


Segment Anything 是Meta于2023年4月5日发表的一个文章。文章有以下贡献点:
- 开源了可以分割一切的模型 Segment Anything Model (SAM)
- 开源了一个分割数据集,包含1100万图像,约10亿个mask标注。是目前规模最大的数据集。
- SAM具有强大的零样本迁移能力,在未经训练过的数据集上的表现能够等同甚至超越最好的模型
由于SAM强大的能力,文章发表1个月后,目前已经有许多基于SAM构建的下游应用。本文将介绍一部分比较优秀的基于SAM构建的下游应用。
1. Segment Anything Labelling Tool (SALT)
链接:https://github.com/anuragxel/salt
利用Segment-Anything 模型并添加系统界面来标记图像。本项目支持在图片相应目标区域内进行点击,然后直接生成对应目标的边界框,相较于以往的工具,本项目能够减轻标注时所需的时间,同时提高标注的准确率。项目缺点是还不支持类别自动识别。

2. segment-anything-with-clip--Anything+CLIP自动标注
链接:https://github.com/z-x-yang/Segment-and-Track-Anything
Meta发布了一个新的分割任务基础模型。它旨在通过提示工程解决下游分割任务,例如前景/背景点、边界框、掩模和自由形式文本。不过,文本提示目前尚未发布。
本项目采用CLIP,通过文本提示生成分割区域。Clip是一种由OpenAI提出的深度学习模型,其全称为"Contrastive Language-Image Pre-Training”。该模型可以同时处理图像和文本数据,并能够在两者之间建立联系。它的核心思想是预训练一个模型来理解文本和图像之间的语义关系,然后使用该模型进行下游任务,如图像分类、文本生成等。在预训练过程中,Clip模型通过学习将不同语言描述与对应的图像匹配起来,从而得到了一种跨模态的表示方法,使得该模型在执行各种自然语言处理和计算机视觉任务时表现出色。
生成的步骤如下:
1)获取由SAM(Segment Anything Model)生成的所有对象。
2)通过边界框裁剪对象区域。
3)从CLIP中获取裁剪的图像特征和查询特征。
4)计算图像特征与查询特征之间的相似性。
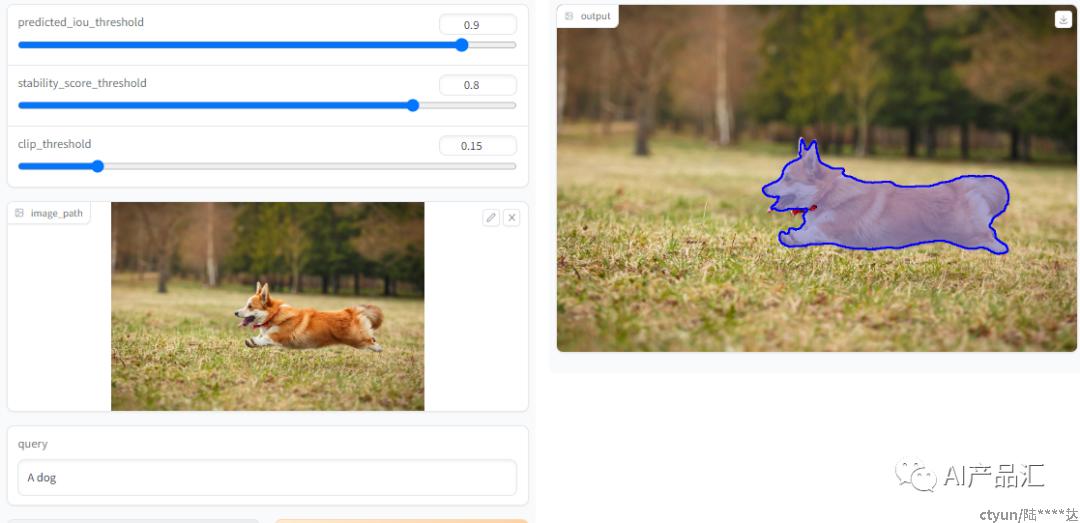
如下图,输入一张图片以及文本“dog”,即可从图片中分割出小狗相应的区域。
3. 分割并跟踪一切(Segment-and-track anything,SAM-track)
链接:https://github.com/z-x-yang/Segment-and-Track-Anything
Segment and Track Anything 是一个开源项目,专注于利用自动化和交互式方法对视频中的任何物体进行分割和跟踪。主要使用的算法包括 SAM(Segment Anything Models)用于自动/交互式关键帧分割,以及 DeAOT(Decoupling features in Associating Objects with Transformers)(NeurIPS2022)用于高效的多目标跟踪和传播。SAM-Track 管道通过 SAM 动态和自动地检测和分割新对象,而 DeAOT 则负责跟踪所有已识别的对象。

4. 修补一切(Inpaint Anything)
论文链接:https://arxiv.org/abs/2304.06790
代码链接:https://github.com/geekyutao/Inpaint-Anything
该论文提出了一种新的"点击填充"范式,用于无遮挡图像修复,称为"Inpaint Anything (IA)”。IA支持三个主要功能:1. 删除任何东西,用户只需点击想要去除的物体,IA将无缝地移除该物体,实现高效的“魔法消除”;2. 用户还可以通过文本提示告诉IA想要在物体内填充什么,IA随即通过驱动已嵌入的AIGC模型(如Stable Diffusion)生成相应的内容,以填充物体内部,实现随心所欲的“内容创作”;3. 替换一切(Replace Anything):用户也可以通过点击选择需要保留的物体,然后用文本提示告诉IA想要用什么样的背景替换其背景,从而将物体背景替换为指定的内容,实现生动的“环境转换”。

小结:
Segment Anything Model是一个强大的分割模型,目前其能够在许多没有见过的数据集上都能取得很好的结果。其可能是CV大模型的开启。模型开源1个月以来已经有许多利用SAM打造的下游应用,包括一些用于提高标记效率的工具,以及与图像生成结合后的一些有趣的工具。将来一定会有更多更强大的模型以及工具发布,我们将拭目以待。
