


人类主观评估语音质量时音频质量的“黄金标准”。传统音频评估指标需要参考干净的语音信号,这无法对真实的应用环境中的音频作出准确评估。因为真实应用中干净的语音信号难以获得。然而,传统的无参考方法与人类主观评估质量相关性很差,没有被广泛采用。本文介绍了来自微软的深度学习多阶段噪声抑制评估方法。该方法能够在无参考的情况下,与人类主观评估高度相关。首先介绍其基本原理,然后介绍具体的使用方法。
网络结构
模型的输入是Spectrogram,120个Mel波段在长度为9秒的剪辑上计算,在16kHz采样,帧大小为20毫秒,跳跃长度为10毫秒,输入尺寸为900 x 120。该模型的batch大小为32,使用Adam优化器和MSE损失函数。Encoder和Decoder均由6个具有PReLU激活函数的Conv2d块组成,旨在从输入特征中提取高维特征,降低分辨率。将频谱特征作为输入。LSTM 层隐藏大小为512,T-F核大小为3 ,跨度为 1*2 ,每个 Conv2d 或 ConvTranspose2d 层后面跟着一个batchnorm层。在最后一个 ConvTranspose2d层之后嵌入线性层以映射输出特征的复数比率掩码(CRM)。最后,CRM与输入 stft 谱图相乘得到干净的 stft 谱图,所有的激活函数都是PReLU。
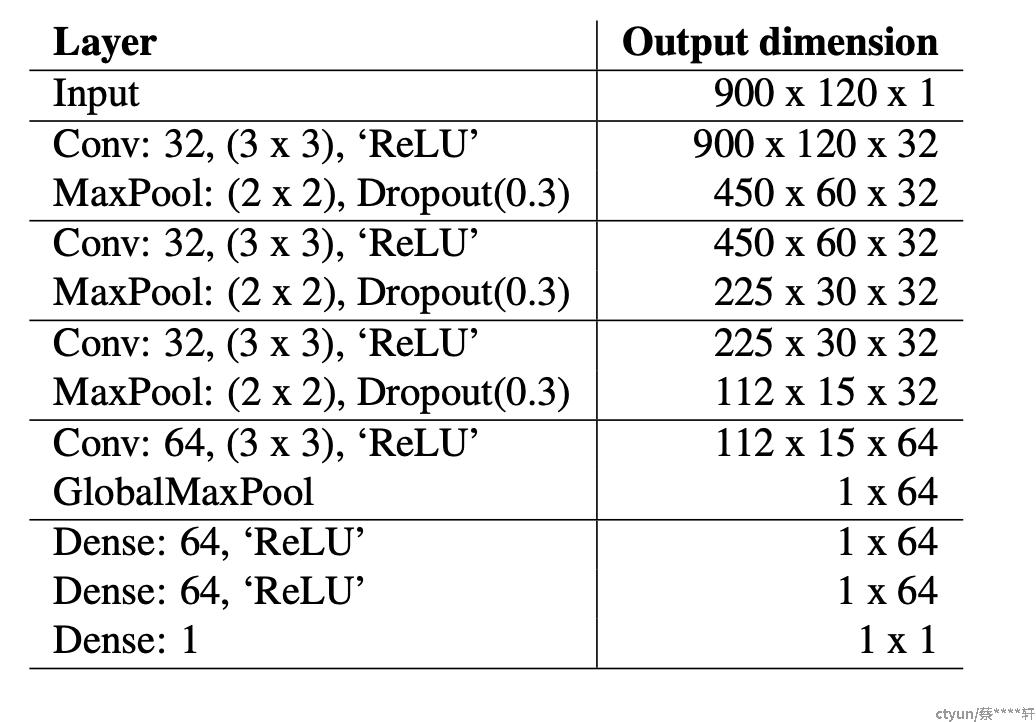
Batch标准化的作用?
批量标准化降低了低卷剪辑的预测准确性。主观评分对振幅低的剪辑倾向给予较低的评分。
评价方法
采用ITU-T P.835主观测试框架来衡量语音质量(SIG)、背景噪声质量(BAK)和整体音频质量(OVRL),评价均为0-5(5为最佳);
该模型对语音的评分与人类主观评分的相关性
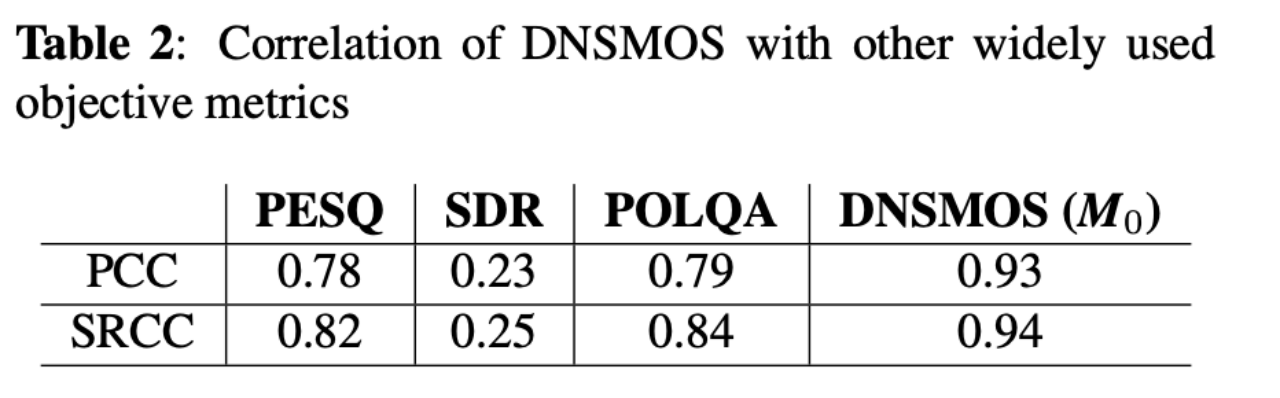
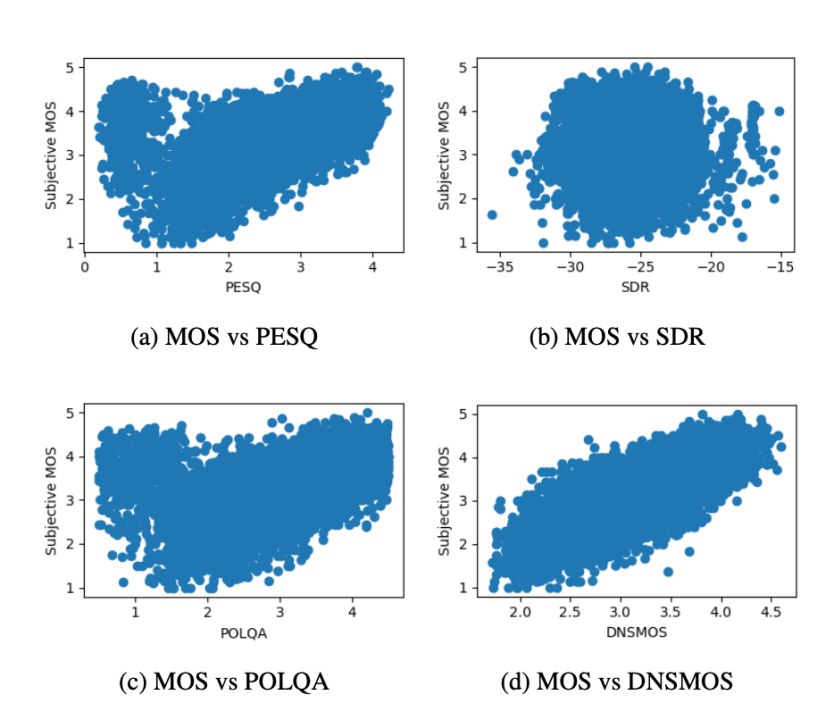
PCC:皮尔逊相关系数
SRCC:斯皮尔曼秩相关系数
使用注意事项
- 目前只支持单通道语音信号处理;
- 采样率支持16000Hz,其他采样率会被自动转化;
- 可选项-p,打开表明存在周围人说话干扰的情况下会惩罚,降低分数
- 可选项-p在代码上对分数的区别:1模型不同,2针对模型计算得到的原始分数,使用不同的多项式求解;
使用方法:
有两种使用DNSMOS的方式:
1.使用Web-API:
使用本地上传到此GitHub repo的模型进行本地评估。
要使用Web-API:请填写以下表格:https://forms.office.com/r/pRhyZ0mQy3 我们将向您发送您可以在dnsmos.py脚本中插入的AUTH_KEY。
示例命令:python dnsmos --testset_dir --method p835
2.使用本地评估方法:
git下载源码:https://github.com/microsoft/DNS-Challenge/tree/master/DNSMOS
运行dnsmos_local.py
计算常规MOS分数
python dnsmos_local.py -t C:\temp\SampleClips -o sample.csv
设置扬声器干扰惩罚,“-p”参数
python dnsmos_local.py -t C:\temp\SampleClips -o sample.csv -p
