


Stable Diffusion 是一种源自 CompVis 和 Runway 团队的算法,于 2021 年 12 月作为“潜在扩散模型”(LDM) 提出。该模型基于2015年提出的扩散模型(DM)。在 Stable Diffusion 中,数据在三个组件之间流动:像素空间(Pixel Space)、潜在空间(Latent Space)、条件(Conditioning)。
在参考论文中,有插图解释了算法的核心逻辑:
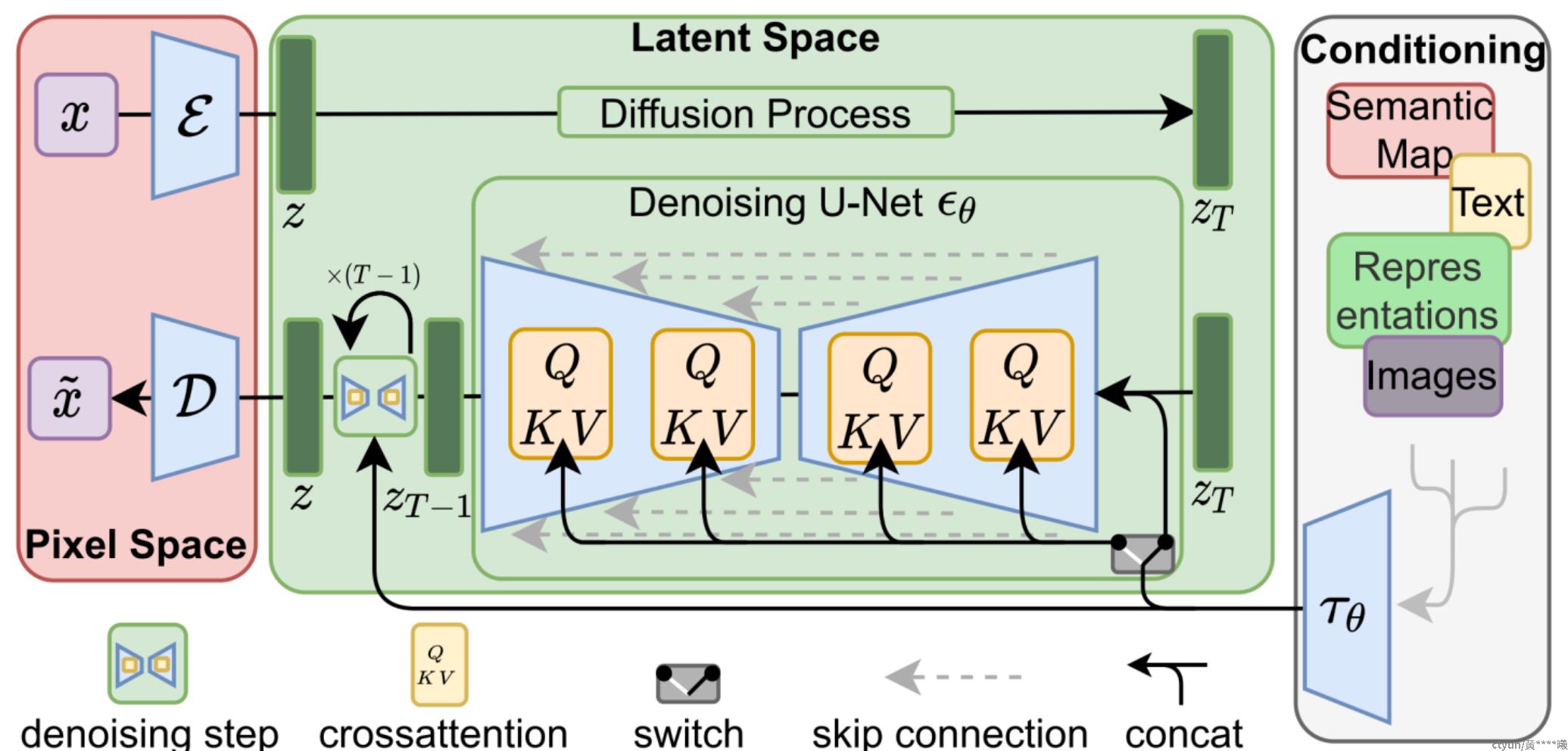
1,图像编码器将图像从像素空间压缩到较低维的潜在空间,捕捉图像的本质。
2,噪声被添加到潜在空间中的图像,以启动扩散过程。
3,CLIP 文本编码器被用于将输入的描述语转换为去噪过程的条件。
4.基于某些条件对图像进行去噪以获得生成图像的潜在表示。去噪步骤可以灵活地使用文本、图像或其他形式作为条件(text-to-image as condition,即text2img,或image-to-image as condition,即img2img)。
图像解码器通过将图像从潜在空间转换回像素空间来生成最终图像。
“扩散”源于一种物理现象:当我们将墨水滴入水中时,墨水会均匀扩散。这个过程一般是不可逆的。 AI 能做到这一点吗?
在扩散模型中,研究人员通过向图像添加噪点,逐渐将图像转变为完全噪点的图像。然后,他们让AI学习这个过程的逆向过程,也就是如何从一张完全噪点的图像中恢复出包含信息的高清图像。
扩散模型有一个主要的缺点就是去噪过程的时间和内存消耗都非常昂贵。这会使进程变慢,并消耗大量内存。主要原因是它们在像素空间中运行,特别是在生成高分辨率图像时。
Latent diffusion通过在较低维度的潜空间上应用扩散过程而不是使用实际的像素空间来减少内存和计算成本。所以Stable Diffusion引入了Latent diffusion的方式来解决这一问题计算代价昂贵的问题。
Latent diffusion有三个主要组成部分:
自动编码器(VAE)
由编码器和解码器两个主要组件组成。编码器将图像转换为低维的潜在表示形式,并将其作为下一步骤中的组件U-Net的输入。解码器则完成相反的操作,将潜在表示转换回图像的形式。
在Latent diffusion的训练过程中,编码器用于获得正向扩散过程中输入图像的潜在表示。而在推断过程中,VAE的解码器将把潜在信号转换回图像的形式。
U-Net
U-Net也包括编码器和解码器两个部分,它们都由ResNet块组成。编码器将图像表示压缩为低分辨率图像,而解码器将低分辨率图像解码为高分辨率图像。
为了避免在U-Net的下采样过程中丢失重要信息,通常在编码器的下采样ResNet块和解码器的上采样ResNet块之间添加了捷径连接。
在Stable Diffusion的U-Net中,还添加了交叉注意力层来调节文本嵌入的输出。交叉注意力层被插入到U-Net的编码器和解码器ResNet块之间。
Text-Encoder
文本编码器将把输入文字提示转换为U-Net可以理解的嵌入空间,这是一个简单的基于transformer的编码器,它将标记序列映射到潜在文本嵌入序列。从这里可以看到使用良好的文字提示以获得更好的预期输出。
