


nn.Conv2d
主要有这些参数
- in_channels
- out_channels
- kernel_size
- stride = 1
- padding = 0
- dilation = 1
- groups = 1
- bias = True
- padding_mode = 'zeros'
卷积后图片尺寸计算公式:

dilation=1时简化为:
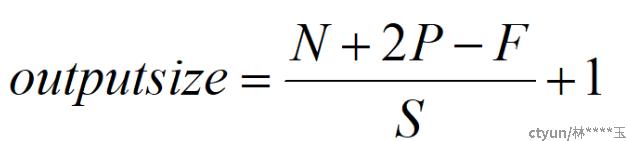
感受野大小的计算公式:
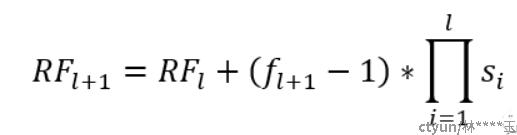
其中RF_l+1为当前特征图对应的感受野大小,也就是我们要计算的目标感受野,RF_l为上一层特征图对应的感受野大小,f_l+1为当前卷积层卷积核大小,最后一项连乘项则表示之前卷积层的步长乘积。输入层初始化感受野为1 * 1。当步长大于1时,感受野的大小会呈现指数级增长。感受野还有一点比较重要的是,对于一个卷积特征图而言,感受野中每个像素并不是同等重要的,越接近感受野中间的像素相对而言就越重要。
|
尺寸
|
通道
|
感受野
|
||
|
nn.Conv2d(kernel_size=1)
|
不变
|
由out_channels 决定
|
可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。计算量明显减少。
|
|
|
nn.Conv2d(kernel_size>1)
|
由out_channels 决定
|
扩大
|
增加kernel_size也能扩大感受野,但是参数会增加
|
|
|
nn.Conv2d(dilation>1)
|
不变
|
由out_channels 决定
|
扩大
|
扩大感受野,同时保持像素的相对空间位置不变,分辨率不变,不增加参数量。一串互质的dilation可以少遗失像素信息,不互质会遗失很多 像素信息。
In dilated convolution, a small-size kernel with k × k fifilter is enlarged to k + (k − 1)(r − 1) with dilated stride r.允许灵活地聚合多尺度的上下文信息,同时保持相同的分辨率。
|
|
nn.Upsample
|
变大
|
不变
|
||
|
nn.functional.interpolate
|
变小
|
不变
|
||
|
nn.MaxPool2d(kernel_size, stride)
|
不变
|
扩大
|
扩大感受野,但分辨率降低,不增加参数量
池化层(如最大池化和平均池化)被广泛用于保持不变性和控制过拟合,它们也显著降低了空间分辨率,意味着特征图的空间信息丢失。
|
|
|
nn.AdaptiveAvgPool2d((H,W))
|
(H,W)
|
不变
|
扩大
|
扩大感受野,分辨率可自定义,不增加参数量
|
dilated conv
叫做空洞卷积或者扩张卷积, 并不是做upsampling,而是增大感受野
deconv,transposed conv
其中一个用途是做upsampling,即增大图像尺寸。
ROI Pooling
就是将大小不同的feature map 池化成大小相同的feature map,利于输出到下一层网络中。RoI Pooling 具有位置敏感性 translation variance。卷积层位置不敏感(translation-invariance),若在“卷积层之间”放置RoI Pooling ,RoI Pooling Layer 之后的卷积层不是共享计算的,它们是针对每个 RoI 进行特征提取的,这样做牺牲了测试速度,因为所有 RoIs 都要经过若干层卷积计算,测试速度会很慢,所以不能直接这样做。
deformable convolution和deformable ROI pooling
提升CNNs的形变建模能力,产生可变形的卷积神经网络,解决多尺度、多姿势、多视角和变形问题。可变形的卷积则考虑到了目标的形变,映射到前面层的采样点大多会覆盖在目标上面,采样到更多我们感兴趣的信息。
CNN 处理几何形变(geometric transformations)的能力不够强,通常是通过扩大数据集、增大模型容量和一些简单模块设计(e.g. max-pooling for small translation-invariance)来解决。
CNN 处理几何形变(geometric transformations)的能力不够强,通常是通过扩大数据集、增大模型容量和一些简单模块设计(e.g. max-pooling for small translation-invariance)来解决。
