


简单来说,ringbuffer算法的理解精华如下:
- 用一个固定的地址段,利用首尾相接的特性,达成”逻辑“环形,因此不再有逻辑首尾概念;
- 分别操作写指针和读指针,读写都只能先进先出,写相当于入栈,读相当于出栈;
- 当写的内容超出固定长度时可根据策略覆盖或拋异常;
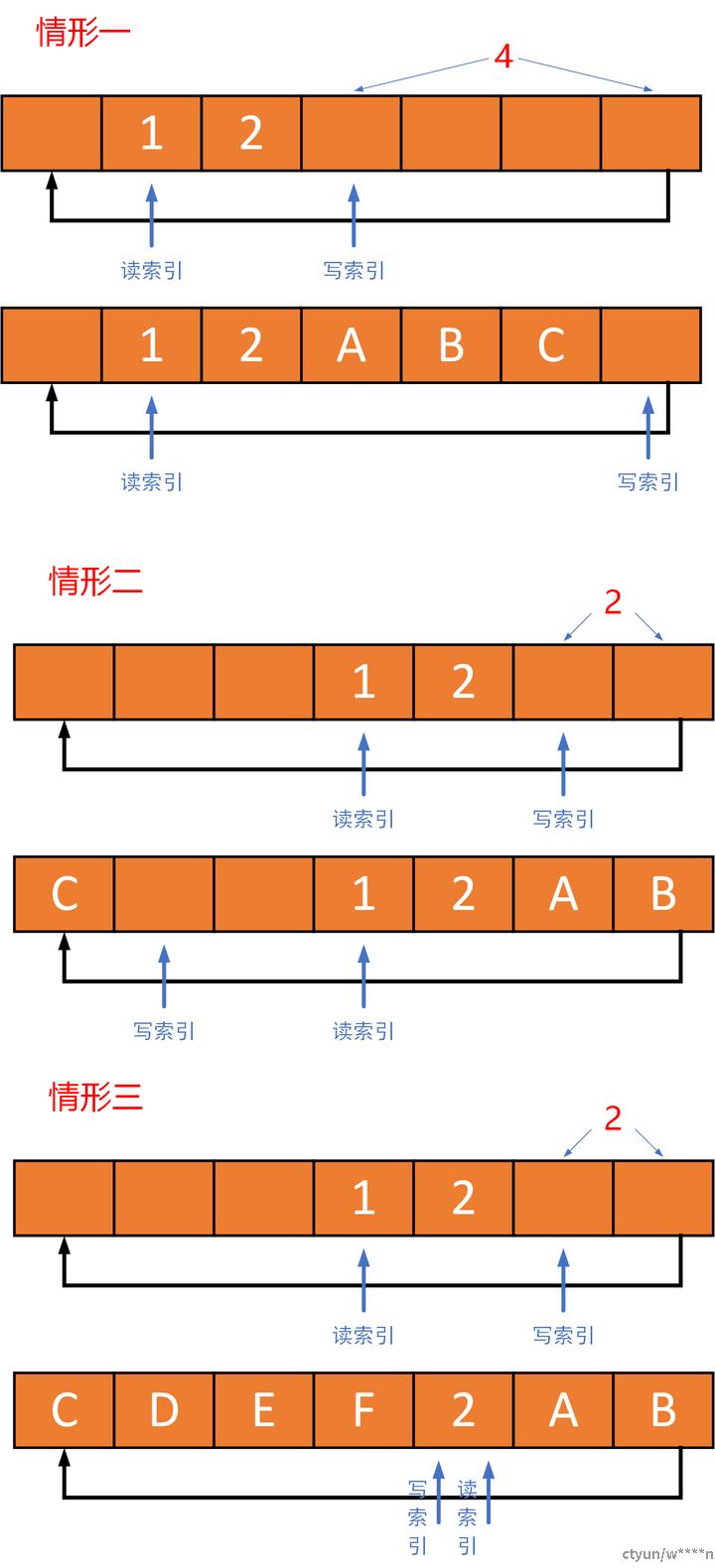
- 缓冲区(固定地址段)长度设为2的幂,是为了省略镜像指示位(用于判断缓冲区是否已满):如果读写指针的值相等,则缓冲区为空;如果读写指针相差n(缓冲区大小),则缓冲区为满;
- 单线程读写无需加锁,多线程读写需要锁保护,但这会极大降低效率;
- out(读指针) 永远不会超过in(写指针) 的大小,最多两者相等,相等就是缓冲区为空的时候;
- 读写指针的取值范围是整个
unsigned int,非溢出情况下一直正向增加,所以需要用取余算式算出索引值,定位具体读写的物理位置; - 对于2的幂的缓冲区
“读索引=读指针%缓冲区长度”这个操作可以等价于更高效的"读索引=读指针&(缓冲区长度-1)” - 对于写索引到缓冲区空间不足以写下所有内容情况,需要拆分成两段来写,尤其还要考虑到是否会覆盖已有数据。这也是最难理解的部分
典型的ring buffer结构体如下,其中in、out分别是写指针和读指针,而不是写索引和读索引。它们之间的转换关系见上。参数lock是自旋锁
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};更详细的说明可以自行搜索”ring buffer,一篇文章讲透它“。这篇文章写的非常详细
BPF简单来说就是:
- 用户态接收内核中的内应(埋点)过滤并推送出来的信息,然后显示或加以利用的过程;
- 内核推出来的信息通过写指针放入缓冲区,用户态通过读针读出缓冲区内容,操作都使用memcpy
- 内核埋点更新换代极快,它的基础设施是内核中的BTF,变化也很快,跨版本支持困难极大,因此才有了btfhuber及eunomia-bpf这些跨版本支持项目
很多场景下,BPF 程序都需要将数据发送到用户空间(userspace), BPF perf buffer(perfbuf)是目前这一过程的事实标准,但它存在一些问题,例如 浪费内存(因为其 per-CPU 设计)、事件顺序无法保证等。作为改进,内核 5.8 引入另一个新的 BPF 数据结构:BPF ring buffer(环形缓冲区,ringbuf),相比 perf buffer,它内存效率更高、保证事件顺序,性能也不输前者;在使用上,既提供了与 perf buffer 类似的 API ,以方便用户迁移;又提供了一套新的 reserve/commit API(先预留再提交),以实现更高性能。此外,实验与真实环境的压测结果都表明,从 BPF 程序发送数据给用户空间时, 应该首选 BPF ring buffer。
1 ringbuf 相比 perfbuf 的改进
perfbuf 是 per-CPU 环形缓冲区(circular buffers),能实现高效的 “内核-用户空间”数据交互,在实际中也非常有用,但 per-CPU 的设计 导致两个严重缺陷:
- 内存使用效率低下(inefficient use of memory)
- 事件顺序无法保证(event re-ordering)
因此内核 5.8 引入了 ringbuf 来解决这个问题。 ringbuf 是一个“多生产者、单消费者”(multi-producer, single-consumer,MPSC) 队列,可安全地在多个 CPU 之间共享和操作。perfbuf 支持的一些功能它都支持,它还解决了 perfbuf 的下列问题:
- 内存开销(memory overhead);
- 数据乱序;
- 无效的处理逻辑和不必要的数据复制(extra data copying)
2 ringbuf 使用场景和性能
2.1 常规场景
对于所有实际场景(尤其是那些基于 bcc/libbpf 的默认配置在使用 perfbuf 的场景), ringbuf 的性能都优于 perfbuf 性能。
2.2 高吞吐场景
Per-CPU buffer 特性的 perfbuf 在理论上能支持更高的数据吞吐, 但这只有在每秒百万级事件(millions of events per second)的场景下才会显现。
2.3 不可掩码中断(non-maskable interrupt)场景
唯一需要注意、最好先试验一下的场景:BPF 程序必须在 NMI (non-maskable interrupt) context 中执行时,例如处理 cpu-cycles 等 perf events 时。ringbuf 内部使用了一个非常轻量级的 spin-lock,这意味着如果 NMI context 中有竞争,data reservation 可能会失败。 因此,在 NMI context 中,如果 CPU 竞争非常严重,可能会 导致丢数据,虽然此时 ringbuf 仍然有可用空间。
3 ringbuf测试用例
这是我改写后的例子 bpf-ringbuf-examples(可在gitee上自行搜索)
$./build.sh
$cd src && ./test #run a background command listening test
or you can run ./ringbuf-output by yourself
TIME PID UID TASK COMM FILENAME
08:38:54 5553 1000 18446619934139534464 df /usr/bin/df
08:41:44 5555 1000 18446619934139534464 crontab /usr/bin/crontab
08:41:44 5556 1000 18446619934139540992 sh /bin/sh
08:41:44 5557 1000 18446619934906430208 sensible-editor /usr/bin/sensible-editor
08:41:44 5559 1000 18446619934311782784 select-editor /usr/bin/select-editor
08:41:44 5560 1000 18446619934244772224 touch /usr/bin/touch
08:41:44 5563 1000 18446619934262748672 wc /usr/bin/wc
08:41:44 5562 1000 18446619934142791680 update-alternat /usr/bin/update-alternatives
08:41:44 5564 1000 18446619934253868544 gettext /usr/bin/gettext
08:41:44 5569 1000 18446619934262650368 cut /usr/bin/cut
08:41:44 5568 1000 18446619934262630784 sort /usr/bin/sort
08:41:44 5566 1000 18446619934195567744 update-alternat /usr/bin/update-alternatives
08:41:44 5570 1000 18446619934262748672 expr /usr/bin/expr
08:41:44 5571 1000 18446619934262768384 gettext /usr/bin/gettext
08:41:44 5572 1000 18446619934262781440 expr /usr/bin/expr
08:41:44 5573 1000 18446619934203353472 expr /usr/bin/expr
08:41:44 5574 1000 18446619934203373056 expr /usr/bin/expr
08:41:44 5575 1000 18446619934215831552 true /bin/true
08:41:44 5576 1000 18446619934152838272 gettext /usr/bin/gettext
08:41:55 5577 1000 18446619934152838272 true /bin/true
08:41:55 5578 1000 18446619934215831552 expr /usr/bin/expr
08:41:55 5579 1000 18446619934203373056 expr /usr/bin/expr
08:41:55 5581 1000 18446619934141874176 sh /usr/bin/sh
08:41:55 5582 1000 18446619934141900288 vim.basic /usr/bin/vim.basic
^C这个例子中我扩展了BPF侦听程序的探测项,并将之运行在后台,同时循环执行shell指令,我们便能直观看到所有系统指令运行情况。
值得注意的是由于bpf ring buffer是在5.8内核引入的,因此如果想在4.19内核上compile & run这个例子,就需要做内核特性的回合。
但是5.x相比于4.x在bpf上的代码改动是巨大的,很多更基础的设施在4.x上都是不存在的,因此回合工作异常艰难,我们在下个章节再详细介绍。