


诞生
随着近些年互联网的蓬勃发展与沉淀,人们已越来越习惯于面对海量数据并从其中挖掘价值,由此产生了人所熟知的“大数据”,诸多经典组件随之出现。这些组件不但夯实与完善了大数据领域,也对云计算等相关领域的发展起到了显著的促进作用。
今天,层出不穷的数据出现得越来越快、数据量越来越大,同时,人们对价值的挖掘与追求对数据处理的实时性要求越来越高,而批处理方式和早期的流式处理框架因其自身的局限性,难以在延迟性、吞吐量、容错能力以及使用便捷性等方面满足业务日益苛刻的要求。正是在这一矛盾的催生下,Flink诞生了,它独特的天然流式计算特性和更为先进的架构设计,极大地改善了以前的流式处理框架所存在的问题。
具体来说,Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。阿里巴巴在2015年开始使用并持续贡献社区,在2019年则更是直接收购了Flink所属公司。
在云计算生态方面,Flink可作为PaaS的核心计算组件;在大数据生态方面,Flink则在数据仓库、数据湖等对数据处理的实时性有较高要求的业务场景中占有重要地位。
定义
Apache Flink 是一个框架和分布式处理引擎,用于在 无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
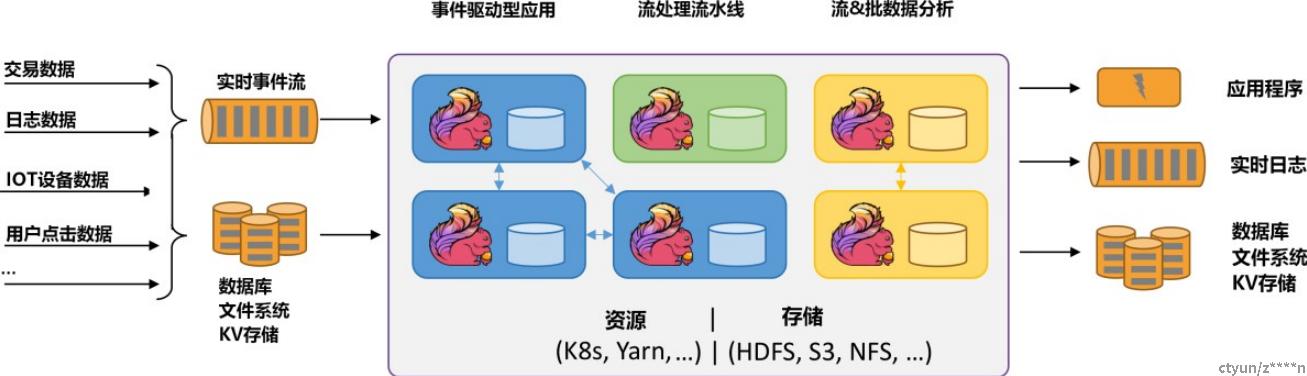
Flink可以处理批数据也可以处理流数据,本质上,流处理是Flink中的基本操作,流数据即无边界数据流,在Flink中处理所有事件都可看成流事件,批数据可以看成是一种特殊的流数据,即有边界数据流。
初窥
下面以一个简单的统计单词数量(wordcount)的例子来初步了解一下开发者眼中的Flink大概是什么样子的。
public static void main(String[] args) throws Exception {
// 创建Flink任务运行的环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 创建DataSet,数据是一行一行的文本
DataSet<String> text = env.fromElements(
"Flink Hello World",
"Flink Flink World",
"Hive Elastic Search",
"Hadoop Hive zookeeper",
"Hello World Hello"
);
// 通过Flink内置的转换函数进行计算
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 将文本分割
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}).groupBy(0)
.sum(1);
// 结果打印
counts.print ();
}本例可以数出一批单词中各个单词出现的次数。具体来说,就是从文件中读取一批单词,而后对这批数据进行转换与聚合,最后将每个单词出现的次数输出到终端。
这个例子可以直观地看出,Flink的工作流程是Source -> Transformation -> Sink。Source为数据来源(本例中为文件),Transformation表示用各种算子对数据进行处理(本例中为flatMap),Sink为处理结果的输出目的地(本例中为终端)。
事实上,Flink支持各种各样的Source、Transformation与Sink,开发人员可直接使用Flink官方提供的也可自行定制化。
核心组成
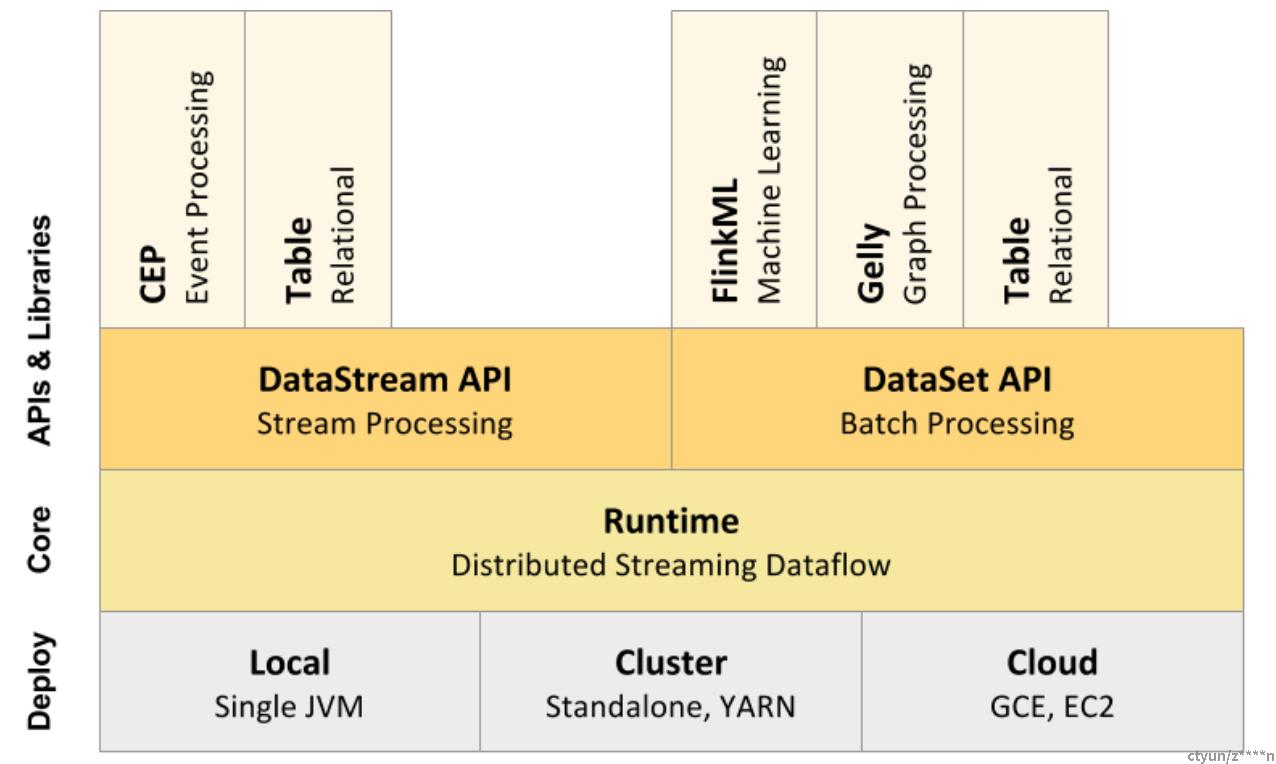
- Deploy 层:
Flink 支持本地运行、能在独立集群或者在被 YARN 或 Mesos 管理的集群上运行,也能部署在云上。 - Core 层:
Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理。 - API 层:
DataStream、DataSet、Table、SQL API。
扩展库:Flink 还包括了用于复杂事件处理、机器学习、图像处理和 Apache Storm 兼容的专用代码库。
核心特性
在Flink看来,一切皆为流(stream),正如它的创始人Stephan Ewen所言:“Stream Processing takes on Everything”(流处理解决所有问题);他甚至提出用流去解决诸如分布式事务等复杂的分布式问题,可见,流,是Flink的设计理念的核心基础之一。正是在这种“流世界观”的基础之上,延伸出了支持有状态计算的Flink的低延迟、高吞吐、可扩展与强一致性的架构设计。
作为一款分布式流计算引擎,Flink主要有以下特点:
- 事件驱动:相较于消息驱动,事件驱动更为灵活且更看重整个系统对事件的响应情况;
- 流批一体:不同于Spark将流看做“微批”,Flink是建立在真正的流数据基础之上的,批数据对Flink而言,只不过是特殊的有边界的流数据。更为深刻地说,Flink可以让流处理和批处理共用同一个开发团队、同一个计算框架与同一套业务代码逻辑,实现了真正的流批一体;
- 低延迟与高吞吐:Flink天然就是分布式计算框架且可进行基于YARN的集群部署;
- 高可靠:节点故障时Flink可以保证数据的一致和可靠;
- 支持有状态计算:每个计算节点都可以对计算状态进行存储;
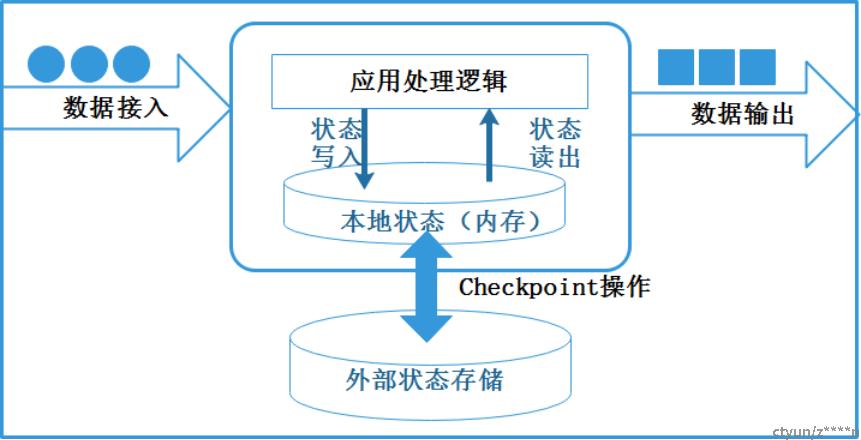
- Exactly-once:Flink基于2PC(二阶段提交)与checkpoint机制,实现了端到端的精准一次处理;
- 高级API:DataStream API与DataSet API,轻松编写流批一体的代码;
- 丰富的功能:时间操作、窗口操作等。
