


Pytorch分布式协商机制依赖rendezvous模块
rendezvous:会合
Pytorch如何实现分布式训练,如何弹性:
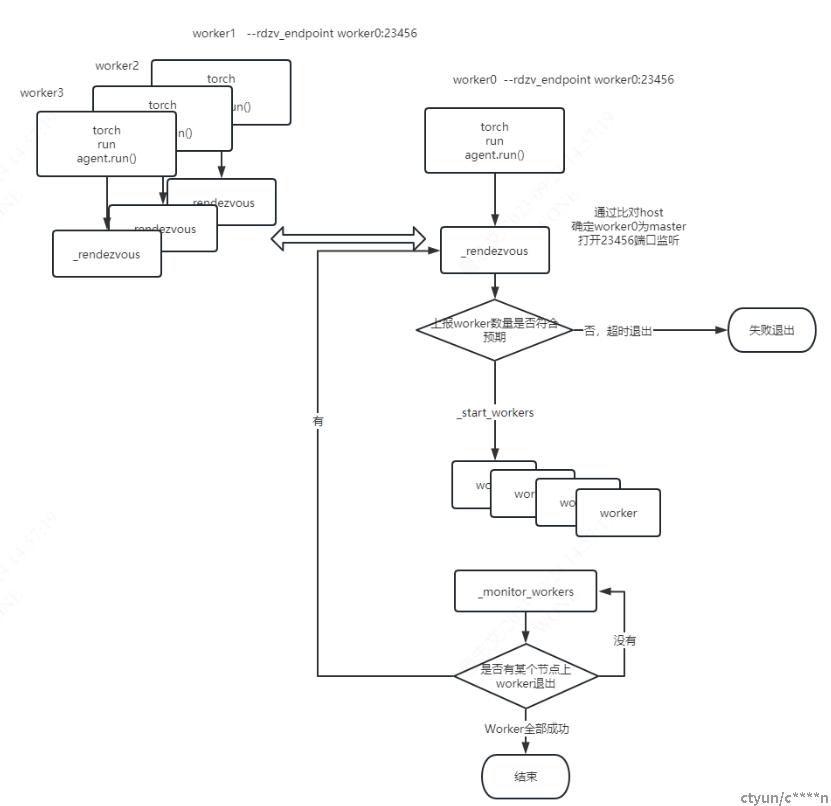
Pytorch启动命令如下:nnodes nproc_per_node rdzv_id rdzv_backend rdzv_endpoint都是和分布式训练有关的参数
python -m torch.distributed.run --nnodes=$NUM_NODES --nproc_per_node=$NUM_TRAINERS --rdzv_id=$JOB_ID --rdzv_backend=c10d --rdzv_endpoint=$HOST_NODE_ADDR YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...) |

c10d和etcd2的区别是选择不同的共享存储,用于存放各进程的存储信息;
RendezvousBackend 最重要的两个方法:
get_state 从共享存储中都数据
set_state 往共享存储中写数据
c10d是基于tcp连接,共享数据存储在server内存中的一种backend:
先看c10d的创建:
_create_tcp_store #Python的方法 store = TCPStore(#这里调用C库,is_master参数决定是否启动TCPStoreMasterDaemon作为Server,或只创建client host, port, is_master=is_server, timeout=timedelta(seconds=read_timeout) ) |
pytorch\torch\csrc\distributed\c10d\TCPStore.cpp
TCPStore::TCPStore(std::string host, const TCPStoreOptions& opts) : Store{opts.timeout}, addr_{std::move(host)}, numWorkers_{opts.numWorkers} { Socket::initialize(); if (opts.isServer) { server_ = detail::TCPServer::start(opts); #isServer true 创建TCPServer监听指定端口 addr_.port = server_->port(); } else { addr_.port = opts.port; } client_ = detail::TCPClient::connect(addr_, opts); #都会创建TCPClient 进行连接 if (opts.waitWorkers) { waitForWorkers(); } callbackClient_ = detail::TCPCallbackClient::connect(addr_, opts);} |
TCPServer的主要函数是监听端口,处理请求:
std::shared_ptr<TCPServer> TCPServer::start(const TCPStoreOptions& opts) { auto startCore = [&opts]() { Socket socket = Socket::listen(opts.port); #监听端口 std::uint16_t port = socket.port(); auto daemon = std::make_unique<TCPStoreMasterDaemon>(std::move(socket)); #TCPStoreMasterDaemon处理事件 return std::make_shared<TCPServer>(port, std::move(daemon)); }; |
以下是相应的事件处理接口,代码都比较简单,可以自行阅读:
void TCPStoreMasterDaemon::query(int socket) { QueryType qt; tcputil::recvBytes<QueryType>(socket, &qt, 1); if (qt == QueryType::SET) { setHandler(socket); } else if (qt == QueryType::COMPARE_SET) { compareSetHandler(socket); } else if (qt == QueryType::ADD) { addHandler(socket); } else if (qt == QueryType::GET) { getHandler(socket); } else if (qt == QueryType::CHECK) { checkHandler(socket); } else if (qt == QueryType::WAIT) { waitHandler(socket); } else if (qt == QueryType::GETNUMKEYS) { getNumKeysHandler(socket); } else if (qt == QueryType::DELETE_KEY) { deleteHandler(socket); } else if (qt == QueryType::WATCH_KEY) { watchHandler(socket); } else { TORCH_CHECK(false, "Unexpected query type"); }} |
TCPClient主要是set和get函数,可以看出都是向Server发出请求
void TCPStore::set(const std::string& key, const std::vector<uint8_t>& data) { const std::lock_guard<std::mutex> lock(activeOpLock_); client_->sendCommandForKey(detail::QueryType::SET, keyPrefix_ + key); client_->sendBytes(data);} |
std::vector<uint8_t> TCPStore::get(const std::string& key) { const std::lock_guard<std::mutex> lock(activeOpLock_); return doGet(keyPrefix_ + key);} |
刚才说的c10d和ectd都只是提供共享存储。
真正完成协商和状态机处理的事dynamic_rendezvous
pytorch\torch\distributed\elastic\rendezvous\
next_rendezvous exit_op = _RendezvousExitOp() join_op = _RendezvousJoinOp() self._op_executor.run(exit_op, deadline) self._op_executor.run(join_op, deadline) |
run函数:
只要action != _Action.FINISH 就一直循环
has_set = self._state_holder.sync() #同步共享存储,共享存储中存了各节点相关数据,经过反序列化后,participants中存了各节点信息;
(线上处理过sync的一个bug,sync会同步到participants的信息,但是在sync结束前,会检查participants内各node heartbeat时间,如果超时的node会被删除;这个删除的动作不严谨,会导致后面基于participants的操作访问越界;如果node间时间不同步,这个bug可以高频复现)
action = state_handler(ctx, deadline) #调用回调函数 比如_RendezvousExitOp, _RendezvousJoinOp
#维护了一组状态机,根据返回值,进行事件处理:
if action == _Action.KEEP_ALIVE: self._keep_alive()elif action == _Action.ADD_TO_PARTICIPANTS: self._add_to_participants()elif action == _Action.ADD_TO_WAIT_LIST: self._add_to_wait_list()elif action == _Action.REMOVE_FROM_PARTICIPANTS: self._remove_from_participants()elif action == _Action.REMOVE_FROM_WAIT_LIST: self._remove_from_wait_list()elif action == _Action.MARK_RENDEZVOUS_COMPLETE: self._mark_rendezvous_complete()elif action == _Action.MARK_RENDEZVOUS_CLOSED: self._mark_rendezvous_closed() |
_RendezvousExitOp 先清理干净状态
def __call__(self, ctx: _RendezvousContext, deadline: float) -> _Action: if ctx.node in ctx.state.participants: if time.monotonic() > deadline: return _Action.ERROR_TIMEOUT #超时抛出错误退出 return _Action.REMOVE_FROM_PARTICIPANTS #如果已协商加入的,操作退出 return _Action.FINISH #如果没协商加入,处理完成,run循环退出 |
_RendezvousJoinOp:
if state.complete and is_participant: #协商完成,并且本节点是其中一员,该流程完成,run结束 return _Action.FINISHif state.complete: # 这个state.complete是多个节点共享的,如果这里出现state.complete,但是is_participant为false,代表其他节点已协商完成,但是本节点并没有被接纳,将自己放入wait_list队列中 if len(state.participants) < ctx.settings.max_nodes: if ctx.node not in state.wait_list: return _Action.ADD_TO_WAIT_LISTelif is_participant: #如果节点已加入,并且协商完成的节点数大于min_nodes,等待时间结束就执行COMPLETE if len(state.participants) >= ctx.settings.min_nodes: if cast(datetime, state.deadline) < datetime.utcnow(): return _Action.MARK_RENDEZVOUS_COMPLETEelse: return _Action.ADD_TO_PARTICIPANTS #初始走这里,执行加入动作if _should_keep_alive(ctx): return _Action.KEEP_ALIVE |
def _add_to_participants(self) -> None: msg = ( f"The node '{self._node}' added itself to the participants of round " f"{self._state.round} of the rendezvous '{self._settings.run_id}'. Pending sync." ) self._record(message=msg) log.debug(msg) state = self._state try: state.wait_list.remove(self._node) #从wait_list表中删除 except KeyError: pass # The ranks of the participants will be set once the rendezvous is # complete. state.participants[self._node] = 0 self._keep_alive() #如果participants数量已等于min_nodes,刷新等待时间,再等待这段时间中是否有新节点加入 if len(state.participants) == self._settings.min_nodes: state.deadline = datetime.utcnow() + self._settings.timeout.last_call #如果participants等于max_nodes,立刻标志complete if len(state.participants) == self._settings.max_nodes: self._mark_rendezvous_complete() |
