


分享一次mlnx网卡因同步link状态,导致openvswitch 转发延迟问题的定位过程
问题现象
海光cpu,Mellanox网卡环境,宿主机内虚机ping包(每秒1000个),偶现100ms以上延迟抖动。大约数分钟出现一次或连续数个。
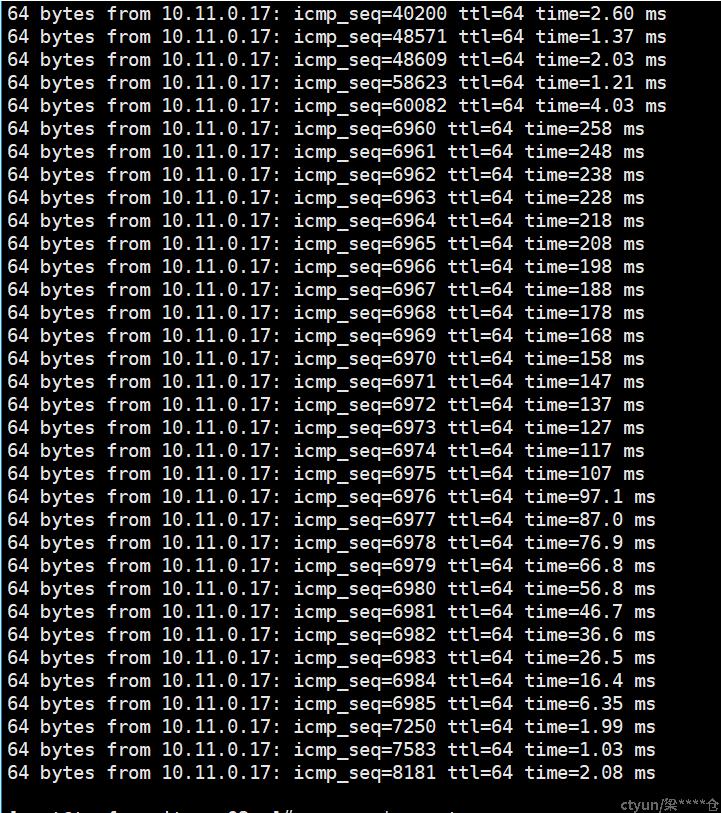
ovs为dpdk模式,此环境正常转发延迟应该在1ms以下。
排查过程
ovs通过pmd-perf-log记录,看到ovs pmd线程上出现一次收包处理周期耗时长达100ms以上的记录。且出现时机与ping包发生大延迟重合。且ping包的延迟和ovs记录的周期时长也能匹配。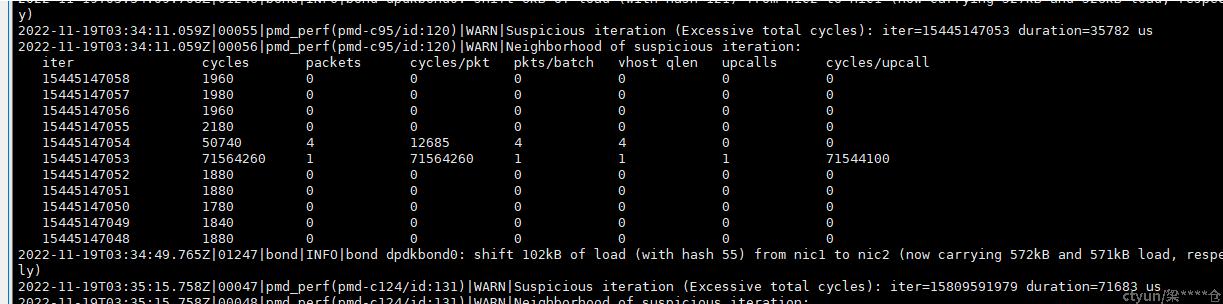
pmd一轮处理周期正常情况下只有几千个时钟周期。占用几十毫秒明显不合理。此轮周期时间消耗过长,会导致长时间不收取网卡或虚机队列中的报文,造成下一轮待处理报文产生延迟。符合问题现象。
根据抓取日志,我们定位到造成大延迟的流程均在ovs查找dp流表失败,通过upcall上送慢路径查询ofp流表之后。构造新dp流表完成前的代码区间。
范围在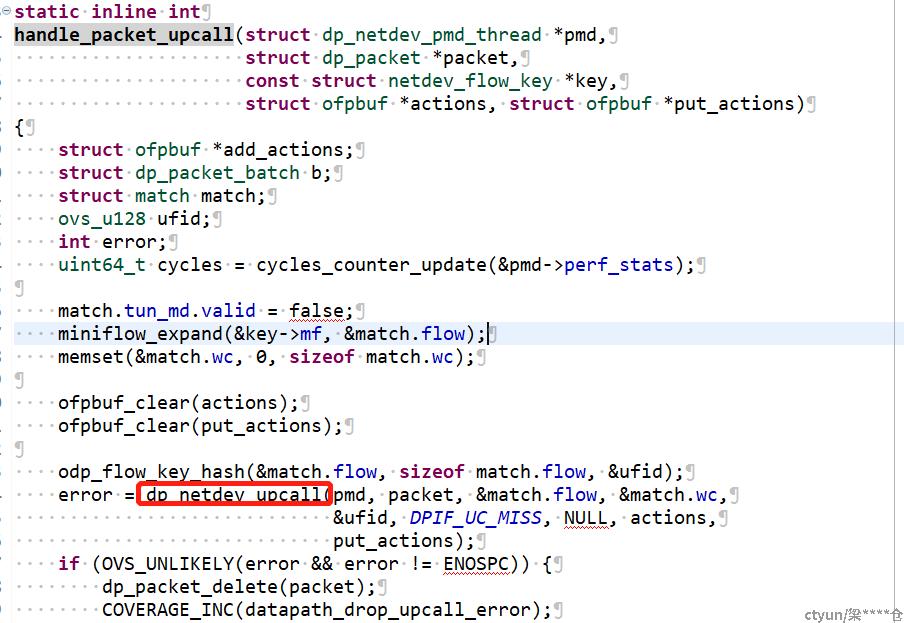
到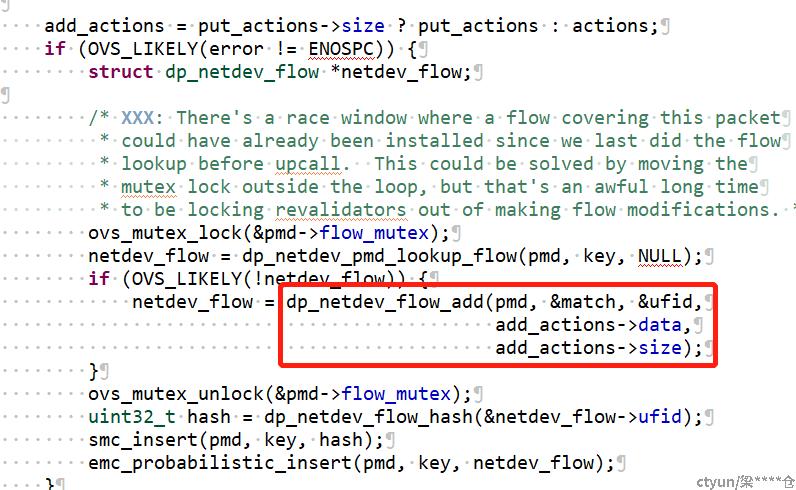
之间,包括这两个函数。
然后我们通过systemtap跟踪此区间内函数执行时间并抓取异常长pmd周期发生时的函数执行时间,逐步缩小长耗时流程的范围。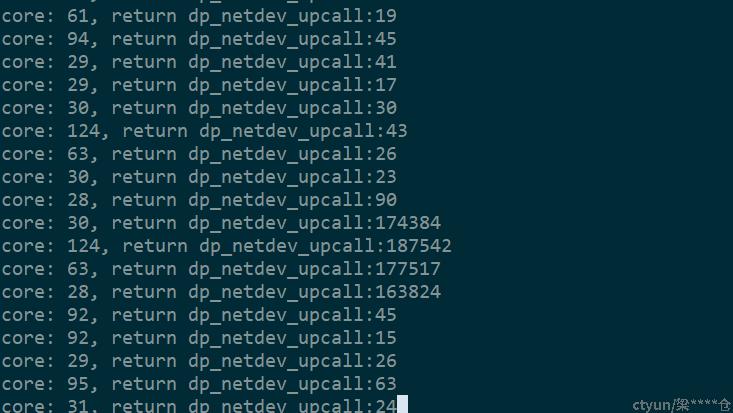
通过反复缩小范围,最终定位到长耗时函数为bond_check_arp_copy_ability,此函数本身处理任务不耗时,但是为了获取锁等待了上百毫秒。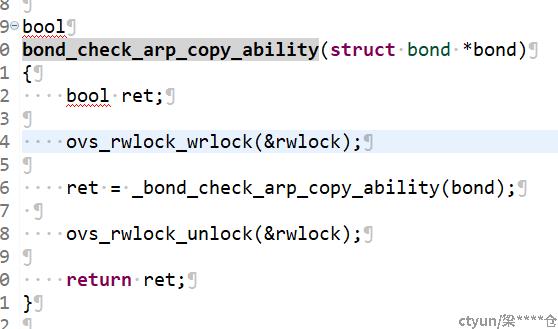
检查此锁的持有者,并通过systemtap记录起锁内和锁外的耗时,发现为bond_run占用该锁且锁内处理耗时异常长。进一步分析,发现为bond_run为刷新bond口状态而获取网卡link状态的netdev_get_carrier耗时长。继续向下调用为dpdk提供的mlx5网卡驱动。
rte_eth_link_get_nowait -> mlx5_link_update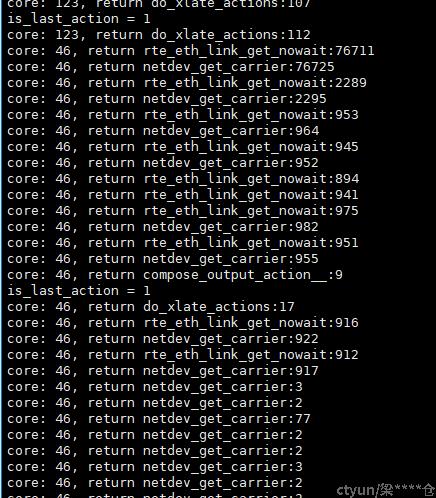
通过分析代码,mlx5驱动获取网卡link状态的方法为向其内核态驱动发送ioctl请求,且使用了忙等方式反复尝试,并设置了10s的超时时间。由于此种通信方式本身耗时较长且ovs可能频繁调用,导致了bond_run在持有锁的区间产生较大耗时,从而造成pmd线程等锁形成长pmd处理周期。其他厂商的用户态网卡驱动是在用户态直接读寄存器获取link状态,所以没有这么大的时间开销)
回推复盘,发现每次触发upcall导致长pmd吹周期的报文都是dns请求,这种报文发送不频繁,所以通常dp流表都被老化了,所以会触发upcall。而如果其在upcall处理过程中恰好遇到mlx5_link_update出现长耗时,就会由于等锁的原因阻塞当前pmd处理。而恰好此pmd线程下一轮会处理ping包时,就引起了ping包的大延迟。
解决方法
分析代码,发现网卡可以通过配置为lsc模式(中断模式更新网卡状态,即其网卡内核驱动主动推送网卡状态变更,并存放在用户态内存中,用户态驱动获取网卡状态时直接读取该内存),极大的减少时间开销。
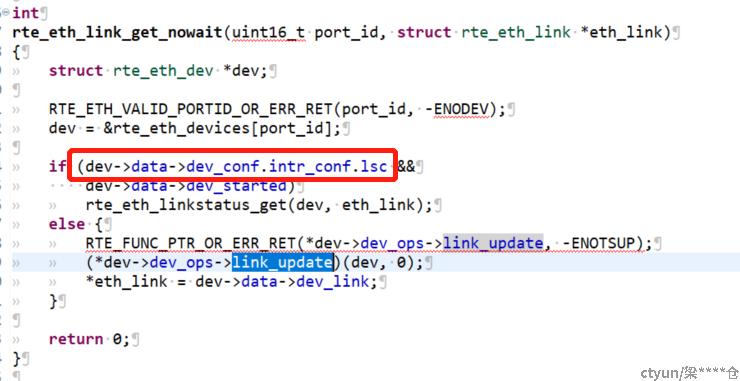
ovs修改mlnx网卡为lsc模式
ovs-vsctl set interface $dpdkif options:dpdk-lsc-interrupt=true
修改后查看,问题宿主机内部ping包没有再频繁出现100ms以上的不定期时延抖动。
