


Introduction
在计算视觉领域,注意力机制的本质是根据不同的视觉观察对象的重要程度对其进行不同的的资源配置,这种资源配置多数表现为权重分配上。在图像生成领域,已经有很多引入注意力机制的GAN模型,如Self-Attention GAN[1]、CBAM-GAN[2]等。
语义关系对场景理解来讲很重要,目的在于抓住全局依赖性而无关位置。然而许多工作表明,对于图像处理任务来说,仅仅提取局部特征信息不够的。为了有效地完成场景分割的任务,Jun Fu等人[3]提出双重注意力(dual attention)。双重注意力模块由空间注意力模块和通道注意力模块组成。双重注意力模块如图1所示,不同于CBAM模块两种注意力模块串联的方式,双重注意力模块采用的是并联的方式。
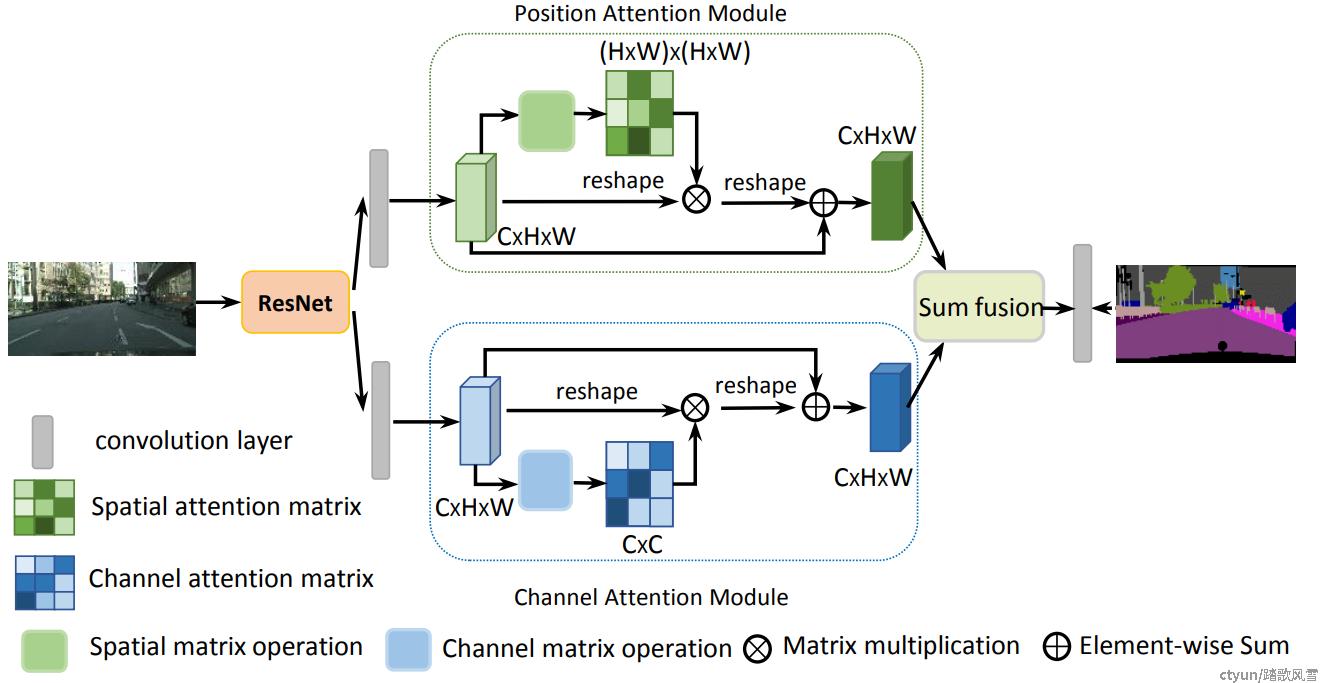
图1 双重注意力模型图[3]
Spatial Attention Module
空间注意力模块的作用机理为:捕获特征中任意两点位置的空间依赖关系,以加权求和的方式,对特定位置的特征进行更新,其权重由该两点的位置特征相似性所决定。具体表现为,无论他们在空间维度中距离如何,如果该两点具有相似位置特征信息,则可以相互促进得以改进。
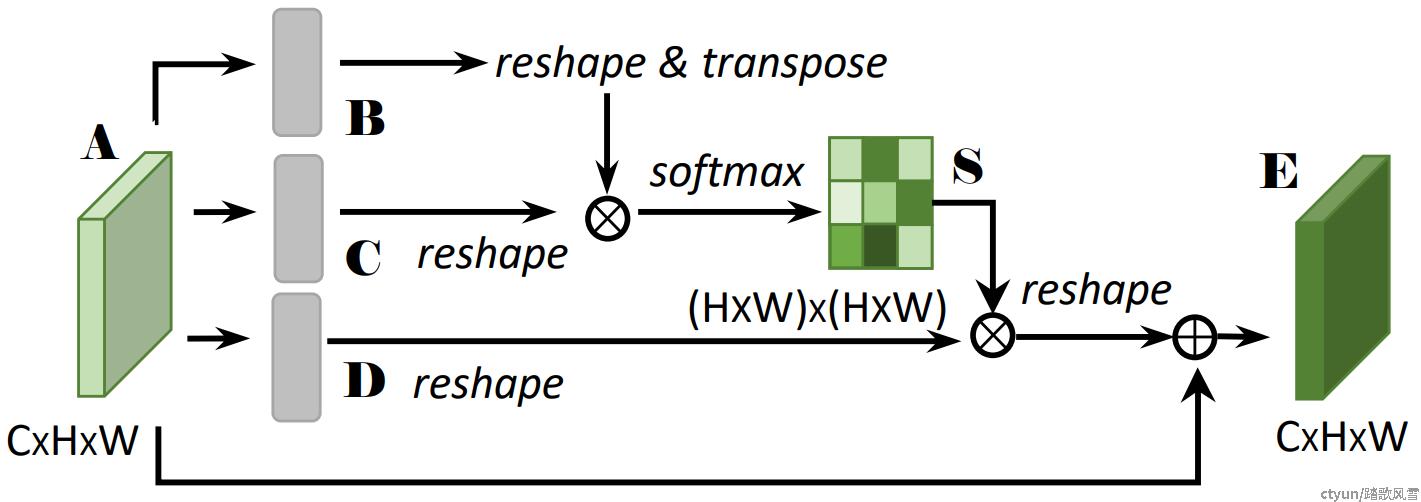
图2 空间注意力模块[3]
如图2所示, 形状为W×H×C的输入通过三个1×1卷积分别得到三个特征图,然后调整尺寸为C×N(N=W×H),对其中一个分支进行转置与另一分支相乘得到形状为N×N的空间注意力矩阵。空间注意力矩阵中的每一个元素sji如式1:
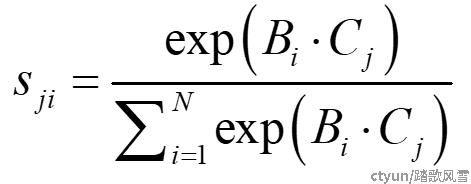 |
(式1) |
其中sji表示位置i对j的影响,Bi和Cj分别表示图中B和C分支卷积后得到的特征的元素。得到的最终特征E可以表示为式2:
| (式2) |
其中α为尺度因子,Di为图中D分支卷积得到的特征的元素,Aj为A的元素。
求出的空间注意力矩阵中,每行元素表示原特征图中所有位置对应某个像素的关系。使用softmax的作用是类似于分类,其结果表示该依赖关系的可信度,结果越大,表示可信度越强,说明依赖程度越强。将空间注意力与剩余一分支的原始特征相乘,即将所有位置的加权和更新原像素特征值。这一过程利用学习到的长距离依赖关系,作用于原始特征,选择性的加强局部特征的全局依赖关系。
Channel Attention Module
通道注意力模块的作用机理为:捕获任意两个通道特征的依赖关系,以加权求和的方式,对特定的特征进行更新,其权重由该两个通道的特征相似性所决定。具体表现为,如果该两通道具有相似信息,则可以相互促进得以改进。
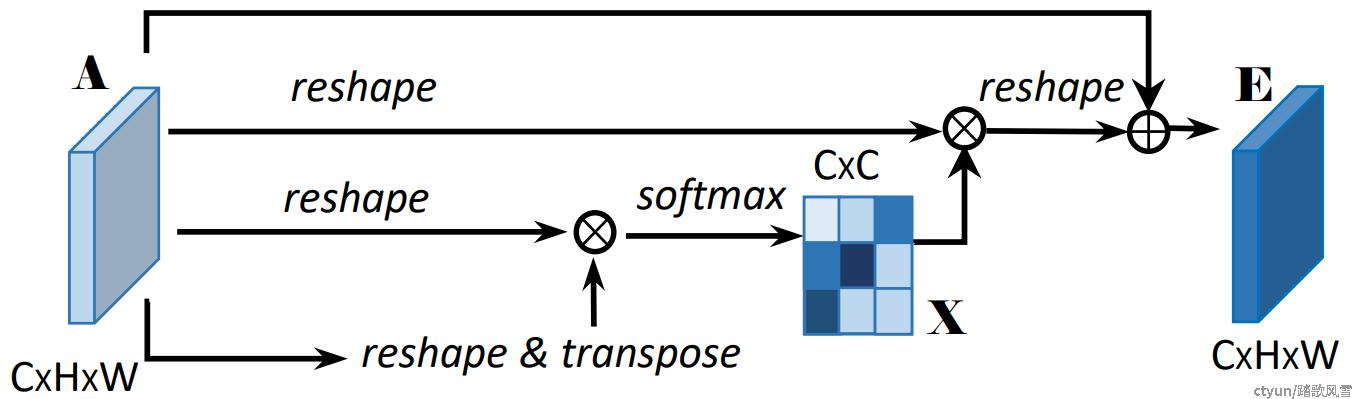
图3 通道注意力模块
如图3所示,形状为W×H×C的输入reshape,对其中一个分支进行转置与另一分支相乘得到形状为C×C的通道注意力矩阵。通道注意力矩阵中的每一个元素xji如式3:
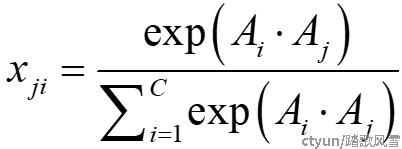 |
(式3) |
其中xji表示通道i对j的影响,Ai和Aj分别为用于得到通道注意力矩阵相乘前的两个特征的元素。得到的最终特征E可以表示为式4:
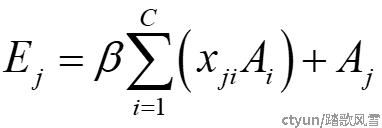 |
(式4) |
其中β为尺度因子。
求出的通道注意力矩阵的每一行计算的是某通道与其他通道的依赖性,通过使用softmax函数来计算最终的可信度,结果越大则可信度更高,依赖性也就越强。将attention与剩余一分支的原始特征相乘,对通道赋予不同的权重,提升了语义表达能力。
Summary
总的来说,由于卷积操作使用局部感受野进行特征提取,相同类别的物体可能会有不同的特征。这些不同导致了类内差异的不一致性并对识别的准确率造成影响。空间注意力模块对所有位置特征进行加权求和,以此来选择性地聚合各个位置的特征;通道注意力模块对所有通道特征进行选择,以此来强调某些相互依赖的通道特征。两个模块并行计算,在最后融合两个注意力模块的输出,最终提升特征表达能力。
References
[1] Han Zhang, Ian J. Goodfellow, Dimitris N. Metaxas, Augustus Odena. Self-attention generative adversarial networks[C]. International Conference on Machine Learning (ICML), 2019: 7354-7363.
[2] MA Bing , WANG Xiaoru, ZHANG Heng, et al. CBAM-GAN: Generative adversarial networks based on convolutional block attention module[C]. International Conference on Artificial Intelligence and Security(ICAIS). 2019 : 227-236.
[3] Fu J , Liu J , Tian H , et al. Dual attention network for scene segmentation[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020: 3146-3154.
