8"。
注意
大模型推理场景需要处理大量的数据和参数,对显卡显存和云盘大小都有一定要求。
针对显存,加载全精度Llama-7B-chat模型时,模型将消耗28G显存,除此之外也需要额外的显存用于存储中间激活和其他临时变量,因此,最低选择显存为32G的V100显卡。同时您也可以根据自身需求对模型进行量化,缩减模型大小,减少对显存的要求并提升计算速度。
针对系统盘,为了存储模型文件、相关依赖、输入数据以及中间结果,最好将系统盘大小配置为100GB以上。
选择镜像。此处选择ubuntu 20.04的基础镜像进行推理实践。
注意
为了演示模型搭建的整个过程,此处选择未配备任何驱动和工具包的ubuntu基础模型。详细创建步骤请参见创建未配备驱动的GPU云主机-GPU云主机-用户指南-创建GPU云主机 - 天翼云。
最终我们生成了预装llama2模型和模型依赖的大模型镜像,并在成都4进行了加载,如您有相关需要可在订购时直接选择该镜像——大模型镜像 LLaMA2-7B-Chat(100GB)。
设置云盘类型和大小。
网络及高级配置。设置网络,包括"网卡"、"安全组",同时配备'弹性IP'用于下载模型和相关依赖;设置高级配置,包括"登录方式"、"云主机组"、"用户数据"。
确认配置并支付。
步骤二:下载模型并上传
从魔乐社区、魔搭社区等国内大模型社区及平台下载Llama-2-7b-chat模型。下载完成后上传至GPU云主机/opt/llama路径下。
说明
如何将本地文件上传到Linux云主机请参考本地文件如何上传到Linux云主机。
步骤三:环境搭建
上传并安装GPU驱动 从Nvidia官网下载GPU驱动并上传至GPU云主机,按照如下步骤安装驱动。
# 对安装包添加执行权限 chmod +x NVIDIA-Linux-x86_64-515.105.01.run # 安装gcc和linux-kernel-headers sudo apt-get install gcc linux-kernel-headers # 运行驱动安装程序 sudo sh NVIDIA-Linux-x86_64-515.105.01.run --disable-nouveau # 查看驱动是否安装成功 nvidia-smi
安装Nvidia CUDA Toolkit组件。
wget http://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda_11.7.0_515.43.04_linux.run # 安装CUDA bash cuda_11.7.0_515.43.04_linux.run # 编辑环境变量文件 vi ~/.bashrc #在当前行下新开一行并插入 o # 增加环境变量 export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH # 按Esc 键退出插入模式并保存修改 :wq # 使环境变量生效 source ~/.bashrc # 查看是否安装成功 nvcc -V安装Miniconda。
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh # 安装Miniconda3 bash Miniconda3-latest-Linux-x86_64.sh # 配置conda环境变量 vim /etc/profile #在当前行下新开一行并插入 o # 添加环境变量 export ANACONDA_PATH=~/miniconda3 export PATH=$PATH:$ANACONDA_PATH/bin # 按Esc 键退出插入模式并保存修改 :wq # 使环境变量生效 source /etc/profile # 查看是否安装成功 which anaconda conda --version conda info -e source activate base python # 查看虚拟环境 conda env list
安装cuDNN。
从cudnn-download下载cuDNN压缩包并上传至GPU云主机,按照如下步骤进行安装。
# 解压 tar -xf cudnn-linux-x86_64-8.9.4.25_cuda11-archive.tar.xz # 进目录 cd cudnn-linux-x86_64-8.9.4.25_cuda11-archive # 复制文件到 CUDA 库目录 cp ./include/* /usr/local/cuda-11.7/include/ cp ./lib/libcudnn* /usr/local/cuda-11.7/lib64/ # 访问授权 chmod a+r /usr/local/cuda-11.7/include/* /usr/local/cuda-11.7/lib64/libcudnn* # 查看是否安装成功 cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 #返回根目录 cd
安装依赖。
下载Llama模型代码。
git clone https://github.com/facebookresearch/llama.git在线安装依赖。
# 创建python310版本环境 conda create --name python310 python=3.10 # 查看虚拟环境列表 conda env list # 激活python310环境 source activate python310 # 切换到llama目录 cd /opt/llama python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple # 下载依赖 pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple pip install numpy==1.23.1 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install torch==2.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install -U bitsandbytes -i https://pypi.tuna.tsinghua.edu.cn/simple # 下载peft git clone https://github.com/huggingface/peft.git # 传到离线服务器上切换分支,安装特定版本peft cd peft git checkout 13e53fc # 安装peft pip install . -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn注意
安装相关依赖的耗时较久请您耐心等待。
准备推理代码和启动脚本。
进入/opt/llama目录下。
cd /opt/llama下载推理代码。
访问github网站,下载推理代码inference_hf.py并上传至云主机。
新建启动脚本run.sh。
#新建空文件 vim run.sh #文件内新增如下内容 python inference_hf.py --base_model 7b-chat --tokenizer_path 7b-chat --with_prompt --gpus 0
步骤四:镜像打包
为了使您能更快的搭建模型运行环境,在完成步骤一和步骤二的操作后,我们对GPU云主机的系统盘进行了打包,生成了标准的GPU云主机镜像。目前已经上传至天翼云成都4、海口2资源池,您可直接对该镜像进行使用。
镜像打包步骤如下:
echo "nameserver 114.114.114.114" > /etc/resolv.conf
echo "localhost" > /etc/hostname
# 清除 machine-id。
yes | cp -f /dev/null /etc/machine-id
# 若有 /var/lib/dbus/machine-id,则:
# rm -f /var/lib/dbus/machine-id
# ln -s /etc/machine-id /var/lib/dbus/machine-id
cloud-init clean -l # 清理 cloud-init。若此命令不可用,则可尝试:rm -rf /var/lib/cloud
rm -f /tmp/*.log # 清除镜像脚本日志。
# 清理 /var/log 日志。
read -r -d '' script <<-"EOF"
import os
def clear_logs(base_path="/var/log"):
files = os.listdir(base_path)
for file in files:
file_path = os.path.join(base_path, file)
if os.path.isfile(file_path):
with open(file_path, "w") as f:
f.truncate()
elif os.path.isdir(file_path):
clear_logs(base_path=file_path)
if __name__ == "__main__":
clear_logs()
EOF
if [ -e /usr/bin/python ]; then
python -c "$script"
elif [ -e /usr/bin/python2 ]; then
python2 -c "$script"
elif [ -e /usr/bin/python3 ]; then
python3 -c "$script"
else
echo "### no python env in /usr/bin. clear_logs failed ! ###"
fi
# 清空历史记录。
rm -f /root/.python_history
rm -f /root/.bash_history
rm -f /root/.wget-hsts使用大模型镜像进行模型快速部署
步骤一:创建GPU云主机
登录天翼云控制台,进入弹性云主机主机订购页,选择计算加速型GPU云主机,在公共镜像中选择大模型镜像 LLaMA2-7B-Chat。
大模型镜像 LLaMA2-7B-Chat最低规格推荐:p2v.2xlarge.4 8vCPU 32GB内存 单张v100 GPU。
步骤二:在线推理
登录GPU云主机,根据如下步骤执行推理任务。
#进入/opt/llama目录并执行sh run.sh命令
cd /opt/llama && sh run.sh
#根据提示在 ”please input your question :” 后输入推理问题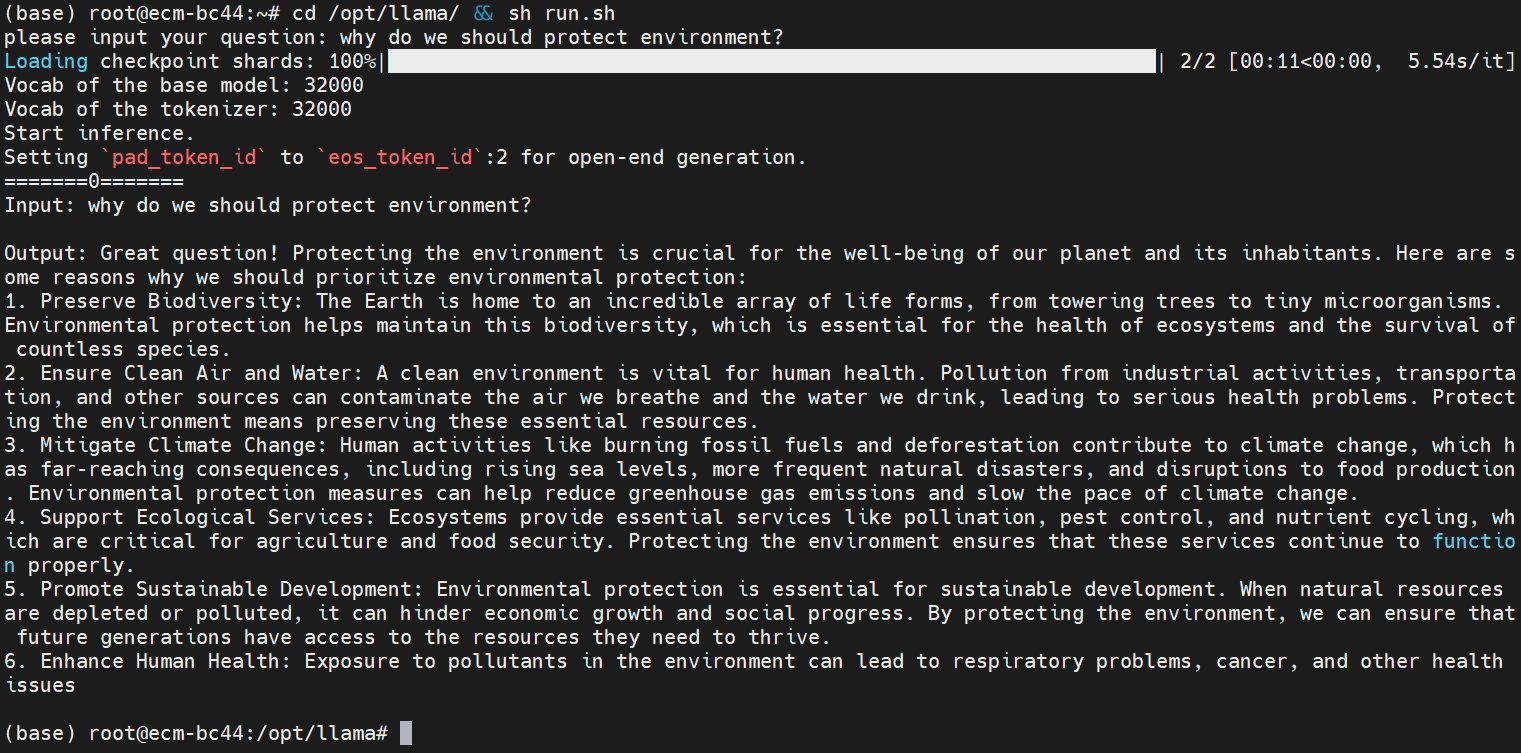
注意
大模型推理场景下不同模型多于显卡显存和云盘的大小都有一定要求。

