


Architecture Overview
CockRoach支持兼容PostgreSQL的SQL API,并将接收到的SQL转化为KV操作,落盘到分布式事务型KV存储上。
目标
- 支持大规模集群的一致性,支持分布式事务。
- Always-on多读多写集群。
- Raft一致性协议。
- multi-active availability:基于一致性协议的高可用,每个节点负责一个子集数据的读写。有别于active-passive replication和active-acitve replication,前者所有流量都访问active节点,后者所有节点接收请求,但无法保证数据是最新的。
概念介绍
- clutser:一个由多个存储节点构成的支持事务、差错容忍、数据均衡的集群。
- node:一个Cockroach实例,一个cluster由一个或多个node组成。
- range:Cockroach以键值对key-value的方式存储表或索引数据。这些键值对会被分为若干个chunk(默认512MB一个chunk),这些chunk被称为range。
- replica:每个range默认会有3个副本,用于实现高可用和差错容忍。
- lease-holder:每一个range会有一个replica负责协调该range的读写请求,被称为lease-holder。
- raft-leader:每个range会有一个reolica负责处理写请求,由Raft协议选出,因此能保证得到大多数节点的同意。Raft-leader一般同时也是lease-holder
- raft-log:一种基于时序的日志,用于Raft协议在各节点间传递、落盘,以实现一致性。
Layers
- SQL Layer:负责解析SQL查询为KV操作
- Transactional Layer:负责批量KV的原子操作,实现ACID的事务隔离级别。
- Distribution Layer:以整体的方式展示被同步的KV range
- Replication Layer:将KV range复制同步到其他节点。这一层同样支持基于一致性协议的一致性读。
- Storage Layer:读写KVData到磁盘上。
Transactional Layer
本层实现ACID事务隔离级别,Cockroach只支持“autocommit mode”,每一个statement都会自动提交。Cockroach基于一个称为Parallel Commits的协议完成事务隔离。共分为三阶段
阶段一:(writes and reads)
Writes:
此阶段并不是直接将数据落盘,而是为分布式事务做准备。
- 对要写入的数据上锁
- Unreplicated Locks:仅保存于内存,这些Lock不通过Raft同步
- Replicated Locks(也被称为write intents):通过Raft同步到其他节点,作为一个临时值和排它锁的组合。他们等价于MVCC的值并且包含一个对于transaction record的指针。
- 记录一条transaction record,用于记录本次写入的range的事务状态(PENDING、STAGING、COMMITED或ABORTED)
如果这些write intents在同步的过程中发现冲突,将会使事务中止。
Reading:
如果事务没有被中止,事务将会执行读取操作。如果读取的内容不涉及任何write intents,将被顺利执行。如果与write intents相互冲突,将会出现两种情况。
- Strongly-consistent (aka "non-stale") reads:交由leaseholder检查读取数据时刻之前已提交的写操作,以保证读取数据的准确性。
- Stale reads:无需经过leaseholder,直接返回节点本地的数据,无法保证准确性(又被称为Follower Reads)。
阶段二:(commits)
修改transaction record为STAGING,并检查write intents是否被成功传播到大多数节点(没有触发冲突)。如果事务通过了检查,则CockroachDB会通知客户端事务执行成功,并进入最后的清理阶段。此刻后,事务已提交,客户端可以发起下一个请求。
阶段三:(cleanups)
- 修改transaction record为COMMITED
- Resolves the transaction's write intents to MVCC values by removing the element that points it to the transaction record.
- 删除write intents
Distributed Layer
为了使访问任意一个节点都能访问到全量数据,CRDB会将数据存放在一个单调递增的KV map中。这些KV描述数据在哪个节点,并被切分为多个range(一段连续的KV)。因此任意一个Key都能在其中一个range中找到。
这样做的好处主要有两点:
- 简易查找:因为我们定义了哪些节点某个范围的数据,因此查询可以很容易定位到要找到这些数据需要访问哪些节点。
- 高效扫描:由于数据有序,方便查找一个范围内的数据。
通过图例更好说明问题:
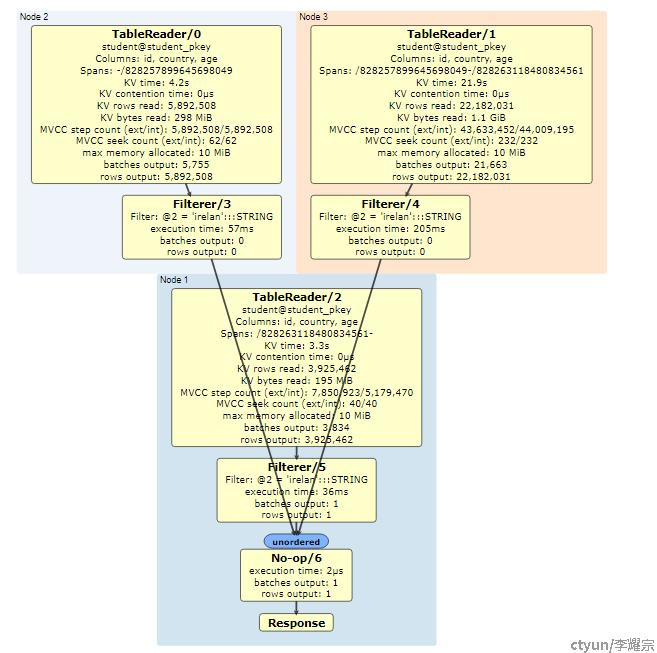
如下图所示是一个全表扫描的执行计划,关注Spans信息可以看到,student表被切分为三个范围并被存放在三个节点上,分别是 -/828257899645698049, /828257899645698049 - /828263118480834561, /828263118480834561 - ,分别表示的就是 负无穷 - 828257899645698049, 828257899645698049 - 828263118480834561, 828263118480834561 - 正无穷三段。
Monotonic sorted map(单调有序map)由两个基本要素组成:
- System Data 系统数据,保存描述位置的meta ranges
- User Data 用户数据,保存用户的表数据
Meta ranges
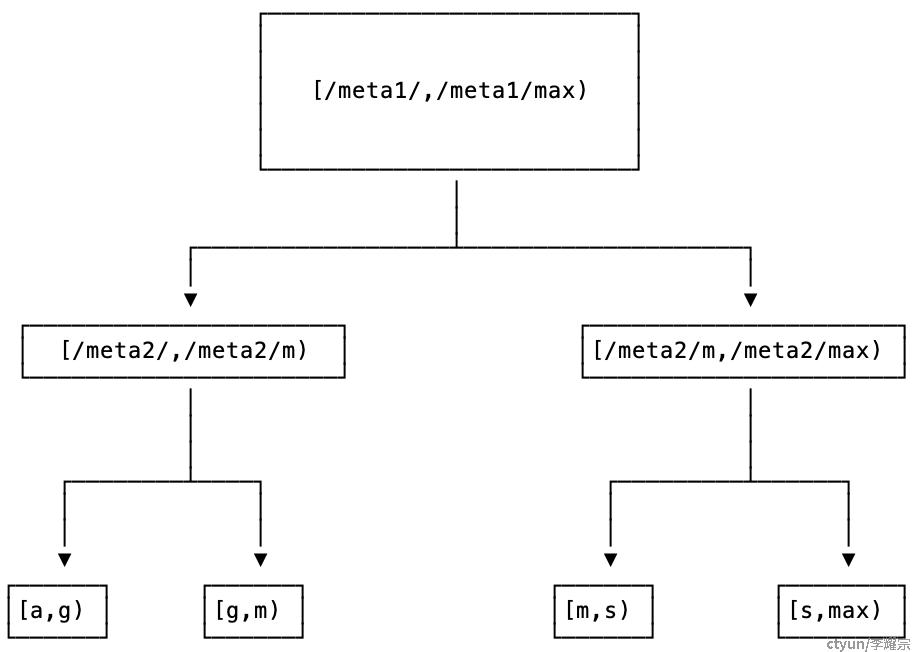
meta ranges会被存放为两层结构的数中,所有节点都会记录指向meta1 range的信息,且meta1 range永远不会分裂。
这种 meta range结构可以保证我们保存4EB的用户数据地址。通过两层结构,我们可以保存2^(18+18)=2^36次个range信息;每个range可以保存2^26Byte(64MB)的数据,合起来就是2^(36+26) B = 2^62 B = 4EiB数据。如果设置单个range存放更多的数据,则理论上还能进一步提高存放的数据总量。
正如上文提到,所有ranges的位置信息都被保存在了这个两层索引中。
- 第一层(meta1)记录指向第二层的地址
- 第二层(meta2)记录指向用户数据(user ranges)的地址
当一个节点接收到一个查询请求,它会自底向上查找包含这些key的ranges的地址。具体的查询过程如下:
- 对于每一个key,首先从meta2搜索起。meta2的信息将会被节点所缓存,如果在缓存中找到,则直接返回。
- 如果range的位置不在缓存中,节点就会寻找真正包含该range信息的meta2的位置。这个信息同样会被缓存下来。如果真正存在该range信息的meta2的地址在缓存中,节点就会向该meta2 range发送RPC请求,以获取想要操作的key所在的range的位置。
- 如果真正保存key的range信息的meta2的地址并不在缓存中,那么节点只能向上查找meta1,meta1必然能找到(因为meta1的位置信息通过gossip协议在所有节点之间传播,并保证所有节点的信息一致),而且必然存在所有meta2的信息,因此可以找到这个meta2并缓存下来。
meta range 结构
如一般的数据,meta range存储的也是KV对,KV对的格式如下。
metaX/successorKey -> [list of nodes containing data]
- metaX: 其实就只有meta1 和 meta2 两种情况, 实际存储的是 /x02和 /x03
successorKey: 表示小于该值的key保存在这个value里,不写成[min,max]是为了提高扫描效率
比如:
# Points to meta2 range for keys [A-M) meta1/M -> node1:26257, node2:26257, node3:26257 # Points to meta2 range for keys [M-Z] meta1/maxKey -> node4:26257, node5:26257, node6:26257
meta1保存了两个meta2 range的信息
- 小于M的key的地址,可以通过第一个meta2 range找到,需要去访问node1(leaseHolder),node2、node3为meta2-1的副本。
- 大于M小于maxKey的地址,可以通过第二个meta2 range找到,需要去访问node4(leaseHolder),node5、node6为meta2-2的副本。
# Contains [A-G) meta2/G -> node1:26257, node2:26257, node3:26257 # Contains [G-M) meta2/M -> node1:26257, node2:26257, node3:26257 #Contains [M-Z) meta2/Z -> node4:26257, node5:26257, node6:26257 #Contains [Z-maxKey) meta2/maxKey-> node4:26257, node5:26257, node6:26257
meta2-1保存了用户range的位置信息:
- 小于G的key的地址,需要去访问node1(leaseHolder),node2、node3为user1的副本。
- G-M的key的地址,需要去访问node1(leaseHolder),node2、node3为user2的副本。
meta2-2保存了用户range的位置信息:
- M-Z的key的地址,需要去访问node4(leaseHolder),node2、node3为user3的副本。
- Z-maxKey的key的地址,需要去访问node4(leaseHolder),node2、node3为user4的副本。
这么描述还是有点抽象,具体到,比如说表student的/1000 - /100000 范围:
- 用户访问节点1,想查找student id = 1001的key
- 查找节点1的缓存,是否缓存有该范围的range位置信息
- 从缓存中无法直接获取到student id =1001 key所在的range的位置信息,寻找缓存中是否有记录student id = 1001 key 需要找哪个meta2的记录
- 依然无法找到meta2的信息,节点1访问meta1的信息,假设student表属于S,应该寻找meta2-2以获取key所在range的位置信息,meta2-2在node4
- 节点1对节点4发起RPC请求,获取meta2-2中保存的range信息并缓存下来
- 节点4反馈信息,得知student表的所有range的所在位置,假设分别为node1(负责/0 - /1000)、node3(负责/1000 - /100000)、node5(负责/100000 - maxValue)
- 节点1对节点3发起RPC请求,获取id = 1001的key
- 节点3反馈信息
- 节点1反馈给用户。
PS:其中6为主观推测,官方文档并未详细描述相关信息。
table data KV结构
普通数据的KV结构如下:
/<table Id>/<index id>/<indexed column values> -> <non-indexed/STORING column values>
具体数据类似如下:
/1035/2314/1000 → 'ca', 16
/1035/2314/1001 → 'usa', 18
(假设student的table_id是1035,其主键(id)的index_id是2314,id=1000的数据→ country = 'ca', age = 16)
(假设student的table_id是1035,其主键(id)的index_id是2314,id=1001的数据→ country = 'usa', age = 18)
Range descriptors
每一个range都会在头部包含一个range descriptors。主要包含如下一下信息:
- 一个RangeID
- range包含的Keyspace范围:例如该range的最小值和最大值,这个信息也会被记录在meta2的key中
- range相关的副本信息:例如node2、node3作为这个range的副本,这个信息也会被记录在meta2的value中
