随着业务的发展,大数据在各行各业发挥越来越重要的价值,但大数据价值密度相对低,降低研发(平台研发国产化、应用开发迁移)、运维管理(部署、升级、监控、安全)和运行时资源(存储、计算、网络)成本是大数据平台一直的挑战。
另一方面,平台的需求在不断膨胀,现有的架构和关键技术需要不断突破。

具体的技术路线、发展趋势从存储、调度、计算和平台的Serverless化展开。
存储
分布式存储系统的挑战

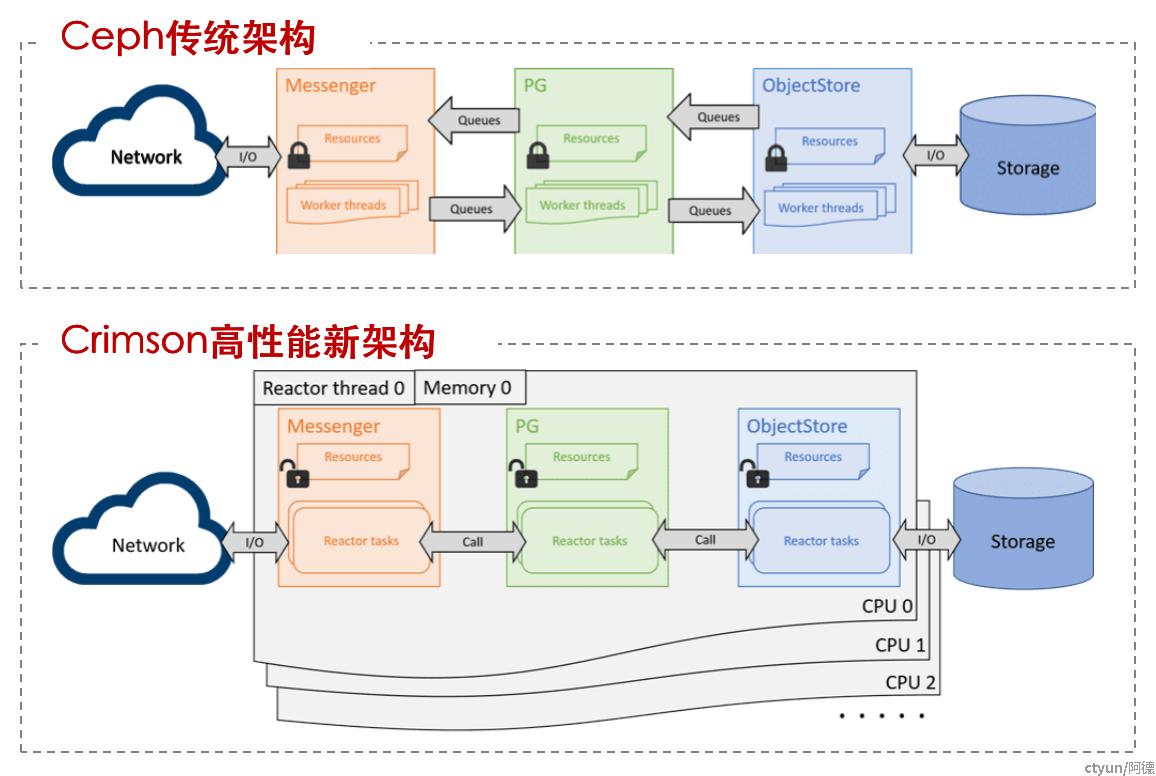
高性能的单机存储引擎
高性能的挑战:
- 软件跟不上硬件的发展速度
- 内存和存储硬件IO性能极速增加 CPU 频率和单线程性能增长不明显,而逻辑核心的数量迅速增长
- Linux内核IO栈的效率
解决方案:
- 异步线程架构:seastar框架等
- Shared-Nothing:无锁,随核数线性扩展
- Run-to-Completion:减少上下文切换
- Modern IO APIs:SPDK/DPDK(用户态 复杂性高)、libaio(异步 灵活)、io_uring(易用 高性能)
- 用户态文件系统(数据IO用户态),不止于Zero Copy
- 硬件卸载:DPU,加解密,(解)压缩,校验,转发
统一多模底座

调度:混部work load
背景:
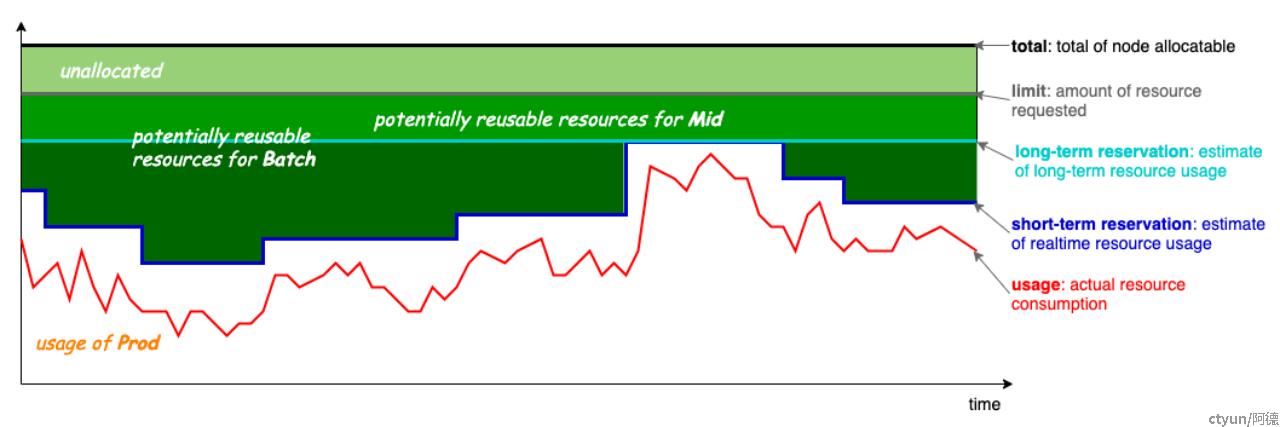
- 成本高:随需求(在线微服务、离线计算、AI算力)的增长, 集群规模快速增长
- 资源利用率低:因灾备服务、访问的波峰、难预估资源申请等问题,在线服务集群利用率<15%
解决方案:
- 资源运营(运维负担重,无法根治)、动态超卖(超售策略不一定准确且可能导致挤兑风险)、动态扩缩(利用波峰波谷,服务动态扩缩,无法充分实现全天利用率提升)
- 混部:将不同特征类型工作负载协同调度,充分利用负载之间的消峰填谷效应,让工作负载以更稳定、更高效、更低成本的方式去使用资源
混部方案V1
统一到YARN
- YARN的挣扎:调度能力的增强Placement Constraint、Apache Slider框架
- 问题:架构老旧,扩展性差
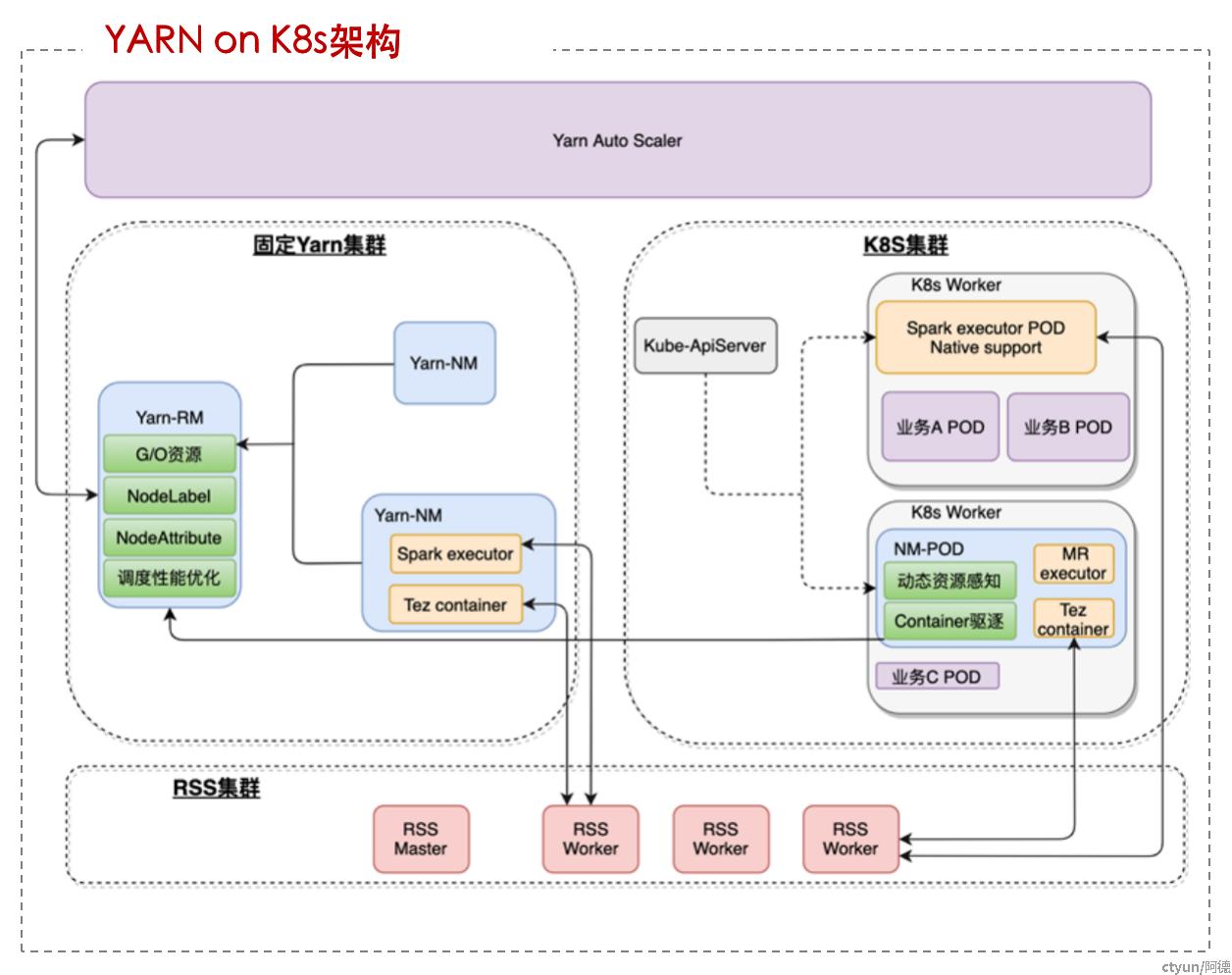
YARN on K8s
- 优势:
- 集群规模大,满足batch作业性能需求
- 任务迁移成本低
- 问题:
- 两套系统异步执行,使得在离线容器只能旁路管控,存在 race;且中间环节资源损耗过多
- 对在离线负载的抽象简单,无法描述复杂 QoS 要求
- 在离线元数据割裂,极致的优化困难,无法实现全局调度优化
调度:统一到K8s的混部方案v2
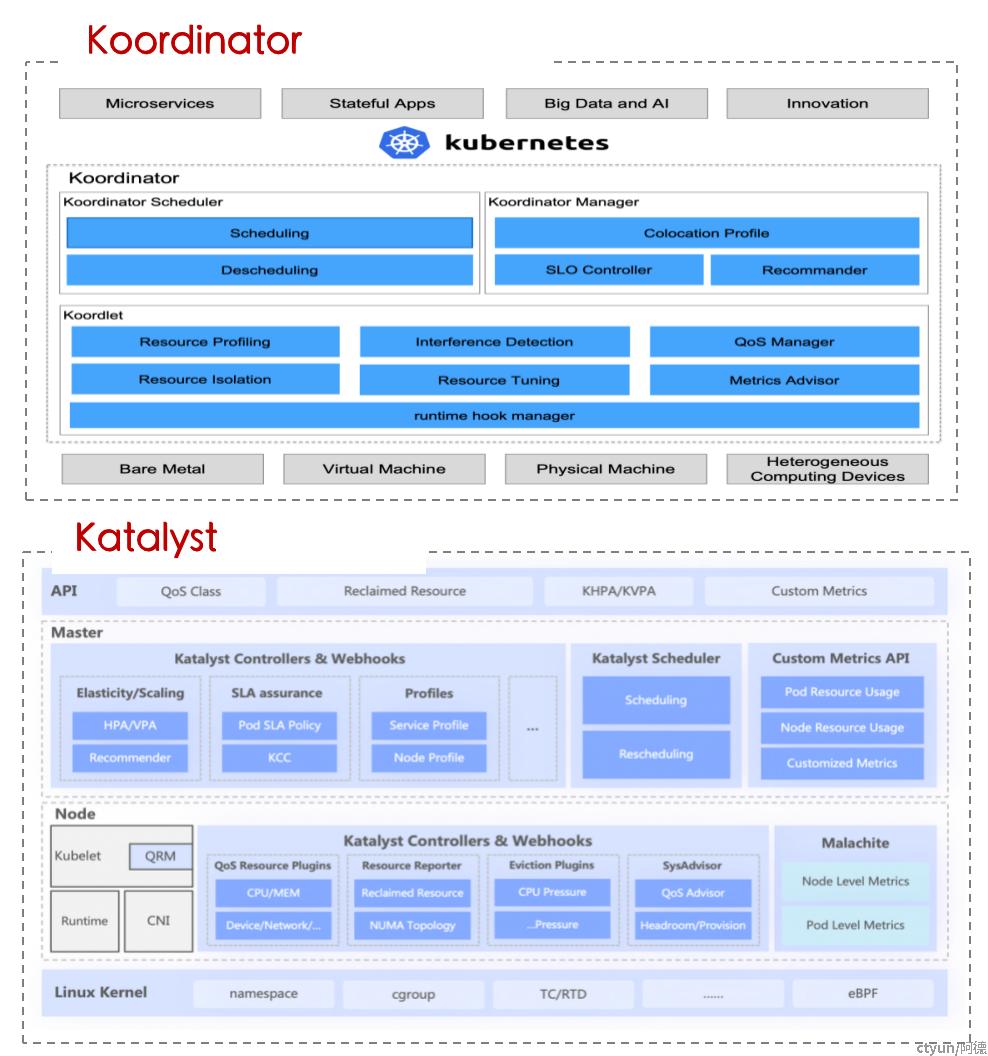
混部基础:大数据云原生化
- 增强K8s:Borg、CNCF Vocalno(podgroup、vcjob)、Apache Yunikorn、Kubewharf,解决原生调度只支持服务编排,性能吞吐差,缺少弹性quota、gang scheduling等功能的问题
- 增强计算引擎:Spark/Flink Native on K8s、Remote Shuffle Service(Google Dataflow Shuffle、Apache Celeborn、Apache Uniffle、Baidu DCE、Meta Cosco、Uber Zeus、Firestorm、LinkedIn Magnet)
- 存算分离+缓存加速:Juicefs、Alluxio、JindoFs、GooseFS、RapidFS
混部平台化:资源、管控、调度等多维度扩展
- 双零侵入,超低接入成本:K8s、计算引擎零侵入
- 抽象标准化:打通元数据,对复杂work load场景抽象QoS标准
- 管控同步化:容器启动时下发管控策略,避免在启动后异步修正资源调整,同时支持策略的自由扩展
- 策略智能化:通过构建服务画像提前感知资源诉求,实现更智能的资源管控策略;
- 运维自动化:一体化的交付,实现运维自动化和标准化
计算引擎: Single-Engine
今年2场大战
- Databricks VS Snowflake:2者的年度大会同时在6月份举行,2021年底互撕性能的延续
- Databricks:deltalake + photon(spark)的数据湖支持数仓一体,TPC-DS性能创新纪录,指责sf改输入数据
- Snowflake:数仓拥抱数据湖,类MPP架构,4XL 数据仓库有2倍性能
- Apache Flink VS RisingWave:
- RisingWave:Nexmark性能测试RisingWave比Flink快十倍,MPP架构
- Flink:指责RW测试参数架构和修改query和数据
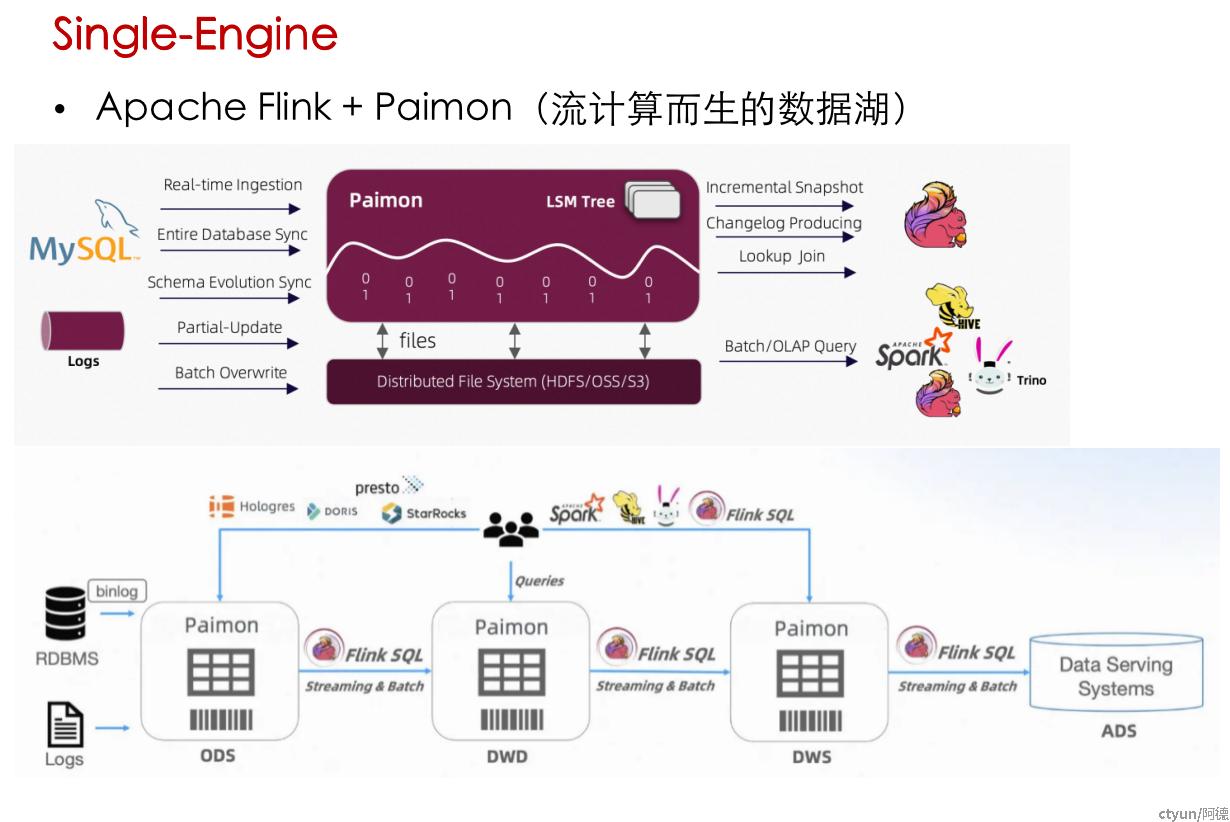
技术架构演进
- 流批一体(Flink vs Spark),通用计算引擎vs MPP,Lambda vs Kappa,数据湖vs数仓,Single-Engine支持大数据流、批、OLAP + AI
计算引擎:高性能
背景
- NVME、RDMA等新硬件的应用,传统的大数据计算瓶颈已从IO转移到CPU计算
- CPU SIMD指令集:Single Instruction Multiple Data,单指令处理多数据
业界现状
- Databricks:闭源的Photon执行引擎,企业版核心竞争力
- WeldIR Codegen模式
- 鲲鹏ARM指令集上的部分优化
技术挑战
- 多种CPU架构/指令集需要兼容、适配
- 基于JVM的计算引擎无法直接利用SIMD
- 数据全流程的列式存储、计算:内存管理、(反)序列化Shuffle等;涉及算子、函数多;Fallback机制
- 开发难度大:Native Code且深入指令集编程/Debug难,性能瓶颈探查既要经验又需敏锐,稳定性挑战大
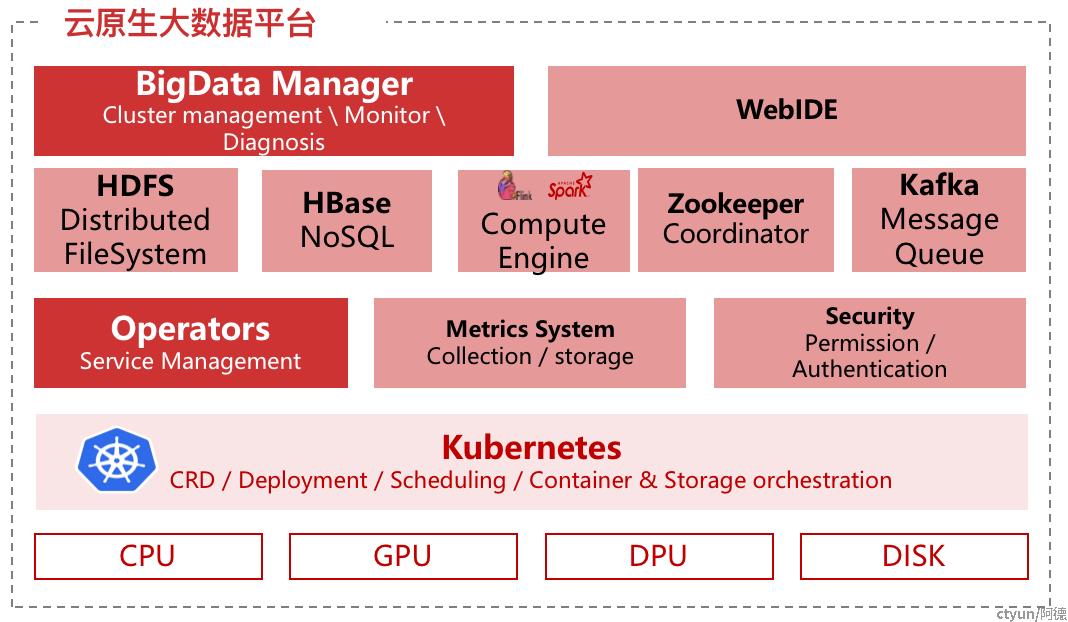
大数据Serverless平台
需求 Simplicity:大数据Serverless化
方案:
传统EMR独立集群
-
- 强隔离:独立ECS
- 弹性伸缩:core + 伸缩计算节点
- 运维难度大 组件多且管理复杂 集群数量膨胀
共享Hadoop大集群
-
- 隔离弱:调度队列+CGroups
- 只能限制功能:无UDF的SQL

云原生Serverless平台
挑战
- Backend as a Service
- 统一运维保障
- 统一资源池:引擎资源需求互补,高利用率,超卖高利润
- 多租户:安全/性能强隔离
- 解决爆炸半径大
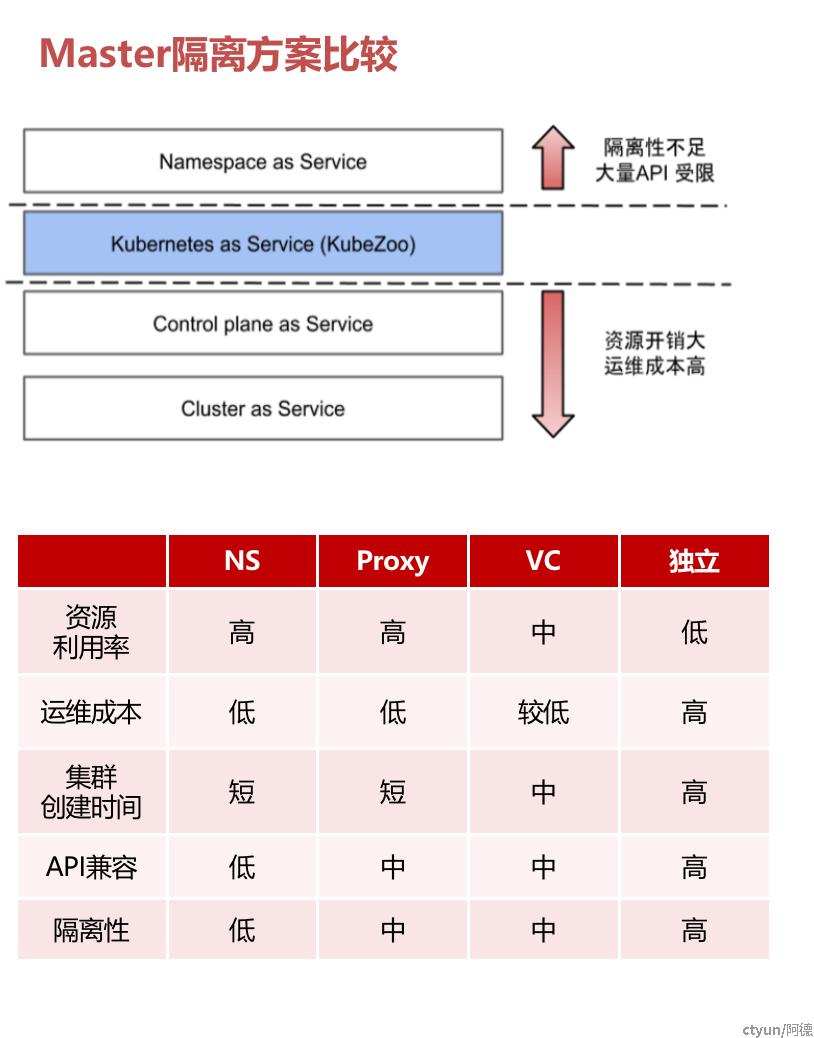
- 产品SaaS化,用户免运维,门槛低
解决方案
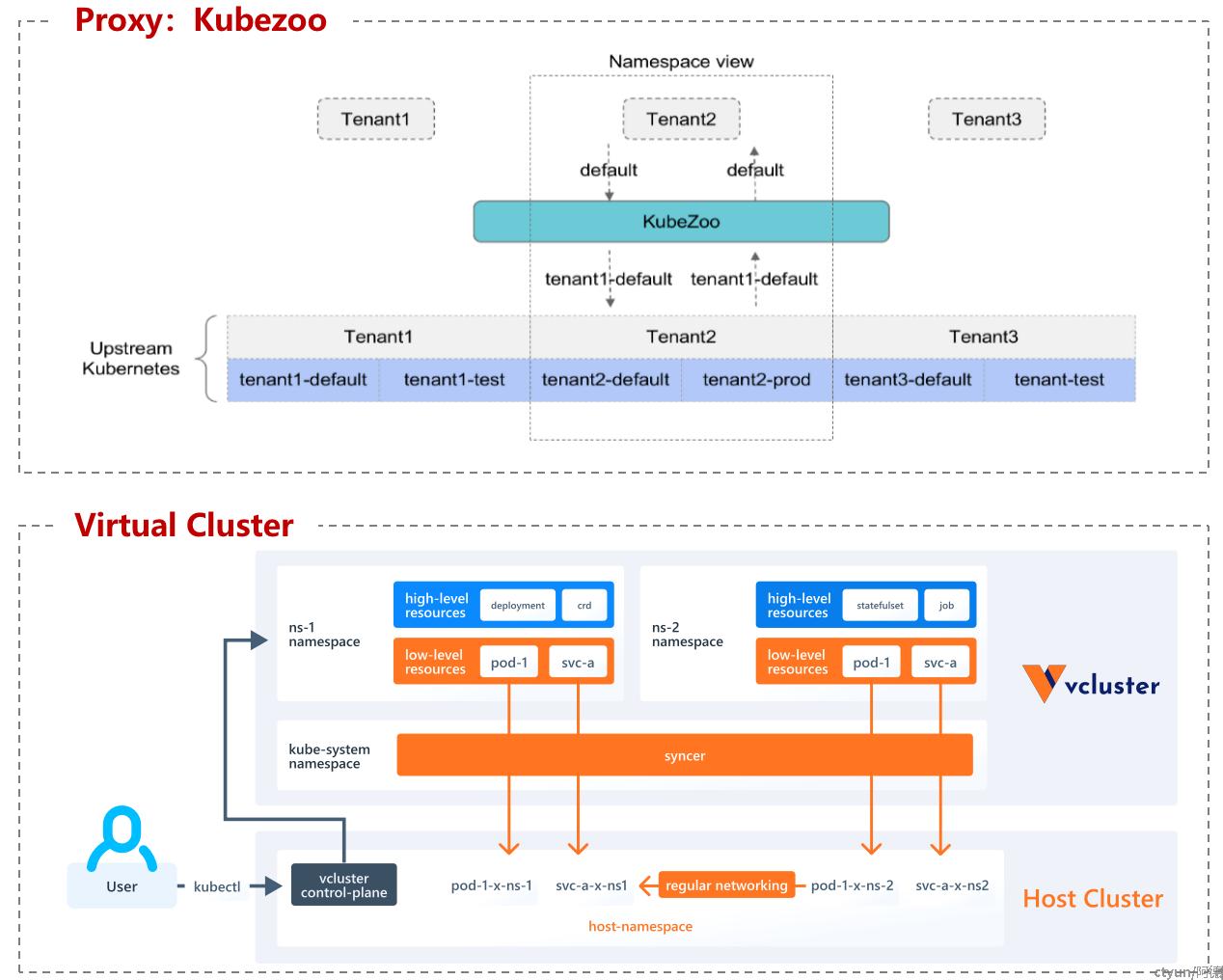
- 计算节点侧的隔离

- Master侧隔离