


Coroutine实现机制
对于OS来说, Coroutine不是线程,因为OS没有办法直接对Coroutine进行调度;但是Coroutine有独立的栈, 所以Coroutine就是一个在当前线程环境下的一个独立执行流(可以同时存在多个上下文环境但不能同时执行,因为在同一个线程中), 这个独立执行流的调度是通过代码主动进行的。Coroutine的ANSI-C的简单实现可以看这篇文章:https://www.chiark.greenend.org.uk/~sgtatham/coroutines.html 这篇文章介绍如何使用纯c的代码(macro)实现这样的一种效果:当一个函数被调用并返回后, 再次调用这个函数时继续从之前函数调用返回时的返回指令的下一条指令处继续执行。
qemu通过如下libc提供的接口实现:
getcontext();
makecontext();
swapcontext();关于上述函数的说明可以直接 man makecontext, linux manual里面有详细的说明。需要注意的是,qemu并不是完全依靠上述的机制实现Coroutine,还使用sigsetjmp()/siglongjmp()这几个接口。那么我们有如下的疑问:
-
为什么不直接使用sigsetjmp()/siglongjmp()实现Coroutine?
因为sigsetjmp()/siglongjmp() 只是工作在当前的栈上,它只是提供了突破正常函数调用栈的限制,而没有分配一个独立的栈;
-
实现Coroutine时为什么还是用sigsetjmp()/siglongjmp()?
主要原因是在调用 ucontext 这些接口时会保存signal masks,这会存在一个系统调用的开销。而 sigsetjmp()/siglongjmp()并不会保存 signal mask,所以结合这两者可以实现一个轻量级的Coroutine.
上面的说明可以从qemu Coroutine实现源码注释中找到(本文参考的是qemu版本是2.9.1),qemu是从如下这个commit引入了Coroutine
commitid: 00dccaf1f848290d979a4b1e6248281ce1b32aaa
qemu Coroutine执行流程
下图就是qemu在执行block操作时Coroutine调度执行流(基于qemu版本2.9.1分析):
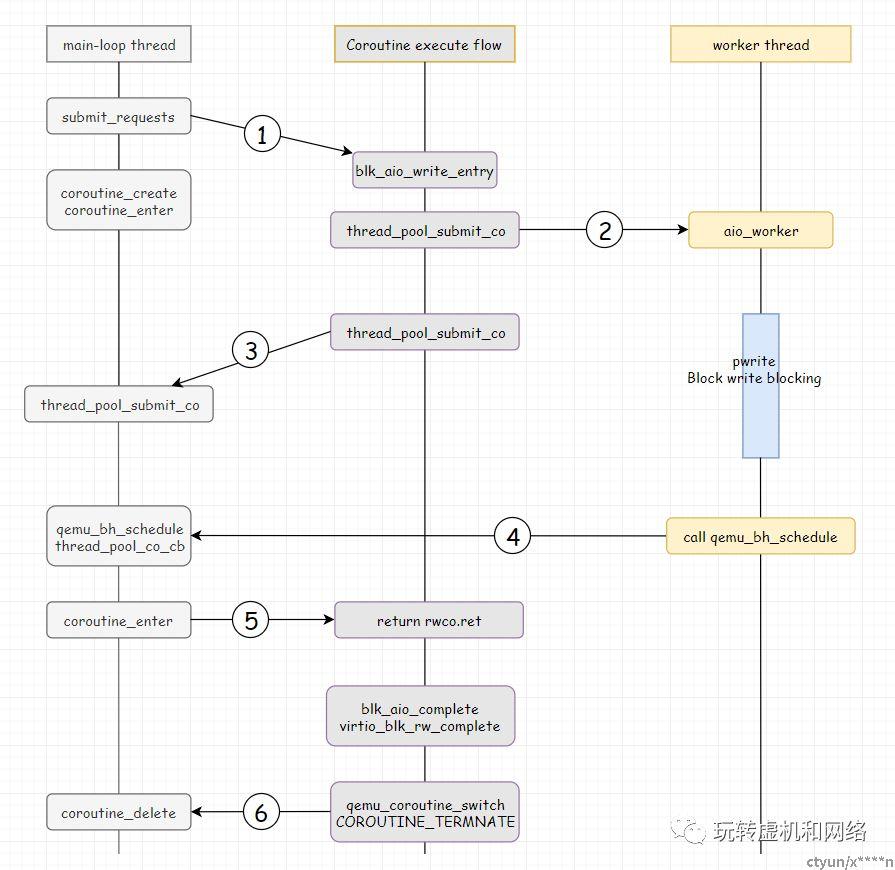
|
步骤 |
说明 |
|||
|
1 |
main-loop线程接收到虚机的block-req,创建一个Coroutine,然后将执行流切入到Coroutine中执行; |
|||
|
2 |
Coroutine继续将block-req提交到线程池里面的一个线程去执行; |
|||
|
3 |
Coroutine将执行流切换回main-loop;注意:此处可以看到main-loop是不会阻塞的; |
|||
|
4 |
当worker_thread完成block-req的执行后,需要将返回结果通知调用方即Coroutine;如何通知?通过qemu_bh_schedule提交给qemu的BH去执行; |
|||
|
5 |
在BH中执行的callback为:thread_pool_co_cb,这个函数中再次将执行流切换到Coroutine中。 |
|||
|
6 |
Coroutine此时已经获得block-req的执行结果了,一方面将返回结果返给调用方,另一方面调用block设备注册的回调,更新block设备的状态信息。然后Coroutine将执行流切换回main-loop,main-loop中删除协程占用的资源,这样完成了一个block-req的处理。 |
|||
为什么使用Coroutine实现
先看看如果对于上面的流程不用协程我们需要怎么处理?
若不用协程的话,对于每个提交给worker_thread执行的block-req, 在main-loop中都要有记录(暂且称之为“请求记录表”),当worker_thread执行完成后,需要查询“请求记录表”找到相应的block-req,更新这个block-req的状态,做一些收尾的工作。这样实际也实现了我们需要的功能;但是这样势必需要我们保存一个“请求记录表”,而且要去频繁的查询。与Coroutine相比,一方面代码不简洁,另外一方面性能也有损失(因为需要查询)。
协程其实可以看做是上述请求记录表的另外一种实现方式,同时我们是不是又一次看到了以空间换时间的思想呢。
关键代码分析
上述只是描述了Coroutine的设计思路及其框架处理流程,下面抽取关键代码片段进行注释说明(我们主要聚焦于Coroutine相关的代码,包括:如何提交req、Coroutine如何创建、Coroutine如何destroy),这样我们就可以看到Coroutine具体是如何落地实现的。
-
blk_aio_prwv
blk_aio_prwv /** * submit_requests 通过blk_aio_pwritev 提交req;并提供了当req完成后的回调 * virtio_blk_rw_complete; */ blk_aio_pwritev(blk, sector_num << BDRV_SECTOR_BITS, qiov, 0, virtio_blk_rw_complete, mrb->reqs[start]); BlockAIOCB *blk_aio_pwritev(BlockBackend *blk, int64_t offset, QEMUIOVector *qiov, BdrvRequestFlags flags, BlockCompletionFunc *cb, void *opaque) { /* 这个函数中封装了 Coroutine的执行函数 blk_aio_write_entry */ return blk_aio_prwv(blk, offset, qiov->size, qiov, blk_aio_write_entry, flags, cb, opaque); } static BlockAIOCB *blk_aio_prwv(BlockBackend *blk, int64_t offset, int bytes, QEMUIOVector *qiov, CoroutineEntry co_entry, BdrvRequestFlags flags, BlockCompletionFunc *cb, void *opaque) { BlkAioEmAIOCB *acb; Coroutine *co; bdrv_inc_in_flight(blk_bs(blk)); /* 申请一个 BlkAioemaiocb, 这个对象封装了req需要的所有信息 */ acb = blk_aio_get(&blk_aio_em_aiocb_info, blk, cb, opaque); acb->rwco = (BlkRwCo) { .blk = blk, .offset = offset, .qiov = qiov, .flags = flags, .ret = NOT_DONE, }; acb->bytes = bytes; acb->has_returned = false; /** * 创建一个Coroutine, Coroutine的入口函数为:coroutine_trampoline, 这个函数是对 * 此处参数 co_entry 的封装;在创建Coroutine时, qemu的做法是先将执行流切入到Coroutine * 中执行一段, 然后再切回来, 执行到哪儿呢?执行到 coroutine_trampoline 的 while(ture)... 处。 * 为后续qemu_coroutine_enter 进入Coroutine开始真正执行用户提供的co_entry做好准备. */ co = qemu_coroutine_create(co_entry, acb); qemu_coroutine_enter(co); acb->has_returned = true; if (acb->rwco.ret != NOT_DONE) { aio_bh_schedule_oneshot(blk_get_aio_context(blk), blk_aio_complete_bh, acb); } return &acb->common; } int coroutine_fn thread_pool_submit_co(ThreadPool *pool, ThreadPoolFunc *func, void *arg) { ThreadPoolCo tpc = { .co = qemu_coroutine_self(), .ret = -EINPROGRESS }; assert(qemu_in_coroutine()); /** * 将io请求提交给线程线程池中的线程处理, 线程为worker_thread * worker_thread调用aio_worker处理req, 处理完成req后qemu_bh_schedule(pool->completion_bh); * 这个bh会调用此处的thread_pool_co_cb. */ thread_pool_submit_aio(pool, func, arg, thread_pool_co_cb, &tpc); qemu_coroutine_yield(); /** * 执行完成上面的语句后, 即完成了req的提交,并将执行流切换回main_loop. * 当通过上述过程调用thread_pool_co_cb时, 会将执行流程再次切入到此处, 返回io执行的结果。 */ return tpc.ret; } /** * 注意:上述的 thread_pool_co_cb 必须有worker_thread提交到bh执行, 这样可以保证main-loop线程的串行化执行。 * 如果直接切换回Coroutine, 将会有竞争问题。 * 此外, 此处的qemu_coroutine_yield();有一石两鸟的作用, 第一将执行流引到了main-loop; 第二同时记住了Coroutine * 的执行点, 使得 thread_pool_co_cb 可以再次回到此处, 当然限制只能通过main-loop执行流回到此处。 * 回到此处经过层层退出到Coroutine的入口blk_aio_write_entry, 然后执行blk_aio_complete(acb), 在这个函数中 * 会调用virtioblk注册的请求完成回调接口virtio_blk_rw_complete, 完成virtio队列更新等操作。 */ /* 完成上述操作, 那么Coroutine如何结束呢?*/ static void coroutine_trampoline(int i0, int i1) { union cc_arg arg; CoroutineUContext *self; Coroutine *co; arg.i[0] = i0; arg.i[1] = i1; self = arg.p; co = &self->base; /* Initialize longjmp environment and switch back the caller */ if (!sigsetjmp(self->env, 0)) { siglongjmp(*(sigjmp_buf *)co->entry_arg, 1); } while (true) { co->entry(co->entry_arg); /** * 此处的entry为blk_aio_write_entry, 执行完成这个函数后, 就完整的处理完了一个blk的req; * 注意当前还是处于Coroutine的执行流中, 通过下面的调用将Coroutine切换回mail-loop BH中,实际 * 是调用到qemu_coroutine_enter这个执行流中, 此处的参数为COROUTINE_TERMINATE, 在 * qemu_coroutine_enter中根据这个标志将Coroutine delete了。这样BH也执行完成了, * 执行流也回到main-loop。世界终于清净了... */ qemu_coroutine_switch(co, co->caller, COROUTINE_TERMINATE); } }
