


与其他3A算法共享的数据处理步骤
EchoCanceller3::AnalyzeCapture
webrtc::EchoCanceller3::AnalyzeCapture(webrtc::AudioBuffer const&)
-->webrtc::(anonymous namespace)::DetectSaturation(rtc::ArrayView<float const, -4711l>)
该函数的输入参数如下:
| 参数名 | 类型 | 说明 |
|---|---|---|
| Capture | AudioBuffer* | 输入音频属性 |
该函数调用了DetectSaturation(),逐渐点判断各个采样点值是否在[-32700,32700]内,输出值为属性 saturated_microphone_signal_ 全频点范围内为false,其余为true;
AudioBuffer::SplitIntoFrequencyBands()
该函数调到了splitting_filter_->Analysis(), 这里将其分为频带
SplittingFilter类:该类能够将音频信号分割成2个或3个频带,并能将这些频带再合并成一个信号。构造该类时需要提供通道数、频带数和帧数。
该类提供了Analysis()和Synthesis()方法,用于进行信号的分析和合成操作。输入和输出信号都以ChannelBuffer的形式进行存储,对于不同的频带,使用ChannelBuffer数组进行存储。
三分频滤波器组类 class ThreeBandFilterBank
ThreeBandFilterBank 的类,用于执行三频带滤波操作。该滤波器是一种FIR滤波器,采用DCT调制,并根据Fredric J Harris在《Multirate Signal Processing for Communication Systems》中提出的方法进行设计。
这个滤波器将输入信号分为三个频带,其中低频带、中频带和高频带各自占据总频带的1/3。
该类提供了以下方法:
void ThreeBandFilterBank::Analysis
将大小为 kFullBandSize 的输入信号 in 进行分析,将其分为三个大小为 kSplitBandSize 的下采样频带,并存储在 out 参数中。
-
kFullBandSize:完整频带大小为480个采样点。 -
kSplitBandSize:每个频带的大小为kFullBandSize / kNumBands,即160个采样点。具体流程如下:
具体实现如下:
-
初始化输出为零。对于每个频带,将输出数组
out中的元素设置为零。 -
对于每个下采样索引downsampling_index进行以下操作:
-
下采样以形成滤波器的输入。使用一个大小为
kSplitBandSize的数组in_subsampled存储下采样后的信号。 -
对于每个输入偏移in_shift,进行以下操作:
-
选择滤波器,跳过零滤波器。根据
index的值判断是否为零滤波器,如果是,则跳过当前迭代。 -
获取滤波器系数和余弦调制数组,并获取分析过程中的状态数组。
-
进行滤波操作。使用
FilterCore()函数对输入信号in_subsampled进行滤波,得到下采样后的输出信号out_subsampled。 -
对于每个频带,进行以下操作:
-
对下采样后的输出信号
out_subsampled进行余弦调制,并累加到输出数组out的相应频带中。
-
-
-
void FilterCore()
-
FilterCore函数接受五个参数:-
filter:一个长度为kFilterSize的常量浮点数组,用作滤波器系数。 -
in:一个长度为ThreeBandFilterBank::kSplitBandSize的常量浮点数组,作为输入信号。 -
in_shift:一个整数值,表示输入信号的位移(shift)。 -
out:一个长度为ThreeBandFilterBank::kSplitBandSize的浮点数组,用于存储滤波后的输出信号。 -
state:一个长度为kMemorySize的浮点数组,用于存储先前的状态信息
用3个for循环分别处理[0,in_shift) [inshift,kFilterSize * kStride) [kFilterSize * kStride,kSplitBandSize),
copy函数将输入信号in中最新的kMemorySize个样本复制到状态数组state中,以更新当前的状态。 -
5.根据滤波器index选择dct调制
multi_channel_capture
分频处理后,在回声消除开启情况下,若Config中multi_channel_capture为false(默认值),将强制把capture_buffer通道设置为1
int AudioProcessingImpl::ProcessCaptureStreamLocked() {
...
if (submodules_.echo_controller && !multi_channel_capture) {
// Force down-mixing of the number of channels after the detection of
// capture signal saturation.
// TODO(peah): Look into ensuring that this kind of tampering with the
// AudioBuffer functionality should not be needed.
capture_buffer->set_num_channels(1);
}
...
}
// multi_channel_capture设置,Config中,默认值为false
struct RTC_EXPORT Config {
// Sets the properties of the audio processing pipeline.
struct RTC_EXPORT Pipeline {
// Maximum allowed processing rate used internally. May only be set to
// 32000 or 48000 and any differing values will be treated as 48000.
int maximum_internal_processing_rate = 48000;
// Allow multi-channel processing of render audio.
bool multi_channel_render = false;
// Allow multi-channel processing of capture audio when AEC3 is active
// or a custom AEC is injected..
bool multi_channel_capture = false;
} pipeline;
...
}
开启multi_channel_capture为True后对处理效果的影响,分处理效果及处理时间两方面。
处理效果:如下图,上面为singer,下面为mul,multi_channel_capture设置为true后,部分频段处理得更干净;
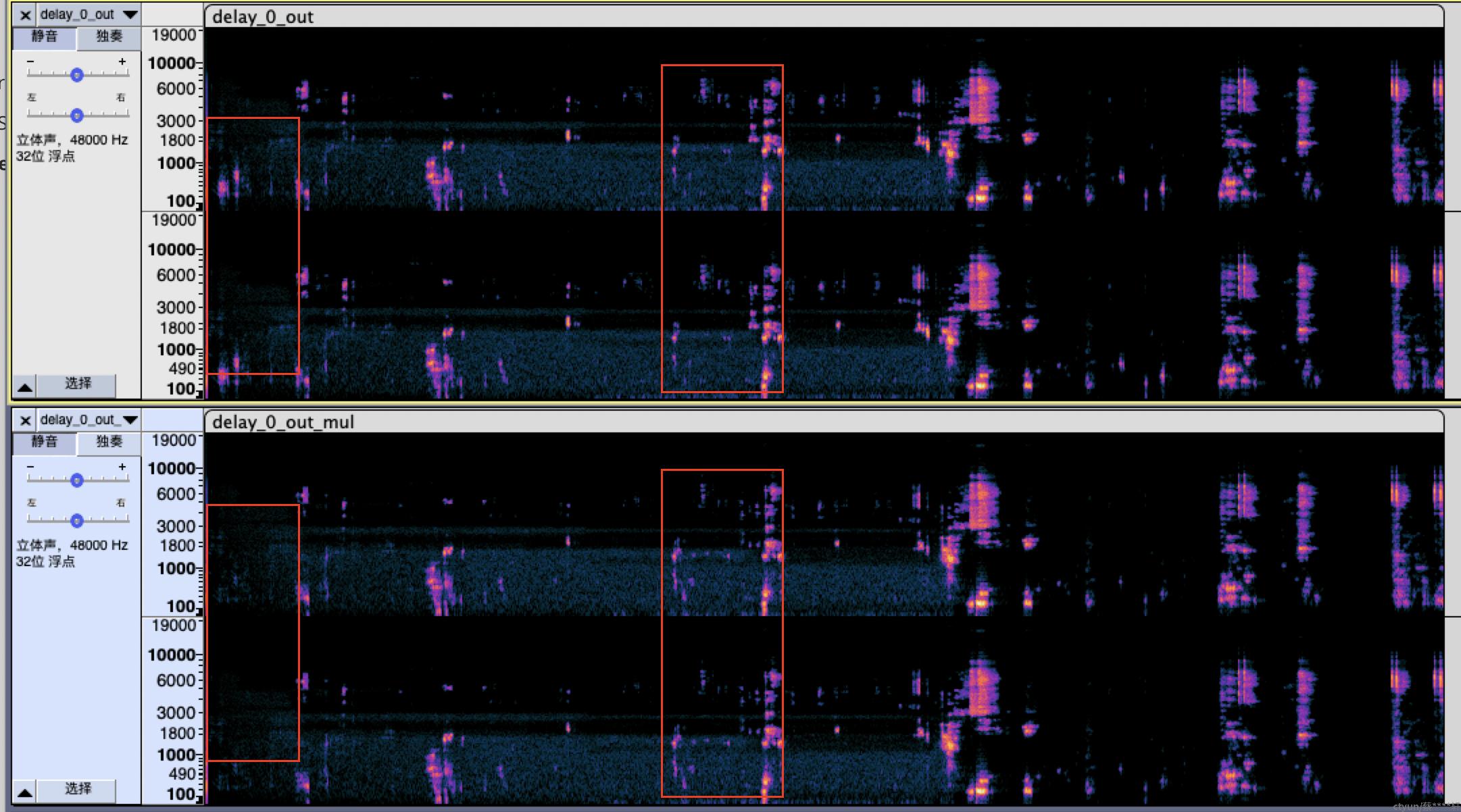
处理时间:
相同的处理数据下,开启avx2的情况下,multi_channel_capture设置为true处理时间为19-20s,相对应的,multi_channel_capture设置为false处理时间为14-15s,时间消耗比未开启增加1/3,开启sse及不开启指令加速的情况未测试;
