全量微调
-
目标:调整预训练模型参数以适应目标任务的需求,通常需要使用目标数据进行微调。
-
思想:基于预训练语言模型,在小规模的任务特定文本上继续训练。
-
参数更新范围:预训练模型的全部参数都需要更新。
-
全量微调量:取决于预训练语料库和目标任务语料库的相似性,相似则少,反之则多。
-
参考github.com/FlagAlpha/Llama2-Chinese项目
-
训练数据集 github.com/FlagAlpha/Llama2-Chinese/blob/main/data/train_sft.csv
-
介绍:每个csv文件中包含一列“text”,每一行为一个训练样例
-
"<s>Human: "+问题+"\n</s><s>Assistant: "+答案
-
实现代码 github.com/FlagAlpha/Llama2-Chinese/blob/main/train/sft/finetune_clm.py
#!/usr/bin/env python
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...) on a text file or a dataset.
Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
huggingface.co/models?filter=text-generation
"""
# You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments.
import logging
import math
import os
import sys
import random
from dataclasses import dataclass, field
from itertools import chain
import deepspeed
from typing import Optional,List,Union
import datasets
import evaluate
import torch
from datasets import load_dataset
from peft import ( # noqa: E402
LoraConfig,
PeftModel,
get_peft_model,
get_peft_model_state_dict,
prepare_model_for_int8_training,
#prepare_model_for_kbit_training,
set_peft_model_state_dict,
)
import transformers
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
from transformers import (
CONFIG_MAPPING,
MODEL_FOR_CAUSAL_LM_MAPPING,
AutoConfig,
AutoModelForCausalLM,
AutoTokenizer,
TrainerCallback,
TrainerState,
TrainerControl,
HfArgumentParser,
Trainer,
TrainingArguments,
default_data_collator,
BitsAndBytesConfig,
is_torch_tpu_available,
set_seed,
)
from transformers.testing_utils import CaptureLogger
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
import pdb
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
# check_min_version("4.27.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
logger = logging.getLogger(__name__)
MODEL_CONFIG_CLASSES = list(MODEL_FOR_CAUSAL_LM_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
)
},
)
model_type: Optional[str] = field(
default=None,
metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
)
config_overrides: Optional[str] = field(
default=None,
metadata={
"help": (
"Override some existing default config settings when a model is trained from scratch. Example: "
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
)
},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)
torch_dtype: Optional[str] = field(
default=None,
metadata={
"help": (
"Override the default `torch.dtype` and load the model under this dtype. If `auto` is passed, the "
"dtype will be automatically derived from the model's weights."
),
"choices": ["auto", "bfloat16", "float16", "float32"],
},
)
def __post_init__(self):
if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
raise ValueError(
"--config_overrides can't be used in combination with --config_name or --model_name_or_path"
)
#if type(self.target_modules)==str:
# self.target_modules = self.target_modules.split(',')
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
train_on_inputs: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_files: Optional[List[str]] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_files: Optional[List[str]] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
streaming: bool = field(default=False, metadata={"help": "Enable streaming mode"})
block_size: Optional[int] = field(
default=None,
metadata={
"help": (
"Optional input sequence length after tokenization. "
"The training dataset will be truncated in block of this size for training. "
"Default to the model max input length for single sentence inputs (take into account special tokens)."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
validation_split_percentage: Optional[int] = field(
default=5,
metadata={
"help": "The percentage of the train set used as validation set in case there's no validation split"
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
keep_linebreaks: bool = field(
default=True, metadata={"help": "Whether to keep line breaks when using TXT files or not."}
)
def __post_init__(self):
if self.streaming:
require_version("datasets>=2.0.0", "The streaming feature requires `datasets>=2.0.0`")
if self.dataset_name is None and self.train_files is None and self.validation_files is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_files is not None:
extension = self.train_files[0].split(".")[-1]
assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
if self.validation_files is not None:
extension = self.validation_files[0].split(".")[-1]
assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
# pdb.set_trace()
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_clm", model_args, data_args)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if True:
data_files = {}
dataset_args = {}
if data_args.train_files is not None:
data_files["train"] = data_args.train_files
if data_args.validation_files is not None:
data_files["validation"] = data_args.validation_files
extension = (
data_args.train_files[0].split(".")[-1]
if data_args.train_files is not None
else data_args.validation_files.split(".")[-1]
)
if extension == "txt":
extension = "text"
dataset_args["keep_linebreaks"] = data_args.keep_linebreaks
raw_datasets = load_dataset(
extension,
data_files=data_files,
cache_dir=os.path.join(training_args.output_dir,'dataset_cache'),
use_auth_token=True if model_args.use_auth_token else None,
**dataset_args,
)
# If no validation data is there, validation_split_percentage will be used to divide the dataset.
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
extension,
data_files=data_files,
split=f"train[:{data_args.validation_split_percentage}%]",
cache_dir=model_args.cache_dir,
use_auth_token=True if model_args.use_auth_token else None,
**dataset_args,
)
raw_datasets["train"] = load_dataset(
extension,
data_files=data_files,
split=f"train[{data_args.validation_split_percentage}%:]",
cache_dir=model_args.cache_dir,
use_auth_token=True if model_args.use_auth_token else None,
**dataset_args,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# huggingface.co/docs/datasets/loading_datasets.html.
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config_kwargs = {
"cache_dir": model_args.cache_dir,
"revision": model_args.model_revision,
"use_auth_token": True if model_args.use_auth_token else None,
}
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.config_overrides is not None:
logger.info(f"Overriding config: {model_args.config_overrides}")
config.update_from_string(model_args.config_overrides)
logger.info(f"New config: {config}")
tokenizer_kwargs = {
"cache_dir": model_args.cache_dir,
"use_fast": model_args.use_fast_tokenizer,
"revision": model_args.model_revision,
"use_auth_token": True if model_args.use_auth_token else None,
"padding_side":'left'
}
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
tokenizer.pad_token = tokenizer.eos_token
if model_args.model_name_or_path:
torch_dtype = (
model_args.torch_dtype
if model_args.torch_dtype in ["auto", None]
else getattr(torch, model_args.torch_dtype)
)
print(torch_dtype)
torch_dtype = torch.float16
model = AutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
torch_dtype=torch_dtype,
device_map={"": int(os.environ.get("LOCAL_RANK") or 0)}
)
# model = prepare_model_for_int8_training(model, output_embedding_layer_name="embed_out", layer_norm_names=[])
else:
model = AutoModelForCausalLM.from_config(config)
n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())
logger.info(f"Training new model from scratch - Total size={n_params/2**20:.2f}M params")
# We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
# on a small vocab and want a smaller embedding size, remove this test.
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
model.resize_token_embeddings(len(tokenizer))
# Preprocessing the datasets.
# First we tokenize all the texts.
if training_args.do_train:
column_names = list(raw_datasets["train"].features)
else:
column_names = list(raw_datasets["validation"].features)
train_on_inputs = True
if len(column_names)==1:
text_column_name = "text" if "text" in column_names else column_names[0]
elif len(column_names)==2:
input_column_name = 'input' if 'input' in column_names else column_names[0]
target_column_name = 'target' if 'target' in column_names else column_names[0]
train_on_inputs=False
else:
raise ValueError('输入文件列数不对')
print('train_on_inputs',train_on_inputs)
# since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function
tok_logger = transformers.utils.logging.get_logger("transformers.tokenization_utils_base")
def tokenize_function(examples):
with CaptureLogger(tok_logger) as cl:
output = tokenizer([ item for item in examples[text_column_name]],truncation=True,max_length=data_args.block_size,padding=False,return_tensors=None)
output['labels'] = output['input_ids'].copy()
return output
def tokenize(prompt):
result = tokenizer(prompt,truncation=True,max_length=data_args.block_size,padding=False,return_tensors=None)
result["labels"] = result["input_ids"].copy()
return result
def generate_and_tokenize_prompt(data_point):
input_text = data_point[input_column_name]
target_text = data_point[target_column_name]
full_prompt = input_text+target_text
tokenized_full_prompt = tokenize(full_prompt)
if not train_on_inputs:
user_prompt = input_text
tokenized_user_prompt = tokenize(user_prompt)
user_prompt_len = len(tokenized_user_prompt["input_ids"])
tokenized_full_prompt["labels"] = [
-100
] * user_prompt_len + tokenized_full_prompt["labels"][
user_prompt_len:
]
return tokenized_full_prompt
with training_args.main_process_first(desc="dataset map tokenization"):
if not data_args.streaming:
tokenized_datasets = raw_datasets.map(
tokenize_function if train_on_inputs==True else generate_and_tokenize_prompt,
batched=True if train_on_inputs==True else False,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on dataset",
)
else:
tokenized_datasets = raw_datasets.map(
tokenize_function if train_on_inputs==True else generate_and_tokenize_prompt,
batched=True if train_on_inputs==True else False,
remove_columns=column_names,
)
if data_args.block_size is None:
block_size = tokenizer.model_max_length
if block_size > 2048:
block_size = 2048
else:
block_size = min(data_args.block_size, tokenizer.model_max_length)
if training_args.do_train:
if "train" not in tokenized_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = tokenized_datasets["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
train_dataset = train_dataset.shuffle(seed=training_args.seed)
if training_args.do_eval:
if "validation" not in tokenized_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = tokenized_datasets["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
def preprocess_logits_for_metrics(logits, labels):
if isinstance(logits, tuple):
# Depending on the model and config, logits may contain extra tensors,
# like past_key_values, but logits always come first
logits = logits[0]
return logits.argmax(dim=-1)
metric = evaluate.load("accuracy.py")
def compute_metrics(eval_preds):
preds, labels = eval_preds
# preds have the same shape as the labels, after the argmax(-1) has been calculated
# by preprocess_logits_for_metrics but we need to shift the labels
labels = labels[:, 1:].reshape(-1)
# .reshape(-1)
preds = preds[:, :-1].reshape(-1)
# .reshape(-1)
# print(labels.shape)
# true_predictions = [
# [p for (p, l) in zip(pred, gold_label) if l != -100]
# for pred, gold_label in zip(preds, labels)
# ]
# true_labels = [
# [l for (p, l) in zip(pred, gold_label) if l != -100]
# for pred, gold_label in zip(preds, labels)
# ]
# preds = np.array(true_predictions).reshape(-1)
# labels = np.array(true_labels).reshape(-1)
return metric.compute(predictions=preds, references=labels)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
# Data collator will default to DataCollatorWithPadding, so we change it.
data_collator=transformers.DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
),
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None,
preprocess_logits_for_metrics=preprocess_logits_for_metrics if training_args.do_eval and not is_torch_tpu_available()else None,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
print(training_args.local_rank,'start train')
if torch.__version__ >= "2" and sys.platform != "win32":
model = torch.compile(model)
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
try:
perplexity = math.exp(metrics["eval_loss"])
except OverflowError:
perplexity = float("inf")
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
- 全量参数微调脚本github.com/FlagAlpha/Llama2-Chinese/blob/main/train/sft/finetune.sh
output_model=./finetune_output # 设置输出模型的路径为"./finetune_output"
# 如果输出模型的目录不存在,则创建该目录
if [ ! -d ${output_model} ];then
mkdir ${output_model}
fi
cp ./finetune.sh ${output_model} # 将"./finetune.sh"复制到输出模型的目录
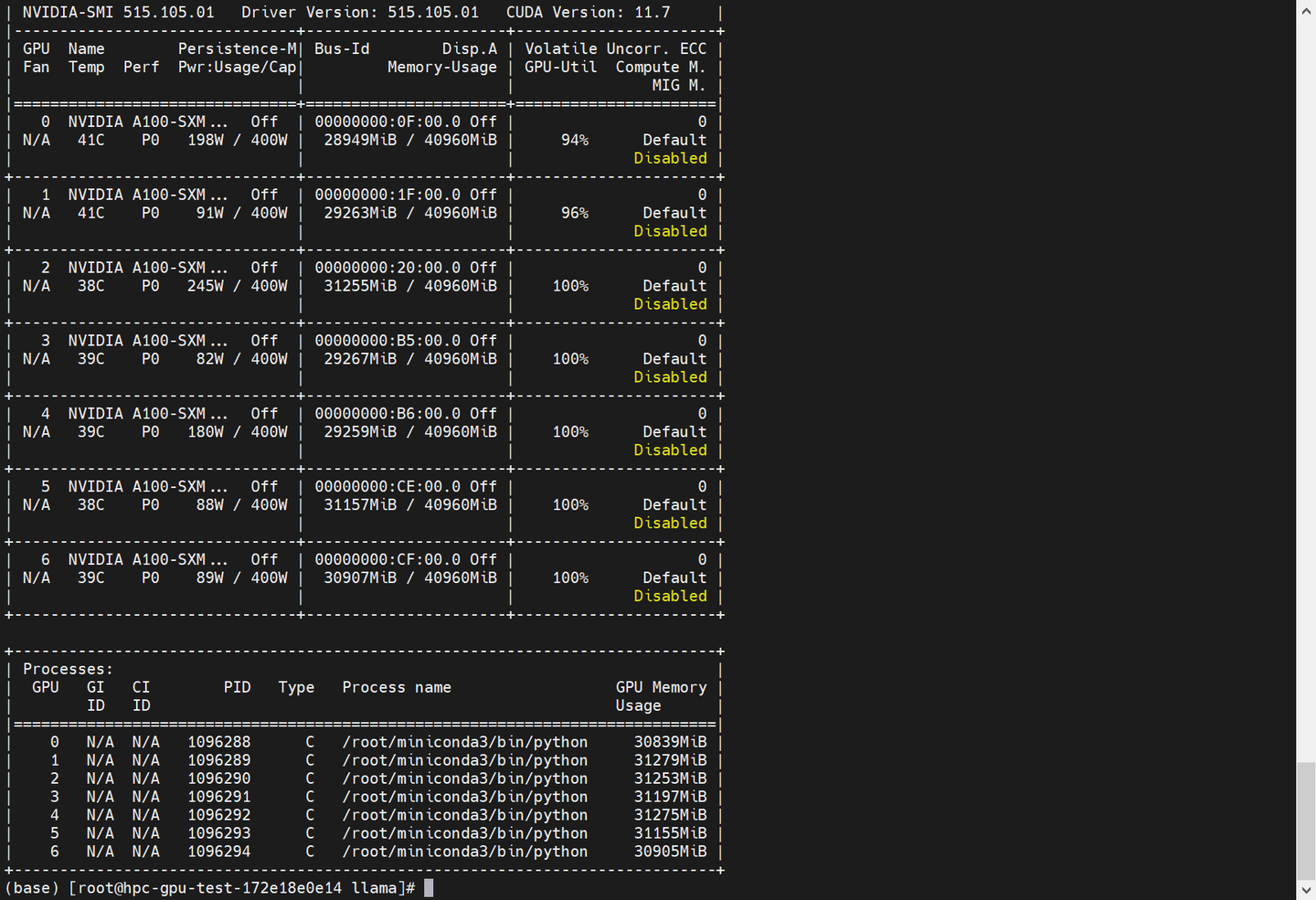
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6 deepspeed --num_gpus 7 finetune_clm.py \ # 使用CUDA设备0到6(共7个设备)运行deepspeed微调脚本
--model_name_or_path /root/llama/correspond_output_dir \ # 设置模型的名称或路径为"/root/llama/correspond_output_dir"
--per_device_train_batch_size 1 \ # 每个设备的训练批次大小为1
--per_device_eval_batch_size 1 \ # 每个设备的评估批次大小为1
--train_files ./finetune_data/train_sft.csv \ # 设置训练文件的路径
--validation_files ./finetune_data/dev_sft.csv \ # 设置验证文件的路径为"./finetune_data/dev_sft.csv"和"./finetune_data/dev_sft_sharegpt.csv"
./finetune_data/dev_sft_sharegpt.csv \
--do_train \ # 进行训练
--do_eval \ # 进行评估
--output_dir ${output_model} \ # 设置输出目录为之前定义的输出模型目录
--evaluation_strategy steps \ # 设置评估策略为"steps",即按步骤进行评估
--max_eval_samples 800 \ # 最大评估样本数为800
--learning_rate 1e-4 \ # 学习率为0.0001
--gradient_accumulation_steps 8 \ # 梯度累积步骤数为8
--num_train_epochs 10 \ # 训练周期数为10
--warmup_steps 40 \ # 预热步骤数为40
--logging_dir ${output_model}/logs \ # 设置日志目录为输出模型目录下的"logs"子目录
--logging_strategy steps \ # 设置日志策略为"steps",即按步骤记录日志
--logging_steps 10 \ # 每10步记录一次日志
--save_strategy steps \ # 保存策略为"steps",即按步骤保存模型
--preprocessing_num_workers 10 \ # 预处理工作器数量为10
--save_steps 800 \ # 每800步保存一次模型
--max_steps 800 \ # 最大训练步数为800
--eval_steps 800 \ # 每800步进行一次评估
--save_total_limit 2000 \ # 保存的总限制数为2000,超过这个数量后,将删除旧的检查点以释放空间
--seed 42 \ # 设置随机种子为42,以确保实验的可重复性
--disable_tqdm false \ # 不禁用tqdm,即显示训练进度条
--block_size 2048 \ # 设置块大小为2048,这是模型接受的最大序列长度,超过这个长度的序列将被截断或填充
--report_to tensorboard \ # 将日志报告到tensorboard,这是一个可视化训练和评估指标的工具
--overwrite_output_dir \ # 覆盖输出目录,如果输出目录已存在并包含模型检查点,则删除它们并重新开始训练
--deepspeed scripts/training/ds_zero2_no_offload.json \ # 使用deepspeed进行训练,并使用"scripts/training/ds_zero2_no_offload.json"配置文件,该文件定义了训练的一些参数和策略
--ignore_data_skip true \ # 在恢复训练时决定是否跳过之前已经完成的 epochs 和 batches,以便数据加载能够和之前的训练阶段保持一致
--bf16 \ # 使用deepspeed进行训练,并使用"scripts/training/ds_zero2_no_offload.json"配置文件,该文件定义了训练的一些参数和策略
--gradient_checkpointing \ # 使用梯度检查点,这可以在一定程度上减少内存使用,但会增加一些计算开销
--bf16_full_eval \ # 在评估时也使用bf16混合精度
--ddp_timeout 18000000 \ # 设置分布式数据并行(DDP)的超时时间为18000000毫秒
| tee -a ${output_model}/train.log # 将训练日志同时输出到屏幕和文件"${output_model}/train.log
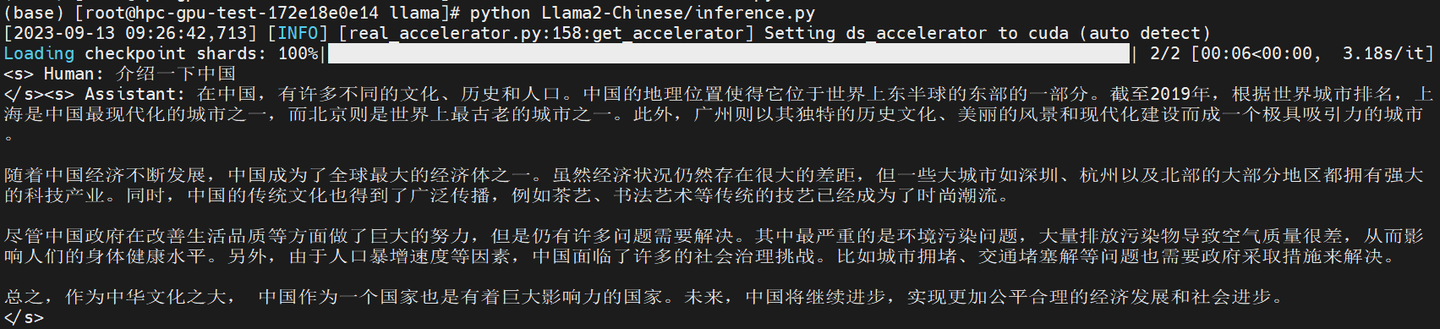
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/root/llama/finetune_output/checkpoint-800',device_map='auto',torch_dtype=torch.float16)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('/root/llama/finetune_output/checkpoint-800',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
P tuning微调
-
目标:通过优化输入提示(input prompt)而非修改模型参数来适应特定任务。
-
思想:利用很少的连续自由参数作为预训练语言模型输入的提示,通过在嵌入式输入中插入可训练变量来学习连续的提示。
-
因为提示构造的目的是找到一种方法,是LM能够有效地执行任务,而不是供人类使用,所以没有必要将提示限制为人类可解释的自然语言。prompt有自己的参数,这些参数根据目标下游任务的训练数据进行调优。
-
参数更新范围:输入提示(virtual token),即很少的连续自由参数需要更新。
-
训练数据集
-
来源:standford的github.com/tatsu-lab/stanford_alpaca项目,提供了廉价的对llama模型微调方法——利用openai提供的gpt模型api生成质量较高的instruct tuning数据(仅52k),并且基于这些数据微调模型。
-
在prompt设计上,精调以及预测时采用的都是原版stanford_alpaca不带input的模版。对于包含input字段的数据,采用f"{instruction}+\n+{input}"的形式进行拼接
-
英文:github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
-
中文:github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
-
参考github.com/liguodongiot/llm-action/blob/main/train/peft/clm/peft_p_tuning_clm.ipynb项目
-
基于github.com/ymcui/Chinese-LLaMA-Alpaca-2/blob/main/scripts/training/run_clm_sft_with_peft.py修改代码
# 首先去掉Lora部分代码,添加实现ptuning的peft相关库
from peft import (
get_peft_config,
TaskType,
get_peft_model,
PeftModel,
get_peft_model_state_dict,
set_peft_model_state_dict,
PromptEncoderConfig,
)
# 然后创建peft配置,即创建ptuning微调方法的相关配置
peft_config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=20, encoder_hidden_size=128)
#!/usr/bin/env python
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...) on a text file or a dataset.
Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
huggingface.co/models?filter=text-generation
"""
# You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments.
import logging
import math
import os
import sys
from dataclasses import dataclass, field
from typing import Optional
from pathlib import Path
import datasets
import torch
from build_dataset import build_instruction_dataset, DataCollatorForSupervisedDataset
import transformers
from transformers import (
CONFIG_MAPPING,
AutoConfig,
AutoModelForCausalLM,
LlamaForCausalLM,
LlamaTokenizer,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import send_example_telemetry
from transformers.utils.versions import require_version
from peft import (
get_peft_config,
TaskType,
get_peft_model,
PeftModel,
get_peft_model_state_dict,
set_peft_model_state_dict,
PromptEncoderConfig,
)
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
class SavePeftModelCallback(transformers.TrainerCallback):
def save_model(self, args, state, kwargs):
if state.best_model_checkpoint is not None:
checkpoint_folder = os.path.join(state.best_model_checkpoint, "sft_ptuning_model")
else:
checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
peft_model_path = os.path.join(checkpoint_folder, "sft_ptuning_model")
kwargs["model"].save_pretrained(peft_model_path)
kwargs["tokenizer"].save_pretrained(peft_model_path)
def on_save(self, args, state, control, **kwargs):
self.save_model(args, state, kwargs)
return control
def on_train_end(self, args, state, control, **kwargs):
peft_model_path = os.path.join(args.output_dir, "sft_ptuning_model")
kwargs["model"].save_pretrained(peft_model_path)
kwargs["tokenizer"].save_pretrained(peft_model_path)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
)
},
)
tokenizer_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The tokenizer for weights initialization.Don't set if you want to train a model from scratch."
)
},
)
config_overrides: Optional[str] = field(
default=None,
metadata={
"help": (
"Override some existing default config settings when a model is trained from scratch. Example: "
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
)
},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)
torch_dtype: Optional[str] = field(
default=None,
metadata={
"help": (
"Override the default `torch.dtype` and load the model under this dtype. If `auto` is passed, the "
"dtype will be automatically derived from the model's weights."
),
"choices": ["auto", "bfloat16", "float16", "float32"],
},
)
def __post_init__(self):
if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
raise ValueError(
"--config_overrides can't be used in combination with --config_name or --model_name_or_path"
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_dir: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
validation_split_percentage: Optional[float] = field(
default=0.05,
metadata={
"help": "The percentage of the train set used as validation set in case there's no validation split"
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
keep_linebreaks: bool = field(
default=True, metadata={"help": "Whether to keep line breaks when using TXT files or not."}
)
data_cache_dir: Optional[str] = field(default=None, metadata={"help": "The datasets processed stored"})
max_seq_length: Optional[int] = field(default=1024)
@dataclass
class MyTrainingArguments(TrainingArguments):
trainable : Optional[str] = field(default="q_proj,v_proj")
#lora_rank : Optional[int] = field(default=8)
#lora_dropout : Optional[float] = field(default=0.1)
#lora_alpha : Optional[float] = field(default=32.)
#modules_to_save : Optional[str] = field(default=None)
peft_path : Optional[str] = field(default=None)
flash_attn : Optional[bool] = field(default=False)
logger = logging.getLogger(__name__)
def main():
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, MyTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if training_args.flash_attn:
from flash_attn_patch import replace_llama_attn_with_flash_attn
replace_llama_attn_with_flash_attn()
send_example_telemetry("run_clm", model_args, data_args)
# Setup logging
logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO, # if training_args.local_rank in [-1, 0] else logging.WARN,
handlers=[logging.StreamHandler(sys.stdout)],)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# transformers.tokenization_utils.logging.set_verbosity_warning()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
config_kwargs = {
"cache_dir": model_args.cache_dir,
"revision": model_args.model_revision,
"use_auth_token": True if model_args.use_auth_token else None,
}
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.config_overrides is not None:
logger.info(f"Overriding config: {model_args.config_overrides}")
config.update_from_string(model_args.config_overrides)
logger.info(f"New config: {config}")
tokenizer_kwargs = {
"cache_dir": model_args.cache_dir,
"use_fast": model_args.use_fast_tokenizer,
"revision": model_args.model_revision,
"use_auth_token": True if model_args.use_auth_token else None,
}
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.tokenizer_name_or_path:
tokenizer = LlamaTokenizer.from_pretrained(model_args.tokenizer_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if (len(tokenizer)) != 55296:
raise ValueError(f"The vocab size of the tokenizer should be 55296, but found {len(tokenizer)}.\n"
"Please use Chinese-LLaMA-2 tokenizer.")
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
eval_dataset=None
train_dataset = None
if training_args.do_train:
with training_args.main_process_first(desc="loading and tokenization"):
path = Path(data_args.dataset_dir)
files = [os.path.join(path,file.name) for file in path.glob("*.json")]
logger.info(f"Training files: {' '.join(files)}")
train_dataset = build_instruction_dataset(
data_path=files,
tokenizer=tokenizer,
max_seq_length=data_args.max_seq_length,
data_cache_dir = None,
preprocessing_num_workers = data_args.preprocessing_num_workers)
logger.info(f"Num train_samples {len(train_dataset)}")
logger.info("Training example:")
logger.info(tokenizer.decode(train_dataset[0]['input_ids']))
if training_args.do_eval:
with training_args.main_process_first(desc="loading and tokenization"):
files = [data_args.validation_file]
logger.info(f"Evaluation files: {' '.join(files)}")
eval_dataset = build_instruction_dataset(
data_path=files,
tokenizer=tokenizer,
max_seq_length=data_args.max_seq_length,
data_cache_dir = None,
preprocessing_num_workers = data_args.preprocessing_num_workers)
logger.info(f"Num eval_samples {len(eval_dataset)}")
logger.info("Evaluation example:")
logger.info(tokenizer.decode(eval_dataset[0]['input_ids']))
torch_dtype = (
model_args.torch_dtype
if model_args.torch_dtype in ["auto", None]
else getattr(torch, model_args.torch_dtype)
)
device_map = {"":int(os.environ.get("LOCAL_RANK") or 0)}
model = LlamaForCausalLM.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
device_map=device_map
)
model.config.use_cache = False
model_vocab_size = model.get_input_embeddings().weight.shape[0]
logger.info(f"Model vocab size: {model_vocab_size}")
logger.info(f"len(tokenizer):{len(tokenizer)}")
if model_vocab_size != len(tokenizer):
logger.info(f"Resize model vocab size to {len(tokenizer)}")
model.resize_token_embeddings(len(tokenizer))
if training_args.peft_path is not None:
logger.info("Peft from pre-trained model")
model = PeftModel.from_pretrained(model, training_args.peft_path, device_map=device_map)
else:
logger.info("Init new peft model")
#target_modules = training_args.trainable.split(',')
#modules_to_save = training_args.modules_to_save
#if modules_to_save is not None:
# modules_to_save = modules_to_save.split(',')
#lora_rank = training_args.lora_rank
#lora_dropout = training_args.lora_dropout
#lora_alpha = training_args.lora_alpha
#logger.info(f"target_modules: {target_modules}")
#logger.info(f"lora_rank: {lora_rank}")
peft_config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=20, encoder_hidden_size=128)
#LoraConfig(
# task_type=TaskType.CAUSAL_LM,
# target_modules=target_modules,
# inference_mode=False,
# r=lora_rank, lora_alpha=lora_alpha,
# lora_dropout=lora_dropout,
# modules_to_save=modules_to_save)
model = get_peft_model(model, peft_config)
if training_args.gradient_checkpointing and \
(not model.modules_to_save or 'embed_tokens' not in model.modules_to_save):
# enable requires_grad to avoid exception during backward pass when using gradient_checkpoint without tuning embed.
if hasattr(model.base_model, "enable_input_require_grads"):
model.base_model.enable_input_require_grads()
elif hasattr(model.base_model, "get_input_embeddings"):
def make_inputs_require_grad(_module, _input, _output):
_output.requires_grad_(True)
model.base_model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
#model.base_model.tie_weights()
model.print_trainable_parameters()
#logger.info(f"model.modules_to_save: {model.modules_to_save}")
#old_state_dict = model.state_dict
#model.state_dict = (
# lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())
#).__get__(model, type(model))
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.add_callback(SavePeftModelCallback)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
metrics["train_samples"] = len(train_dataset)
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
metrics["eval_samples"] =len(eval_dataset)
try:
perplexity = math.exp(metrics["eval_loss"])
except OverflowError:
perplexity = float("inf")
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if __name__ == "__main__":
main()
- 训练脚本run_sft_test_ptuning.sh
lr=1e-4 # 设置学习率为0.0001
pretrained_model=/root/llama/correspond_output_dir # 设置学习率为0.0001
chinese_tokenizer_path=/root/llama/correspond_output_dir # 设置中文分词器的路径
dataset_dir=data_pt # 设置数据集目录
per_device_train_batch_size=1
per_device_eval_batch_size=1
gradient_accumulation_steps=8
max_seq_length=512 # 设置最大序列长度为512,超过这个长度的序列将被截断或填充
output_dir=ptuning_output # 设置输出目录
validation_file=data_pt/alpaca_data_zh_51k.json # 设置验证文件的路径
training_steps=6000 # 训练步数为6000
deepspeed_config_file=scripts/training/ds_zero2_no_offload.json # 设置deepspeed配置文件
torchrun --nnodes 1 --nproc_per_node 7 scripts/training/run_clm_sft_with_ptuning.py \
--deepspeed ${deepspeed_config_file} \
--model_name_or_path ${pretrained_model} \
--tokenizer_name_or_path ${chinese_tokenizer_path} \
--dataset_dir ${dataset_dir} \
--per_device_train_batch_size ${per_device_train_batch_size} \
--per_device_eval_batch_size ${per_device_eval_batch_size} \
--do_train \
--do_eval \
--eval_steps 6000 \
--seed $RANDOM \
--fp16 \ # 是否使用16位浮点数(fp16)
--num_train_epochs 1 \
--lr_scheduler_type cosine \ # 一个学习率调度器的类型,cosine说明使用余弦退火策略来调整学习率。这种策略会在训练过程中周期性地调整学习率。余弦退火调度器会在每个周期开始时设置一个较大的学习率,然后在该周期内逐渐降低学习率,直到接近0。然后,在下一个周期开始时,学习率又会被重新设置为一个较大的值。这种策略的优点是它可以帮助模型在训练初期快速收敛,同时在训练后期通过降低学习率来微调模型参数12。
--learning_rate ${lr} \
--warmup_ratio 0.03 \ # 一个预热步骤的参数,预热步骤中使用的学习率非常低,然后在预热步骤之后,会使用“常规”学习率或学习率调度器。主要目的是为了防止训练初期由于学习率过大而导致的训练不稳定,通过在训练初期使用较小的学习率,可以使模型在参数空间中进行更稳定的探索,从而有助于找到更好的局部最优解。
--weight_decay 0 \ # 一个正则化技术,最小化一个损失函数,该函数包括主要的损失函数和权重的L2范数的惩罚,weight_decay决定了惩罚的强度
--logging_strategy steps \
--logging_steps 10 \
--save_strategy steps \
--save_total_limit 3 \
--evaluation_strategy steps \
--save_steps 6000 \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--preprocessing_num_workers 8 \
--max_steps ${training_steps} \
--max_seq_length ${max_seq_length} \
--output_dir ${output_dir} \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \ # 设置是否在第一步(global_step)进行日志记录和评估,能够更早地观察模型的表现。
--torch_dtype float16 \
--validation_file ${validation_file} \
| tee -a ${output_dir}/train.log
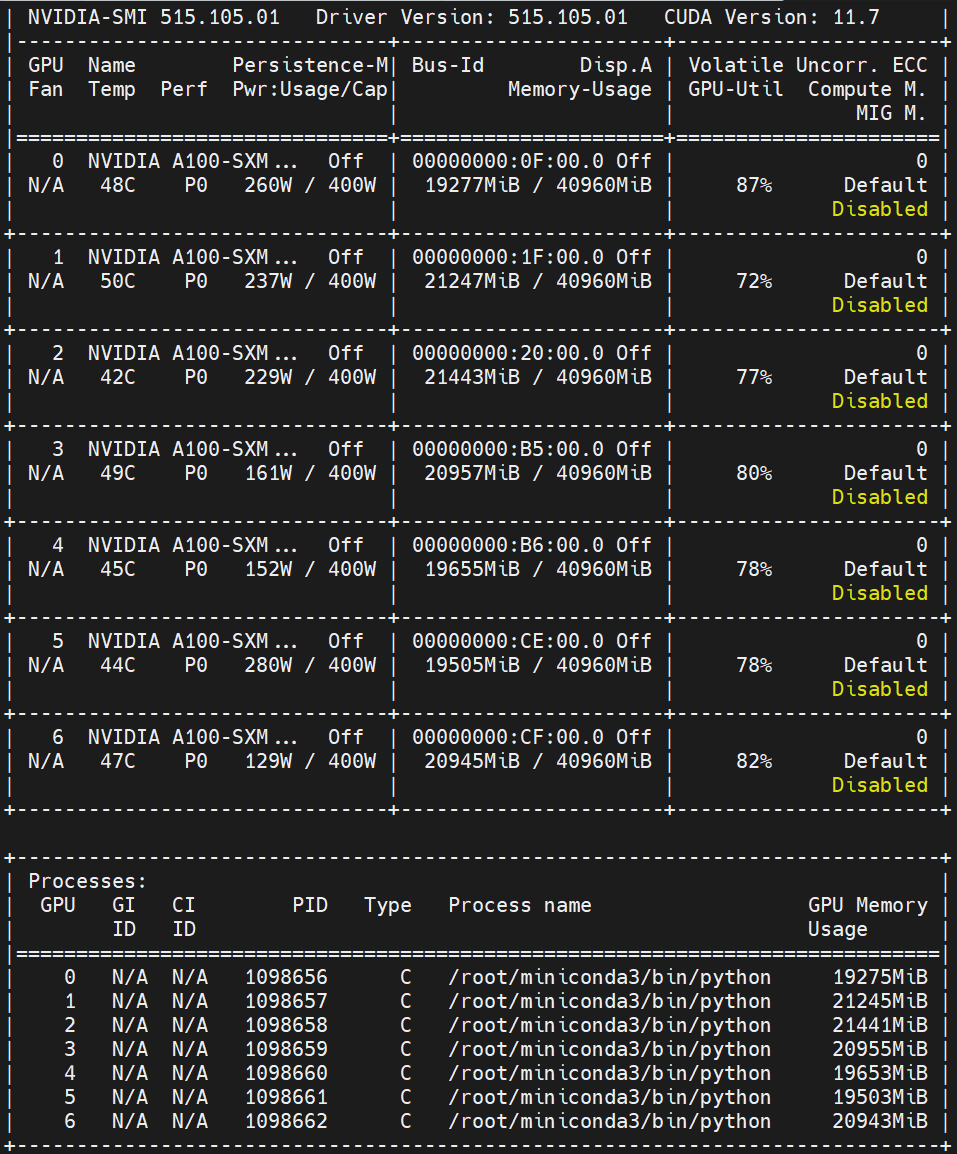
-
加载微调模型 基于github.com/ymcui/Chinese-LLaMA-Alpaca-2/blob/main/scripts/inference/inference_hf.py修改
import torch
import argparse
import json, os
DEFAULT_SYSTEM_PROMPT = """You are a helpful assistant. 你是一个乐于助人的助手。"""
TEMPLATE = (
"[INST] <<SYS>>\n"
"{system_prompt}\n"
"<</SYS>>\n\n"
"{instruction} [/INST]"
)
parser = argparse.ArgumentParser()
parser.add_argument('--base_model', default=None, type=str, required=True)
parser.add_argument('--ptuning_model', default=None, type=str, help="If None, perform inference on the base model")
parser.add_argument('--tokenizer_path', default=None, type=str)
parser.add_argument('--data_file', default=None, type=str, help="A file that contains instructions (one instruction per line)")
parser.add_argument('--with_prompt', action='store_true', help="wrap the input with the prompt automatically")
parser.add_argument('--interactive', action='store_true', help="run in the instruction mode (single-turn)")
parser.add_argument('--predictions_file', default='./predictions.json', type=str)
parser.add_argument('--gpus', default="0", type=str)
parser.add_argument('--only_cpu', action='store_true', help='only use CPU for inference')
parser.add_argument('--alpha', type=str, default="1.0", help="The scaling factor of NTK method, can be a float or 'auto'. ")
parser.add_argument('--load_in_8bit', action='store_true', help="Load the LLM in the 8bit mode")
parser.add_argument('--load_in_4bit', action='store_true', help="Load the LLM in the 4bit mode")
parser.add_argument("--use_vllm", action='store_true', help="Use vLLM as back-end LLM service.")
parser.add_argument('--system_prompt', type=str, default=DEFAULT_SYSTEM_PROMPT, help="The system prompt of the prompt template.")
parser.add_argument('--negative_prompt', type=str, default=None, help="Negative prompt in CFG sampling.")
parser.add_argument('--guidance_scale', type=float, default=1.0, help="The guidance scale for CFG sampling. CFG is enabled by setting `guidance_scale > 1`.")
args = parser.parse_args()
if args.guidance_scale > 1:
try:
from transformers.generation import UnbatchedClassifierFreeGuidanceLogitsProcessor
except ImportError:
raise ImportError("Please install the latest transformers (commit equal or later than d533465) to enable CFG sampling.")
if args.use_vllm:
if args.ptuning_model is not None:
raise ValueError("vLLM currently does not support LoRA, please merge the LoRA weights to the base model.")
if args.load_in_8bit or args.load_in_4bit:
raise ValueError("vLLM currently does not support quantization, please use fp16 (default) or unuse --use_vllm.")
if args.only_cpu:
raise ValueError("vLLM requires GPUs with compute capability not less than 7.0. If you want to run only on CPU, please unuse --use_vllm.")
if args.guidance_scale > 1:
raise ValueError("guidance_scale > 1, but vLLM does not support CFG sampling. Please unset guidance_scale. ")
if args.load_in_8bit and args.load_in_4bit:
raise ValueError("Only one quantization method can be chosen for inference. Please check your arguments")
if args.only_cpu is True:
args.gpus = ""
if args.load_in_8bit or args.load_in_4bit:
raise ValueError("Quantization is unavailable on CPU.")
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpus
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
from transformers import GenerationConfig
from transformers import BitsAndBytesConfig
from peft import PeftModel
if args.use_vllm:
from vllm import LLM, SamplingParams
import sys
parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(parent_dir)
from attn_and_long_ctx_patches import apply_attention_patch, apply_ntk_scaling_patch
if not args.only_cpu:
apply_attention_patch(use_memory_efficient_attention=True)
apply_ntk_scaling_patch(args.alpha)
if args.use_vllm:
generation_config = dict(
temperature=0.2,
top_k=40,
top_p=0.9,
max_tokens=400,
presence_penalty=1.0,
)
else:
generation_config = GenerationConfig(
temperature=0.5,
top_k=40,
top_p=0.9,
do_sample=True,
num_beams=1,
repetition_penalty=1.1,
max_new_tokens=4000
)
#sample_data = ["为什么要减少污染,保护环境?"]
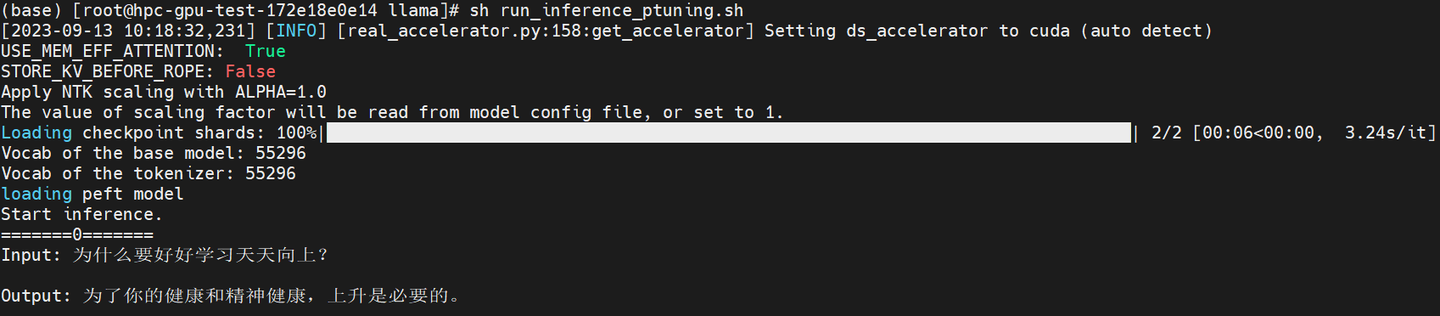
sample_data = ["为什么要好好学习天天向上?"]
#sample_data = ["why do you need to go to school?"]
def generate_prompt(instruction, system_prompt=DEFAULT_SYSTEM_PROMPT):
return TEMPLATE.format_map({'instruction': instruction,'system_prompt': system_prompt})
if __name__ == '__main__':
load_type = torch.float16
if torch.cuda.is_available():
device = torch.device(0)
else:
device = torch.device('cpu')
if args.tokenizer_path is None:
args.tokenizer_path = args.ptuning_model
if args.ptuning_model is None:
args.tokenizer_path = args.base_model
if args.use_vllm:
model = LLM(model=args.base_model,
tokenizer=args.tokenizer_path,
tokenizer_mode='slow',
tensor_parallel_size=len(args.gpus.split(',')))
tokenizer = LlamaTokenizer.from_pretrained(args.tokenizer_path, legacy=True)
else:
tokenizer = LlamaTokenizer.from_pretrained(args.tokenizer_path, legacy=True)
base_model = LlamaForCausalLM.from_pretrained(
args.base_model,
torch_dtype=load_type,
low_cpu_mem_usage=True,
device_map='auto',
quantization_config=BitsAndBytesConfig(
load_in_4bit=args.load_in_4bit,
load_in_8bit=args.load_in_8bit,
bnb_4bit_compute_dtype=load_type
)
)
model_vocab_size = base_model.get_input_embeddings().weight.size(0)
tokenizer_vocab_size = len(tokenizer)
print(f"Vocab of the base model: {model_vocab_size}")
print(f"Vocab of the tokenizer: {tokenizer_vocab_size}")
if model_vocab_size!=tokenizer_vocab_size:
print("Resize model embeddings to fit tokenizer")
base_model.resize_token_embeddings(tokenizer_vocab_size)
if args.ptuning_model is not None:
print("loading peft model")
model = PeftModel.from_pretrained(base_model, args.ptuning_model,torch_dtype=load_type,device_map='auto',).half()
else:
model = base_model
if device==torch.device('cpu'):
model.float()
model.eval()
# test data
if args.data_file is None:
examples = sample_data
else:
with open(args.data_file,'r') as f:
examples = [l.strip() for l in f.readlines()]
print("first 10 examples:")
for example in examples[:10]:
print(example)
with torch.no_grad():
if args.interactive:
print("Start inference with instruction mode.")
print('='*85)
print("+ 该模式下仅支持单轮问答,无多轮对话能力。\n"
"+ 如要进行多轮对话,请使用llama.cpp或本项目中的gradio_demo.py。")
print('-'*85)
print("+ This mode only supports single-turn QA.\n"
"+ If you want to experience multi-turn dialogue, please use llama.cpp or gradio_demo.py.")
print('='*85)
while True:
raw_input_text = input("Input:")
if len(raw_input_text.strip())==0:
break
if args.with_prompt:
input_text = generate_prompt(instruction=raw_input_text, system_prompt=args.system_prompt)
negative_text = None if args.negative_prompt is None \
else generate_prompt(instruction=raw_input_text, system_prompt=args.negative_prompt)
else:
input_text = raw_input_text
negative_text = args.negative_prompt
if args.use_vllm:
output = model.generate([input_text], SamplingParams(**generation_config), use_tqdm=False)
response = output[0].outputs[0].text
else:
inputs = tokenizer(input_text,return_tensors="pt") #add_special_tokens=False ?
if args.guidance_scale ==1:
generation_output = model.generate(
input_ids = inputs["input_ids"].to(device),
attention_mask = inputs['attention_mask'].to(device),
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
generation_config = generation_config
)
else: # enable CFG sampling
if negative_text is None:
negative_prompt_ids = None
negative_prompt_attention_mask = None
else:
negative_inputs = tokenizer(negative_text,return_tensors="pt")
negative_prompt_ids = negative_inputs["input_ids"].to(device)
negative_prompt_attention_mask = negative_inputs["attention_mask"].to(device)
generation_output = model.generate(
input_ids = inputs["input_ids"].to(device),
attention_mask = inputs['attention_mask'].to(device),
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
generation_config = generation_config,
guidance_scale = args.guidance_scale,
negative_prompt_ids = negative_prompt_ids,
negative_prompt_attention_mask = negative_prompt_attention_mask
)
s = generation_output[0]
output = tokenizer.decode(s,skip_special_tokens=True)
if args.with_prompt:
response = output.split("[/INST]")[-1].strip()
else:
response = output
print("Response: ",response)
print("\n")
else:
print("Start inference.")
results = []
if args.use_vllm:
if args.with_prompt is True:
inputs = [generate_prompt(example, system_prompt=args.system_prompt) for example in examples]
else:
inputs = examples
outputs = model.generate(inputs, SamplingParams(**generation_config))
for index, (example, output) in enumerate(zip(examples, outputs)):
response = output.outputs[0].text
print(f"======={index}=======")
print(f"Input: {example}\n")
print(f"Output: {response}\n")
results.append({"Input":example,"Output":response})
else:
for index, example in enumerate(examples):
if args.with_prompt:
input_text = generate_prompt(instruction=example, system_prompt=args.system_prompt)
negative_text = None if args.negative_prompt is None else \
generate_prompt(instruction=example, system_prompt=args.negative_prompt)
else:
input_text = example
negative_text = args.negative_prompt
inputs = tokenizer(input_text,return_tensors="pt") #add_special_tokens=False ?
if args.guidance_scale == 1:
generation_output = model.generate(
input_ids = inputs["input_ids"].to(device),
attention_mask = inputs['attention_mask'].to(device),
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
generation_config = generation_config
)
else: # enable CFG sampling
if negative_text is None:
negative_prompt_ids = None
negative_prompt_attention_mask = None
else:
negative_inputs = tokenizer(negative_text,return_tensors="pt")
negative_prompt_ids = negative_inputs["input_ids"].to(device)
negative_prompt_attention_mask = negative_inputs["attention_mask"].to(device)
generation_output = model.generate(
input_ids = inputs["input_ids"].to(device),
attention_mask = inputs['attention_mask'].to(device),
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
generation_config = generation_config,
guidance_scale = args.guidance_scale,
negative_prompt_ids = negative_prompt_ids,
negative_prompt_attention_mask = negative_prompt_attention_mask
)
s = generation_output[0]
output = tokenizer.decode(s,skip_special_tokens=True)
if args.with_prompt:
response = output.split("[/INST]")[1].strip()
else:
response = output
print(f"======={index}=======")
print(f"Input: {example}\n")
print(f"Output: {response}\n")
results.append({"Input":input_text,"Output":response})
dirname = os.path.dirname(args.predictions_file)
os.makedirs(dirname,exist_ok=True)
with open(args.predictions_file,'w') as f:
json.dump(results,f,ensure_ascii=False,indent=2)
if args.use_vllm:
with open(dirname+'/generation_config.json','w') as f:
json.dump(generation_config,f,ensure_ascii=False,indent=2)
else:
generation_config.save_pretrained('./')
# run
python scripts/inference/inference_hf_ptuning.py \ # 基础模型
--base_model correspond_output_dir \ # 如果没有设置,将在基础模型上执行推理
--ptuning_model ptuning_output/sft_ptuning_model/ \ # 分词器路径
--tokenizer_path correspond_output_dir \
--with_prompt # 自动用提示符包装输入