


研究背景
1.大内存需求同服务器内存资源不足之间的矛盾:Tb级内存处理、大规模近似近邻搜素等
2.算效提升需求同数据中心内存资源闲置之间的矛盾:内存成本占比高、内存资源闲置严重等
因此期望使用内存分解,将主机与一个或多个内存节点连接起来,这样就不会因为有限的本地内存空间而限制任务的执行。
内存分解现有方法主要通过远程直接内存访问Remote Direct Memory Access (RDMA) 将数据从远程内存移动到主机内存。它需要管理主机或内存节点中的本地缓存数据。另外,数据移动及其伴随的操作引入了冗余内存拷贝和软件干预,这使得分解内存的延迟比本地DRAM访问的延迟高多个数量级。
而随着CXL技术的发展,CXL可以通过cxl.mem协议直连CXL device省去RDMA的数据拷贝过程和网络传输过程。因此DirectCXL第一个使用CXL技术实现CXL直连内存设备。

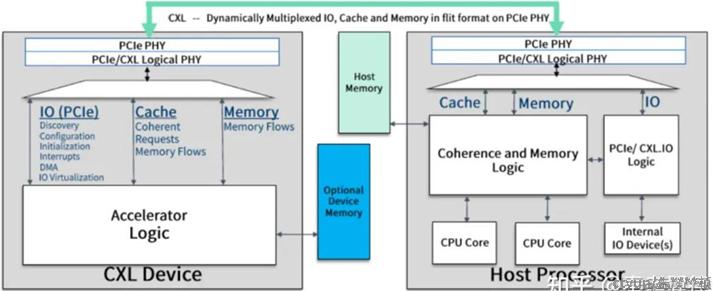
研究方法
如图中所示,宿主机访问分离内存可以通过CXL.mem协议直连CXL device实现1对1的连接,还可以通过CXL switch连接多个CXL device实现多对多的连接。

CXL device

在device内部,存在多个DRAM DIMM,并通过CXL controller暴露给DDR接口。
宿主机kernel在启动时会先枚举连接的CXL device数目,以及内部的CXL Controller数目;而CXL device会将内部的内存大小和寄存器返回给kernel,从而kernel可以在宿主机的预留内存空间内提前规划一块空间作为CXL device上内存的映射;因此kernel会将base 地址传输回CXL device。
而宿主机有内存请求到CXL device时,则先到预留内存空间,再通过CXL.mem和base地址解析CXL device上对应的内存地址。
CXL switch
host连接CXL device、CXL switch和级联switch,形成内存池;通过网络管理器FM配置host与CXL之间的连接;使用CPU LLC作为CXL RP并且保证
宿主机不会共享相同的HDM。
实验对比


针对64B的数据,Local需要60个周期,DirectCXL仅需328个周期,RDMA需要2705周期,比RDMA快8.3倍。这说明DirectCXL优势在于,
DirectCXL直连,RDMA需要在InfiniBand和PCIe之间转换;DirectCXL使用LLC执行load/store,RDMA需要DMA读写内存
