


1 随机森林
人工智能的研究历史有着一条从以“推理”为重点,到以“知识”为重点,再到以“学习”为重点的自然、清晰的脉络。机器学习作为人工智能的一部分,主要是设计和分析一些让计算机可以自动“学习”的算法,旨在构建能够根据所使用的数据进行学习或改进性能的系统。
随机森林(Random Forest,简称RF)属于集成算法的一种,其由很多决策树组成完全相应的决策策略。决策树(Decision tree)采用树形结构,使用层层推理来实现最终的分类。决策树作为最简单的机器学习算法,它易于实现,可解释性强,完全符合人类的直观思维,是一种基于if-else规则的有监督学习算法。

图一 决策树
随机森林作为基于决策树的集成算法,根据各决策树的推理结构进行相应的决策策略,得到最终的推理结果。由于其可解释性强、高度灵活、准确率高、能够有效地运行在大数据集上等多个特点,随机森林拥有广泛的应用前景,比如在金融领域用于投资决策,市场营销中用来模拟建模、预测客户行为并提供个性化服务,医疗行业中用来预测疾病的风险和病患者的易感性等等。近期在网络安全领域也有不错的使用,比如网络安全防火墙。下面主要讲其在网络安全流域中流量识别的应用。
2 网络安全应用
2.1 背景
流量识别技术在网络监控与管理、流量计费、用户行为分析等方面有重要的应用。例如,入侵防御系统及防火墙使用该技术识别恶意流量,及时阻断恶意连接;企业借助流量识别技术控制应用访问;相关机构通过识别用户移动设备流量推测用户信息与行为等。毋庸置疑,实现准确高效的流量识别具有极其重要的意义。
基于机器学习的流量识别技术成为近些年流量识别领域最受关注的方法。研究工作开始利用流量在应用级别的通讯模式或统计特征识别流量,基于机器学习的流量识别方法取得了极大的进展,并表现出不依赖负载、准确率高、计算迅速、可扩展性强等特点。本文只关注利用统计特征进行流量识别这类方法。
2.2 应用流程
基于不同的协议或应用流量具有不同的统计特征,本方法首先收集大量的流量实例,提取流量中与负载内容无关的统计量,然后结合机器学习算法训练识别模型,生成用于新样本识别的分类器,该分类器是随机森林模型,由多个统计特征参量及其阈值构建。该方法流程如下图所示。

图二 基于随机森林的流量识别方法流程
该方法使用三个随机森林实现分类器功能。一条待识别的流量样本进入分类器后,经过粗筛、粗识、细识,最终完成整个决策过程。下图是分类器的流程。
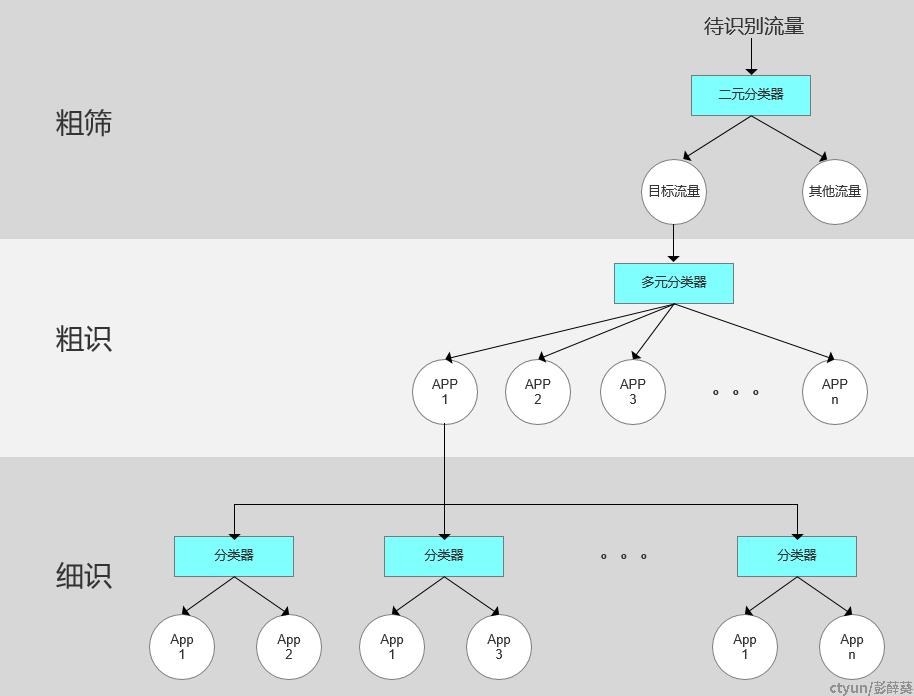
图三 分类器
2.3 问题及挑战
1)实时性。由于实际应用场景中常需要对流量进行实时识别,而网络带宽增长日新月异,如何设计满足高速网络实时分类的识别模型是极具挑战性的任务;
2)动态更新。由于新协议新应用的出现,或原协议应用改进等原因,流量特征随时可能发生变化,使用过时的流量数据学习的分类器无法有效处理这些新流量。因此,有必要使用新数据持续更新分类器。除此之外,网络环境的多样性也导致分类器在不同环境中移植性较差。
由于决策树的层级计算结果依赖关系,决策树中每一层算完之后需要把该层所有的输出信息作为下一层的输入,此时该层将会停止运作,直至当前的数据流被决策树完全计算完。对于CPU来说,对于层级较多或者模型较大的随机森林,由于计算延时和线程资源的约束,CPU较难满足高速网络实时分类和分类器实时更新的要求。
FPGA不同于CPU,FPGA上的硬件模块可以同时进行运算,并且计算延时是ns级,因此如果决策树在FPGA上的实现采用流水结构可以大大提高计算效率和资源的使用效率。同时,FPGA片上有存储资源可以对模型进行存储,可以动态的更新维护分类器。所以使用FPGA进行分类器的实现有一定优势。
3 FPGA实现方案
3.1 架构
FPGA针对该方案训练的随机森林模型(图二中的分类器)进行加速实现。FPGA实现架构如下图所示。
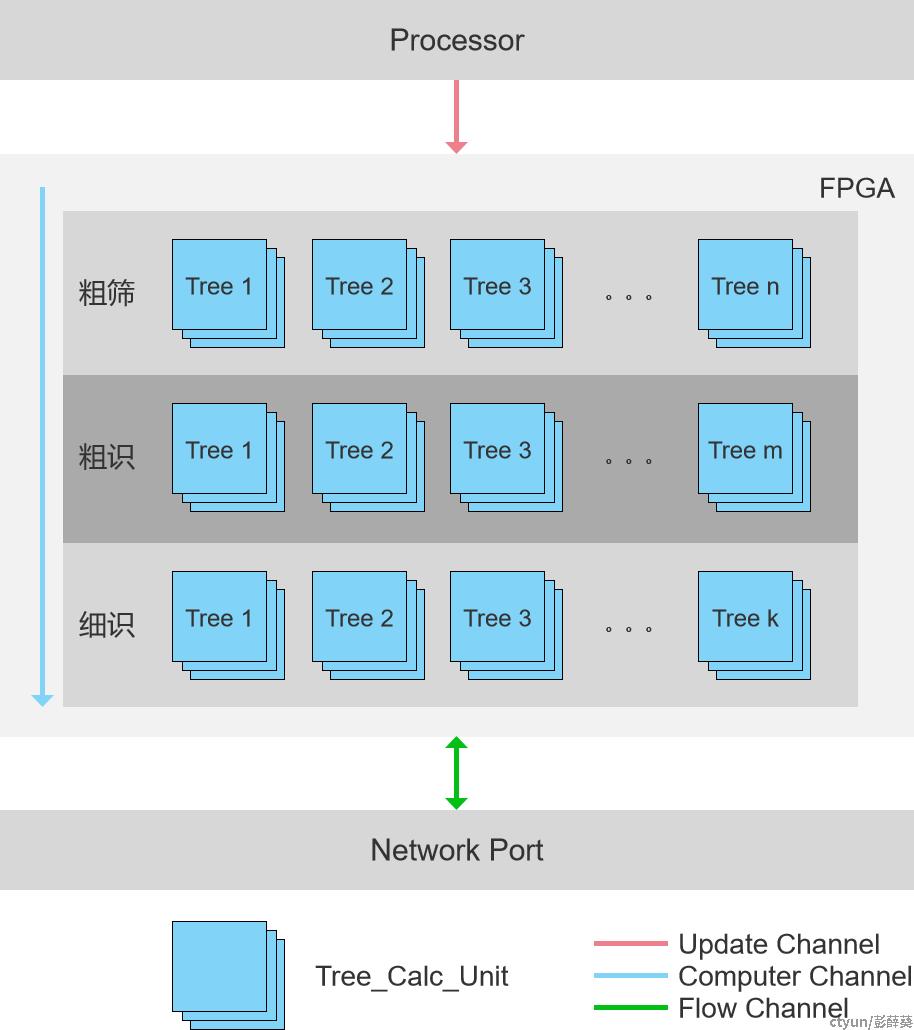
图四 FPGA实现架构
FPGA通过三个数据通道分别实现模型的更新,统计特征参量的输入、提取、分配,以及模型的计算。
Processor通过Update Channel可实时更新随机森林模型,将模型参数下载并分配到FPGA的计算单元;
Flow Channel接收并提取网络流量中相应的特征参量进入FPGA的计算单元用于计算;
Computer Channel完成随机森林的流水计算,计算的识别结果继续通过网络端口输出。
3.2 计算
在FPGA中,每一个随机森林由若干决策树计算单元(Tree_Calc_Unit)组成,每一个计算单元以层级流水的方式完成一棵决策树的计算。当一个流量样本进入FPGA,所有的计算单元被同时激活进行并行计算,同时对每个计算单元的结果进行对齐,最终实现该方案中的三个随机森林组成的分类器。

图五 决策树计算单元
3.3 更新
该方法支持两种更新模式,半灵活方式每棵决策树的层数有要求上限(20层),计算延时更低;全灵活方式在不超过计算单元规模下,决策树的层数和棵树可完全灵活配置,计算延时相对要高。用户可根据需要自行选择。
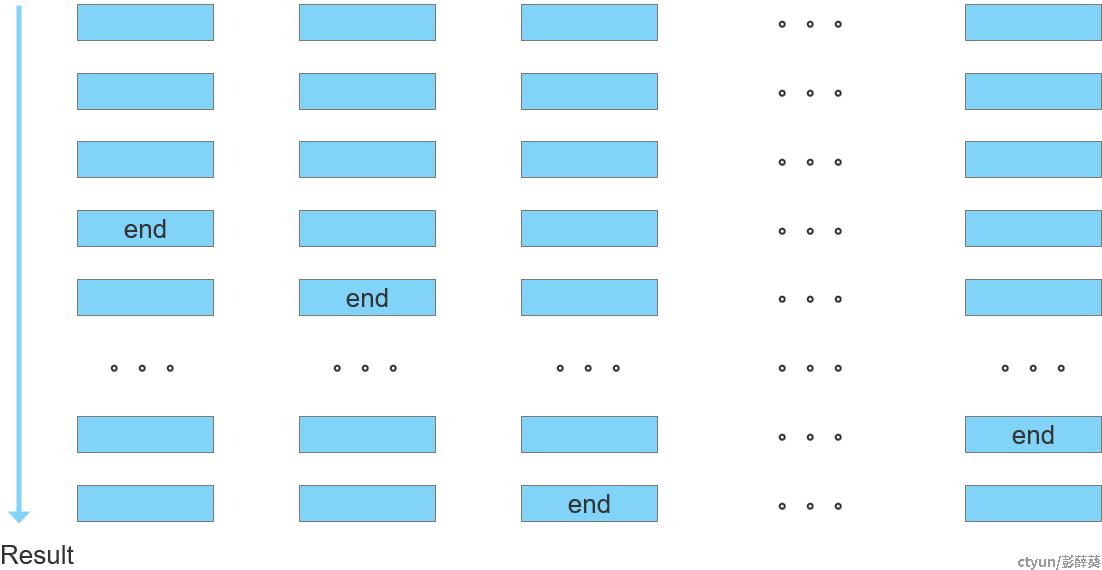
图六 半灵活配置方式

图七 全灵活配置方式
4 测试结果
该方法中分类器模型由多统计特征参量训练完成,采用intel PAC A10实现一个95棵决策树组成的随机森林模型分类器,完成流量的粗筛、粗识、细识。
最终在每条测试流特征参量集为144byte的情况下,单张FPGA板卡可以达到约150M/s的QPS,而同等条件下,CPU在scikit-learn库中对该模型的QPS为0.29M/s。
在识别延时方面,FPGA加速效果也很明显,单条流量识别结果延时在1us以内。
5 总结及展望
随机森林因其可解释性强、准确率高等优势,拥有广泛的应用前景,比如网络安全、结果预测、推荐引擎、决策分析等。由于FPGA在并行计算方面的优势,相信在基于随机森林的多个应用场景,FPGA均可以发挥其高速和灵活性的优点。
