


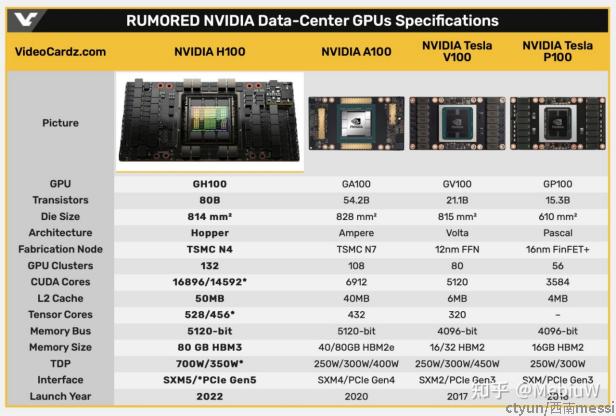
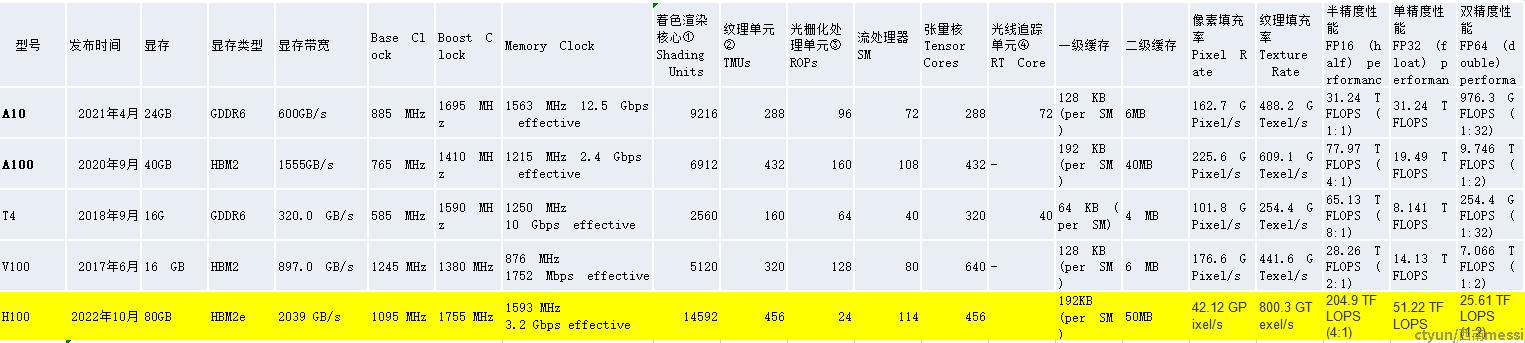
GTC22上老黄发布了全新的GPU H100。H100采用了Hopper架构,800亿晶体管,812mm的面积,台积电N4工艺,纸面性能差不都翻了三倍,功耗也从400W提升到了700W。
一、架构
H100采用全新架构Hopper,相比于安培架构,所有参数均有提升:
8个GPC(GPU Processing Cluster,GPU处理集群);
72个TPC(Texture Processing Cluster,纹理处理集群),每个GPC含9个TPC;
144个SM(Streaming Multiprocessor,流多处理器),如下图所示;

和上代的A100的8×8×2=128相比,SM数量增加了12.5%,并不算多。但是每个SM内部的规模则是几乎翻了一倍。H100的SM和A100一样包含4个模块,每个模块的提升包括:
16个INT32执行单元,和A100一致;
32个FP32,比A100的16个翻倍;
16个FP64,比A100的8个翻倍;
Tensor Core(张量计算核心)性能更强,吞吐为A100的2倍;
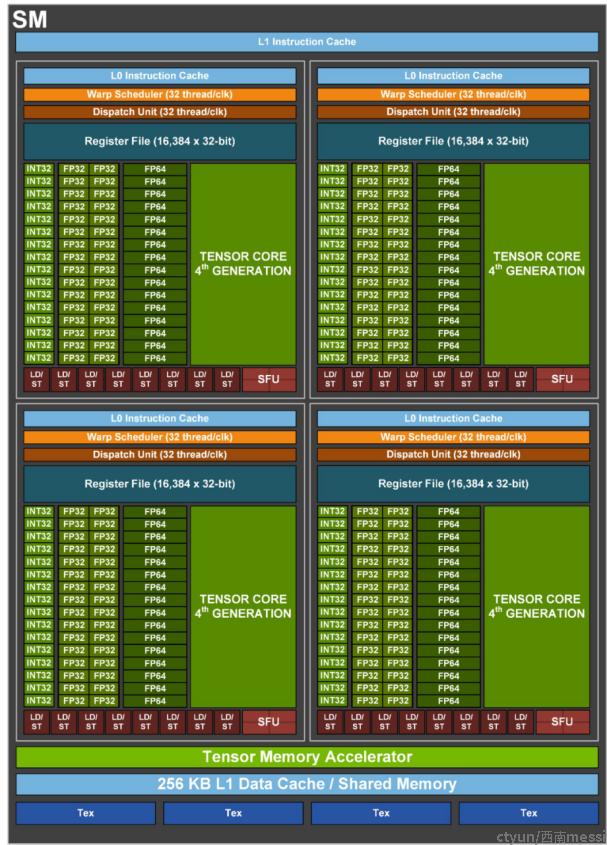
所以,H100的每个SM的同频率理论性能,FP32、FP64和张量计算性能都比A100翻倍。按照NV白皮书的说法,加上SM数量增加和频率提高,整体上H100的性能是A100的3倍。
二 关键特性
- 第四代Tensor Cores
H100相比于上一代A00中FP16/BFloat16的性能,大概有6倍的吞吐提升。这个应该比较容易理解,FP8相比于FP16,拥有更少的内存占用,而且向量化程度可以更高,所以吞吐自然有提升。只有为什么能达到6倍,可以去看原文。
另外,FP8有两种形式,
- E4M3 with 4 exponent bits, 3 mantissa bits, and 1 sign bit
- ● E5M2, with 5 exponent bits, 2 mantissa bits, and 1 sign bit.
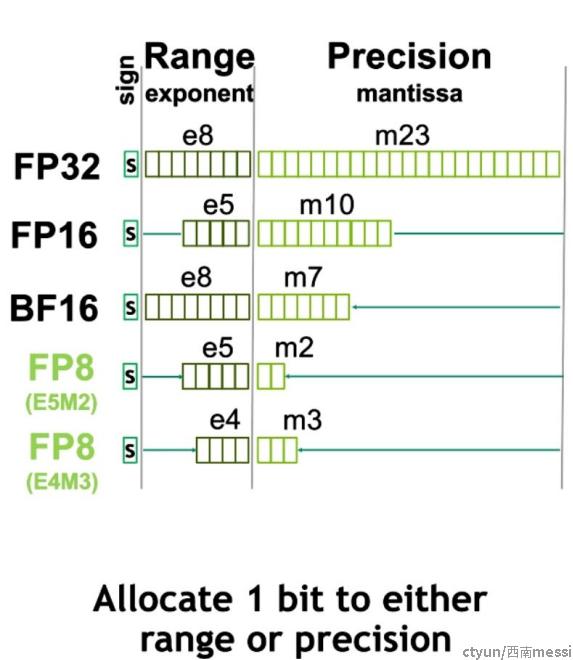
前面提到的transformer engine就混合使用了FP16和FP8两种数据类型去减少内存占用以提高性能,同时精度依然没有损失。
- Thread Block Cluster
CUDA编程模型长期以来一直依赖于GPU计算架构,该架构使用包含多个线程块的grid来利用程序中的局部性。一个线程块包含在单个 SM 上并发运行的多个线程,其中线程间的同步通过barrier操作实现,并使用SM的共享内存互相交换数据。然而,随着 GPU 的增长超过 100 个 SM,计算程序变得更加复杂,线程块作为编程模型中表达的局部性的单元已不足以最大限度地提高执行效率。
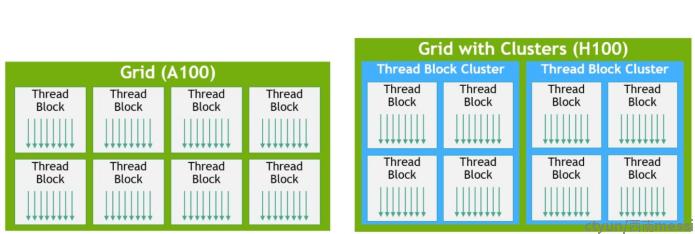
于是H100引入了一种新的线程块集群架构,该架构以比单个 SM 上的单个线程块更大的粒度开放了对局部性的控制。线程块集群扩展了 CUDA 编程模型并为 GPU 的物理编程层次结构添加了另一个级别,现在包括线程、线程块、线程块集群和网格。集群是一组线程块,它们保证被同时调度到一组 SM 上,其目标是实现跨多个 SM 的线程高效协作。
- Distributed Shared Memory
使用线程块集群,所有的线程都可以通过加载、存储和原子操作直接访问其他 SM 的共享内存。此功能称为分布式共享内存 (DSMEM),因为共享内存的虚拟地址空间在逻辑上分布在集群中的所有块中。 DSMEM 使 SM 之间的数据交换更加高效,不再需要在全局内存中写入和读取数据来传递数据。用于集群的专用 SM 到 SM 网络可确保对远程 DSMEM 进行快速、低延迟的访问。与使用全局内存相比,DSMEM 将线程块之间的数据交换速度提高了约 7 倍。
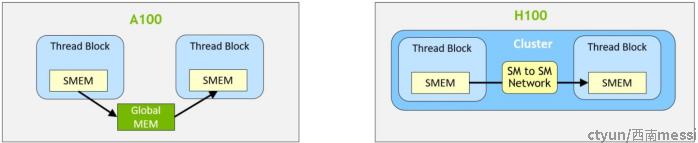
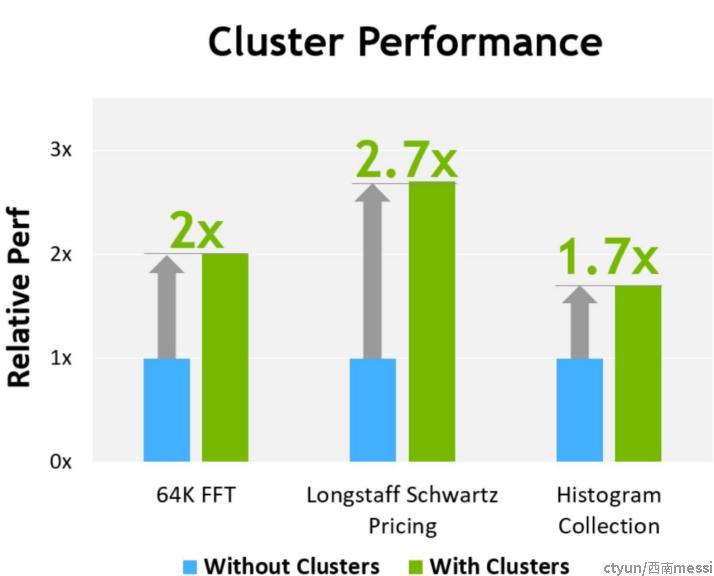
在 CUDA 级别,集群中所有线程块的所有 DSMEM 段都映射到每个线程的通用地址空间,这样所有的 DSMEM 都可以通过简单的指针直接引用。 CUDA 用户可以利用cooperative groups API 来构造指向集群中任何线程块的通用指针。 DSMEM 传输也可以表示为与基于共享内存的屏障同步的异步复制操作,以跟踪完成情况。下图也可以看出来,使用cluster给部分算法的性能带来的的好处。
- 异步执行
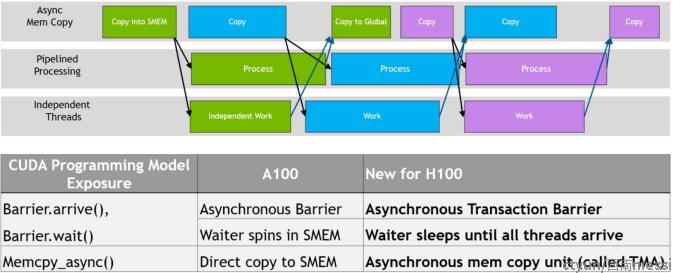
每一代 NVIDIA GPU 都包含大量架构增强功能,以提高性能、可编程性、电源效率、GPU 利用率和许多其他因素。最近几代 NVIDIA GPU 包括异步执行功能,以允许数据移动、计算和同步的更多overlap。 Hopper 架构提供了一些新功能,可以改进异步执行并允许内存副本与计算和其他独立工作进一步重叠,同时还可以最大限度地减少同步点。(下面这个图有点理解的不是特别清楚.....)
张量记忆加速器 (TMA)
为了帮助为强大的新 H100 张量核心提供数据,新的张量内存加速器 (TMA) 提高了数据获取效率,该加速器可以将大块数据和多维张量从全局内存传输到共享内存,反之亦然。TMA 操作使用复制描述符启动,该描述符使用张量维度和块坐标指定数据传输,而不是按元素寻址。可以指定大数据块(达到共享内存容量)并将其从全局内存加载到共享内存或从共享内存存储回全局内存。 TMA 通过支持不同的张量布局(1D-5D 张量)、不同的内存访问模式、缩减和其他功能,显着降低了寻址开销并提高了效率。
TMA 操作是异步的,并利用了 A100 中引入的基于共享内存的异步barrier。此外,TMA 编程模型是单线程的,其中一个 warp 中的单个线程被选为发出异步 TMA 操作 (cuda::memcpy_async) 以复制张量,随后多个线程可以在 cuda::barrier 上等待完成数据传输。为了进一步提高性能,H100 SM 添加了硬件来加速这些异步屏障等待操作。
TMA 的一个关键优势是它可以释放线程来执行其他独立的工作。在 A100 上,异步内存复制是使用特殊的 LoadGlobalStoreShared 指令执行的,因此线程负责生成所有地址并在整个复制区域中循环。在 Hopper 上,TMA 负责一切。单个线程在启动 TMA 之前创建一个复制描述符,然后在硬件中处理地址生成和数据移动。 TMA 提供了一个更简单的编程模型,因为它在复制张量的段时接管了计算步幅、偏移量和边界计算的任务。
Asynchronous Transaction Barrier
异步barrier最初是在 Ampere GPU 架构中引入的。考虑一个示例,其中一组线程正在生成数据,这些数据将在屏障之后全部消耗。异步屏障将同步过程分为两个步骤。首先,线程在完成生成其共享数据部分时会发出“到达”信号。这个“到达”是非阻塞的,因此线程可以自由地执行其他独立的工作。最终,线程需要所有其他线程产生的数据。在这一点上,他们会做一个“等待”,这会阻止他们,直到每个线程都发出“到达”的信号。
异步屏障的优点是它们允许提前到达的线程在等待时执行独立的工作。这种重叠是额外性能的来源。如果所有线程都有足够的独立工作,则屏障有效地变为“空闲”,因为等待指令可以立即退出,因为所有线程都已经到达。
Hopper 的新功能是“等待”线程休眠,直到所有其他线程到达。在以前的芯片上,等待线程会在共享内存中的屏障对象上旋转。
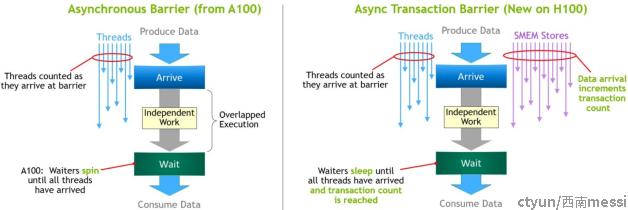
虽然异步屏障仍然是 Hopper 编程模型的一部分,但 Hopper 添加了一种新形式的屏障,称为Asynchronous Transaction Barrier。Asynchronous Transaction Barrier与异步屏障非常相似。它也是一个拆分屏障,但它不仅计算线程到达,还计算事务。 Hopper 包含一个用于写入共享内存的新命令,该命令传递要写入的数据和事务计数。事务计数本质上是一个字节计数。异步事务屏障将阻塞等待命令的线程,直到所有生产者线程都执行了到达,并且所有事务计数的总和达到预期值。异步事务屏障是用于异步内存副本或数据交换的强大新原语。如前所述,集群可以进行线程块到线程块的通信以进行具有隐含同步的数据交换,并且集群功能建立在异步事务屏障之上。
