


Intel Data Streaming Accelerator (DSA) 是在第四代可扩展至强处理上新加入的片上加速器,这一款加速器是由前一代的 CBDMA (Crystal Beach DMA)加强改进而来。在传统的DMA性能大幅提升的基础上, 加入了新的操作例如计算crc,比较两片内存区域,dualcast到两片内存区域的支持,并且同时支持SIOV类型的虚拟化和persistent内存的访问以及共享虚拟内存的功能。
这篇文章会简要介绍 DSA设备的功能,使用方法和一些应用使用DSA加速之后的性能表现。
DSA设备简介:
Data streaming accelerator的属于至强cpu的非核心部分,跟其他类型的加速设备封装在一起。它对外展现出来的是独立的pci 设备。根据CPU SKU的不同,每个CPU上的DSA设备数量会有所不同,目前最多为四个。
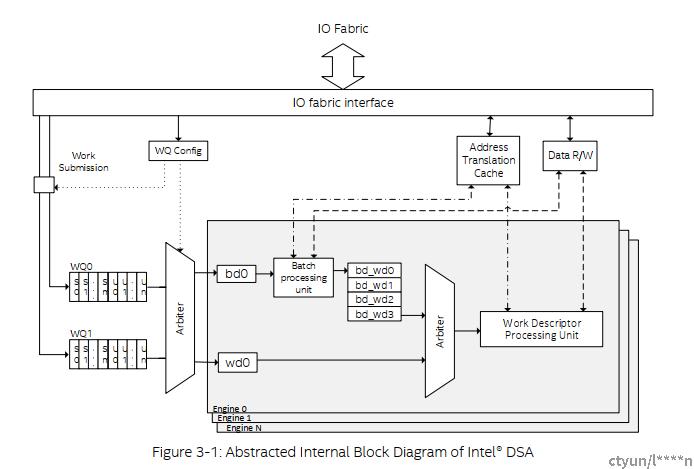
DSA设备的内部架构:
DSA设备内部包含了工作队列WQ, WQ的仲裁器,批量处理单元,工作描述符处理单元,工作描述符的仲裁器,地址转换缓存,DMA引擎等组成。目前一个DSA设备中会有四个DMA引擎,八个工作对列和八个工作组。
当DSA在发现工作描述符中是批量处理单元时会将此次任务放入批量处理单元的工作队列中,而后DSA设备会访问主机内存将这次的批量任务获取到内部缓存中,再按顺序加入WD仲裁器中,DSA将在仲裁器中根据QOS的配置来处理优先任务。
CPU交给DSA的任务是首先放到工作队列中的,工作队列有两种类型,一种是共享的工作队列,一种是独占式的工作队列。
在实现上一般是SIOV使用共享工作队列,传统任务使用独占式工作队列。这里特别要指出独占式工作队列的访问窗口是posted write类型的,这就代表了cpu的写操作不会挂起等待设备告知任务已经被接受,而是写操作发出之后就直接返回了。之后需要驱动去主动测算片上缓存的数量,以防任务溢出。
共享工作队列需要用新的指令ENQCMD去写,这个指令发出后,CPU会等待执行的结果返回。驱动需要判断写操作的结果,如果任务下发失败,驱动需要重新下发任务。
Group是工作对列的集合,group中的工作对列会共享QoS设置和DMA引擎。
DSA的使用:
跟大多数pci设备一样,DSA设备也需要通过BAR0上的配置寄存器进行初始化配置。好消息是kernel中的idxd驱动已经对设备进行了初始化,并且抽象出了设备访问接口。
我们可以通过对sysfs路径/sys/bus/dsa/devices/wq{$did}/下的属性来配置DSA设备,例如总共有几个工作队列,每个工作队列最大传输的长度和片上存储的大小。分配好队列之后,可以通过map队列设备文件 /dev/wq{$device id}.${queue id} 来获得这个队列的访问窗口。
DSA开发团队还提供了一个linux下的用户配置工具accel-config, 可以更便捷的配置DSA设备。
下面就一个使能DSA设备0上的一个共享对列的例子。这里可以看到对列使用了32个on-chip 描述符存储的空间,临界值设成了4,这样保证了有额外的空间给更高优先级的任务。这里没有使能block-on-fault的功能,表示当DMA访问出错后DSA设备不会等待pagefault的处理。
accel-config config-device dsa0
accel-config config-engine dsa0/engine0.2 --group-id=0
accel-config config-wq dsa0/wq0.0 --group-id=0 --wq-size=32 --priority=1 --block-on-fault=0 --threshold=4 --type=user --name=swq --mode=shared --max-batch-size=32 --max-transfersize=2097152
accel-config enable-device dsa0
accel-config enable-wq dsa0/wqDSA的描述符:
当DSA设备配置完成之后,就需要通过队列的访问窗口向对列添加任务。任务的下发是通过向访问窗口写描述符来完成的。总的来说,所有的描述符都是一个cacheline的长度,不同的操作下描述符的结构略有不同。需要根据具体的使用来配置描述符,根据描述符类型的不同,完成的记录也是不同的,需要根据提交的类型来进行解析。

这里简单看一下Batch 操作描述符是什么样的:
这里 op 的类型是Batch, 源地址的含义变成了描述符列表的地址, transfer size的含义变成了描述符的数量。Batch描述符的完成记录里面包含了完成的状态,结果以及完成的描述符的数量。


保序和分隔:
DSA设备在操作的过程是不保证顺序的,但是可以通过一些方法来保证顺序。
其一是对使用的硬件资源进行限制,只用一个group一个DMA引擎,发送到通过一对列窗口,使用相同的QoS配置。由于条件的苛刻,并且只有描述符中的写操作保续,所以一般不用这种方法。
保序一般是通过加入分隔描述符来实现的,当通过completion record发现这个分隔描述符代表的操作完成之后,之前所有的描述符中的任务可以确认是完成了。
使用的例子:
目前开源项目DPDK,SDPK,VPP中都已经加入了DSA的支持,基于此也有一些应用基于DSA做了加速的工作。下面是几个使用DSA来进行加速的例子。
Calico-VPP memif 接口使用DSA加速之后在1024B数据包长度下有78%的提升。

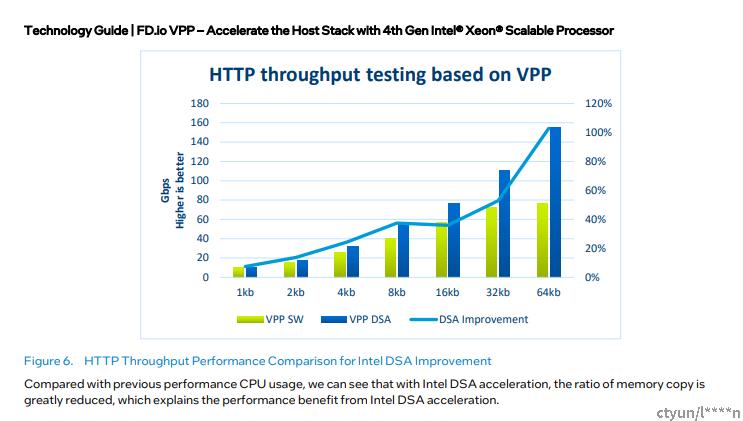
VPP hoststack使用DSA加速后在64KB大包的情况下有100%的性能提升。
Vhost中使用DSA的结果显示在1024B这样的数据包长度下可以提升38%的性能。

后续:
Inter-domain operation, SIOV, QoS, shared virtual memory, performance monitor
