eGPU是天翼云基础架构部针对英伟达GPU研发的基于内核虚拟化的容器共享技术,支持多个容器共享一张GPU卡并提供算力、显存、故障强隔离能力,从而实现业务的的安全运行,达到提升GPU利用率、降低用户使用成本的目的。
针对eGPU的测试将在虚拟机中展开,使用的显卡是NVIDIA Tesla V100共4块,详细的环境软硬件信息如下。
表1 测试硬件信息
|
硬件项名称 |
硬件详细信息 |
|
服务器型号 |
Red Hat KVM RHEL 7.6.0 PC(i440FX+PIIX,1996) |
|
CPU个数 |
32 |
|
CPU核数 |
1 |
|
CPU型号 |
Intel Xeon Processor (Skylake, IBRS) |
|
NUMA信息 |
1 |
|
内存条数 |
4 |
|
内存容量 |
64GB |
|
硬盘数量 |
2 |
|
硬盘容量 |
1TB |
|
在用网卡数量 |
3 |
|
在用网卡型号 |
|
|
在用GPU卡数量 |
4 |
|
在用GPU卡型号 |
NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] |
表2 测试软件信息
|
名称 |
信息 |
|
操作系统 |
CentOS Linux release 7.9.2009(Core) |
|
内核 |
4.19.125-300.el7.ctyun.x86_64 |
./NVIDIA-Linux-x86_64-515.48.07.run
安装docker和nvidia-container-toolkit
在线安装docker
在线安装nvidia-container-toolkit
进入egpu/buildrun_tools目录下
./buildrun.sh -v 0.9

生成如下.run包 该包最终交付给客户

执行 run包 检验eGPU是否安装成功

其中egpu用于显存隔离等基础功能,egpu_scheduler用于算力隔离、调度策略、热更新等高级功能
训练数据:/home/ljs/TrainData
镜像包:ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0
预期结果:(1)nvidia-smi: 0MiB/ 3276 MiB(2)OOM报错
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=3276,WEIGHT=10:PGPU=1,MEM=3276,WEIGHT=10:PGPU=2,MEM=3276,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
1 |
nvidia-smi |
|
2 |
cd /root/TestSample/d2l-zh/test/ && python resnet.py --gpu 0 --batch_size 1280 |
- 测试结果
docker run命令启动容器,指定容器分别使用物理卡0、1、2上3276 MB显存和10%的算力,成功创建将返回容器id。

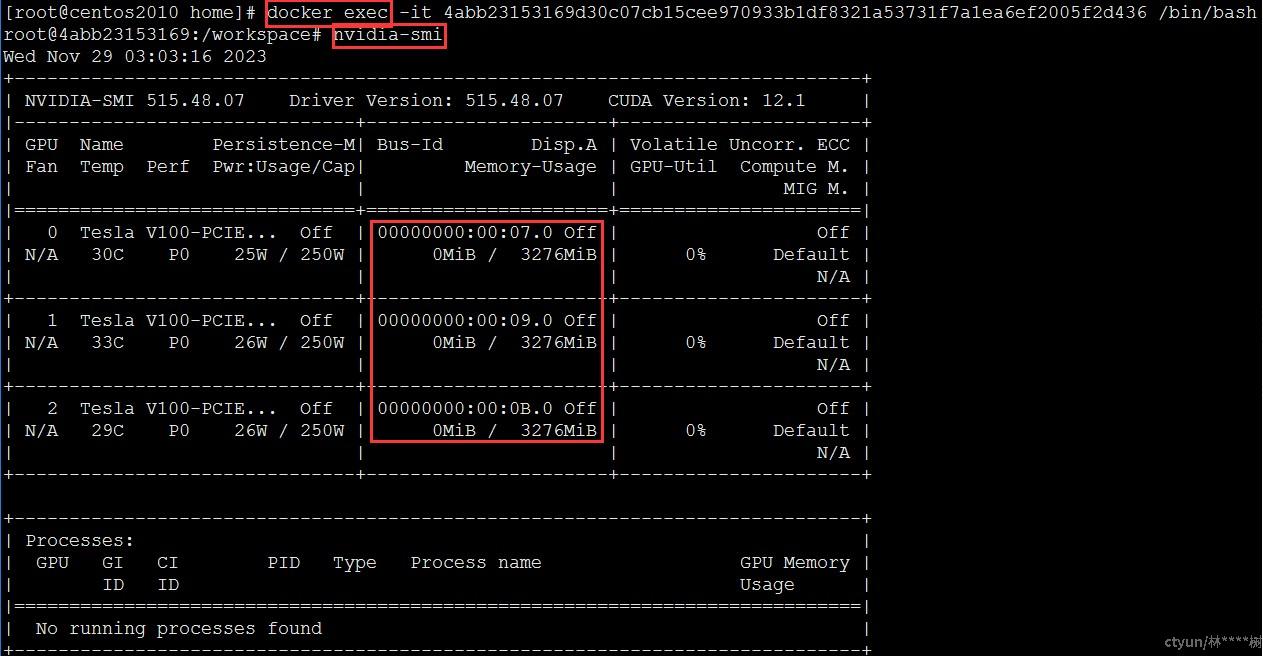
docker exec命令以交互形式在容器内部进行操作,nvidia-smi用于查看与NVIDIA GPU相关的信息和状态,例如硬件信息、状态监控等,这里关注显存大小0MiB/ 3276MiB,用于验证eGPU显存隔离能力。
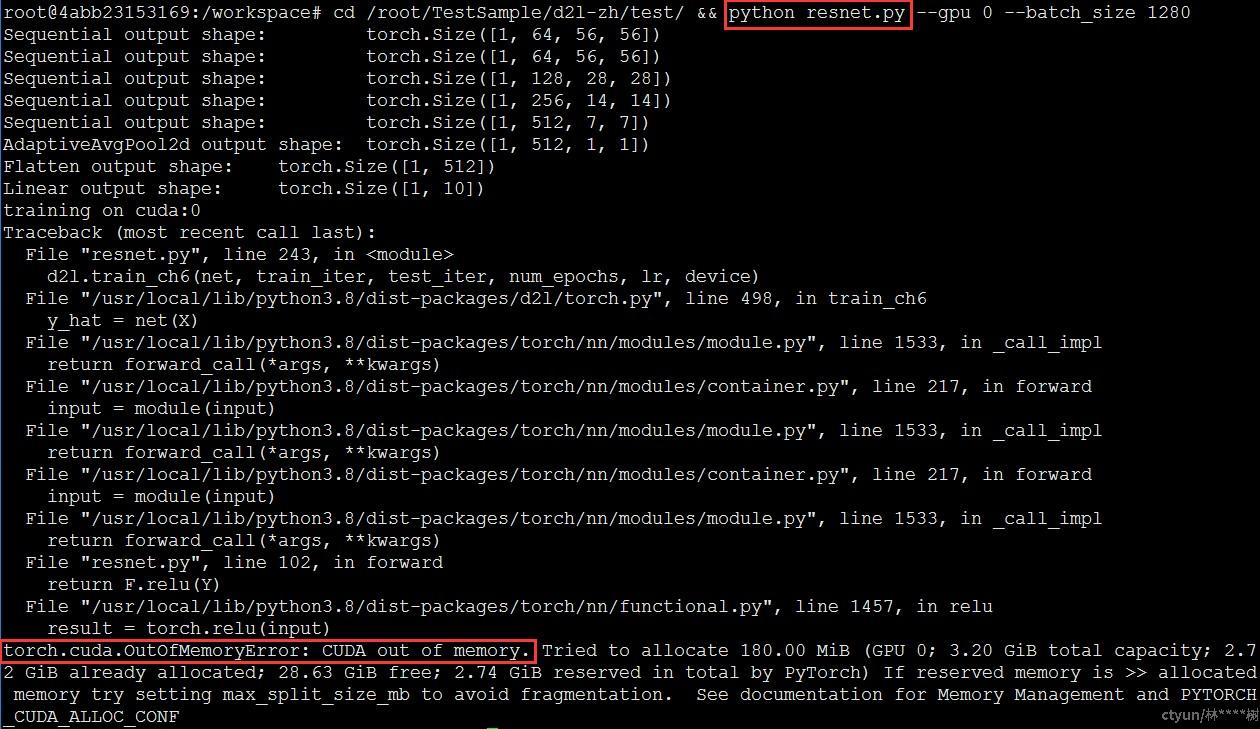
算例已通过docker –v数据卷挂载至容器内,执行算例python resnet.py查看结果。由于容器内最大显存配额为3.2G,算例所需显存约为7.6G,不满足算例所需显存,显存OOM报错无法执行,符合预期结果,测试通过。
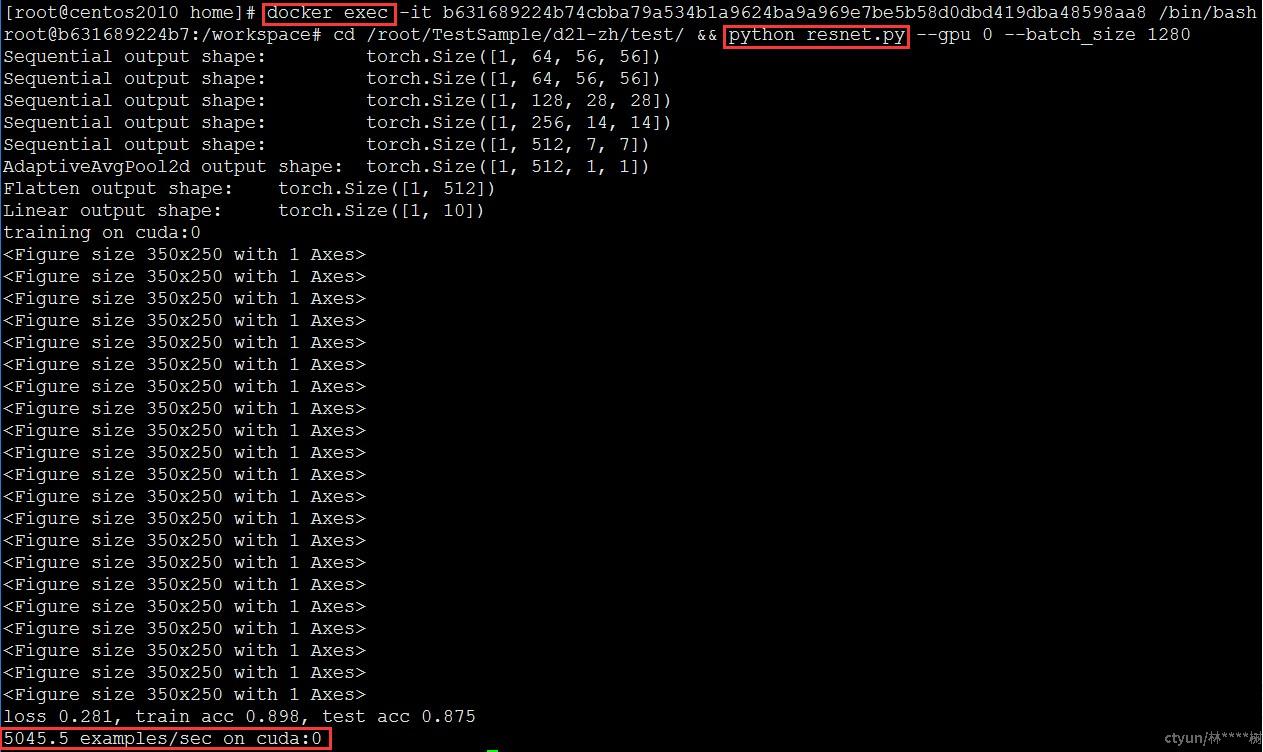
预期结果:(1)nvidia-smi:8192 MB(2)500 examples/sec
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=8192,WEIGHT=10:PGPU=1,MEM=8192,WEIGHT=10:PGPU=2,MEM=8192,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
1 |
nvidia-smi |
|
2 |
cd /root/TestSample/d2l-zh/test/ && python resnet.py --gpu 0 --batch_size 1280 |
- 测试结果
docker run命令启动容器,指定容器分别使用物理卡0、1、2上8192 MB显存和10%的算力,成功创建将返回容器id。

docker exec命令以交互形式在容器内部进行操作,nvidia-smi用于查看与NVIDIA GPU相关的信息和状态,例如硬件信息、状态监控等,这里关注显存大小0MiB/ 8192MiB,用于验证eGPU显存隔离能力。

算例已通过docker –v数据卷挂载至容器内,执行算例python resnet.py查看结果。由于容器内最大显存配额为8G,算例所需显存约为7.6G,满足算例所需显存,正常执行,训练结果为498.1 examples/sec,符合预期结果,测试通过。
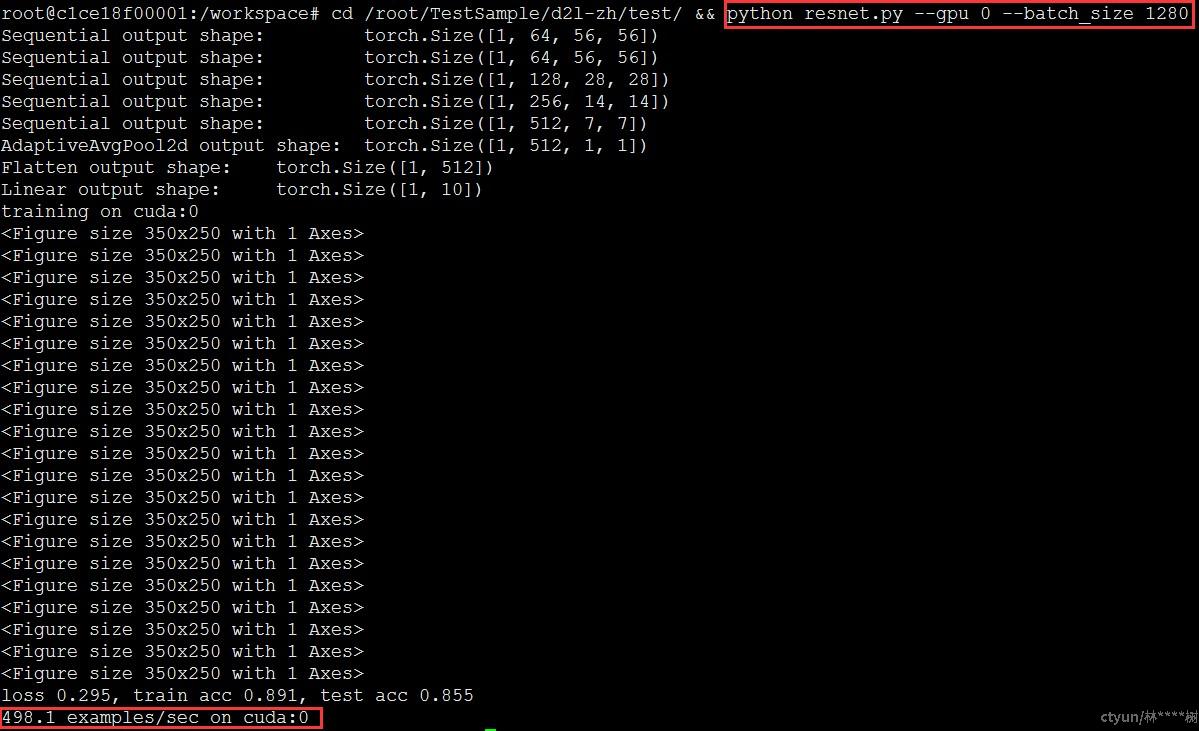
预期结果:500 examples/sec
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=10240,WEIGHT=10:PGPU=1,MEM=10240,WEIGHT=10:PGPU=2,MEM=10240,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
cd /root/TestSample/d2l-zh/test/ && python resnet.py --gpu 0 --batch_size 1280 |
- 测试结果
docker run命令启动容器,指定容器分别使用物理卡0、1、2上10240 MB显存和10%的算力,成功创建将返回容器id。

docker exec命令以交互形式在容器内部进行操作,上一节已验证eGPU显存隔离能力,这里关注算力隔离能力。算例已通过docker –v数据卷挂载至容器内,执行算例python resnet.py查看结果,训练结果为499.7 examples/sec,符合预期结果,测试通过。
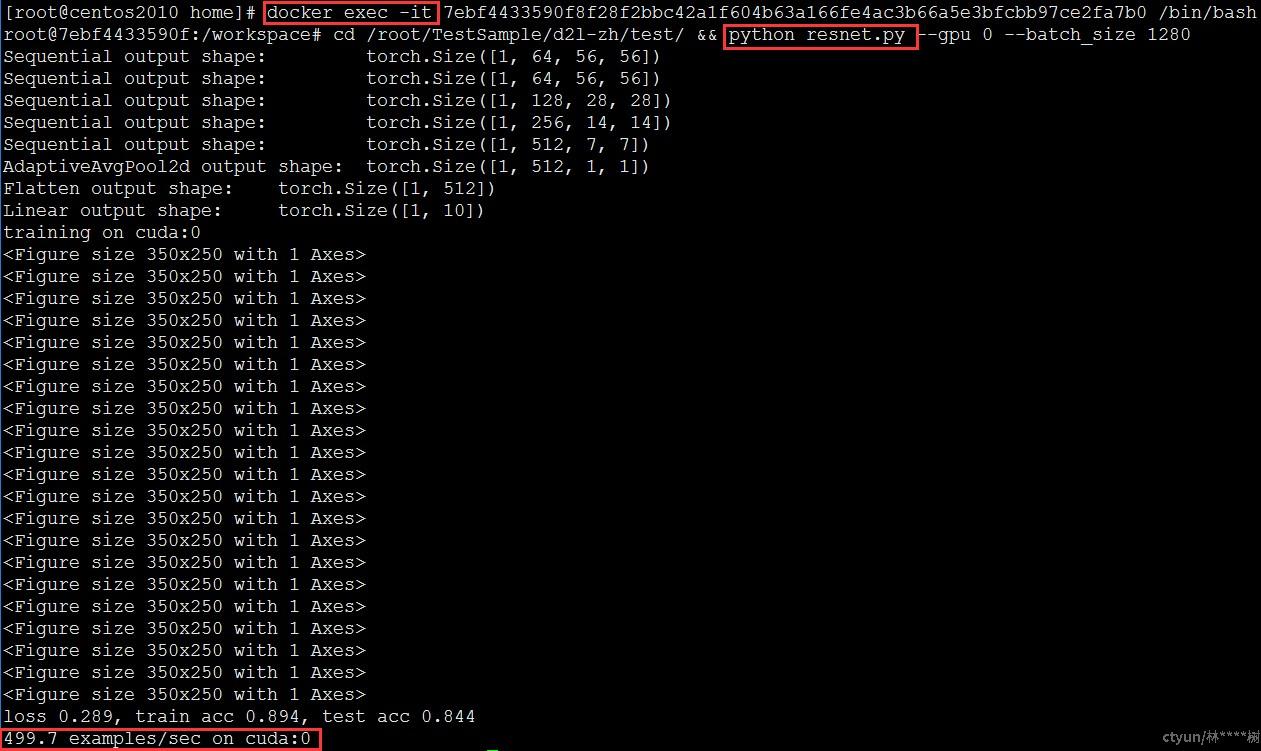
预期结果:2550 examples/sec
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=10240,WEIGHT=50:PGPU=1,MEM=10240,WEIGHT=50:PGPU=2,MEM=10240,WEIGHT=50" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
cd /root/TestSample/d2l-zh/test/ && python resnet.py --gpu 0 --batch_size 1280 |
- 测试结果
docker run命令启动容器,指定容器分别使用物理卡0、1、2上10240 MB显存和50%的算力,成功创建将返回容器id。

docker exec命令以交互形式在容器内部进行操作,算例已通过docker –v数据卷挂载至容器内,执行算例python resnet.py查看结果,训练结果为2551.3 examples/sec,符合预期结果,测试通过。
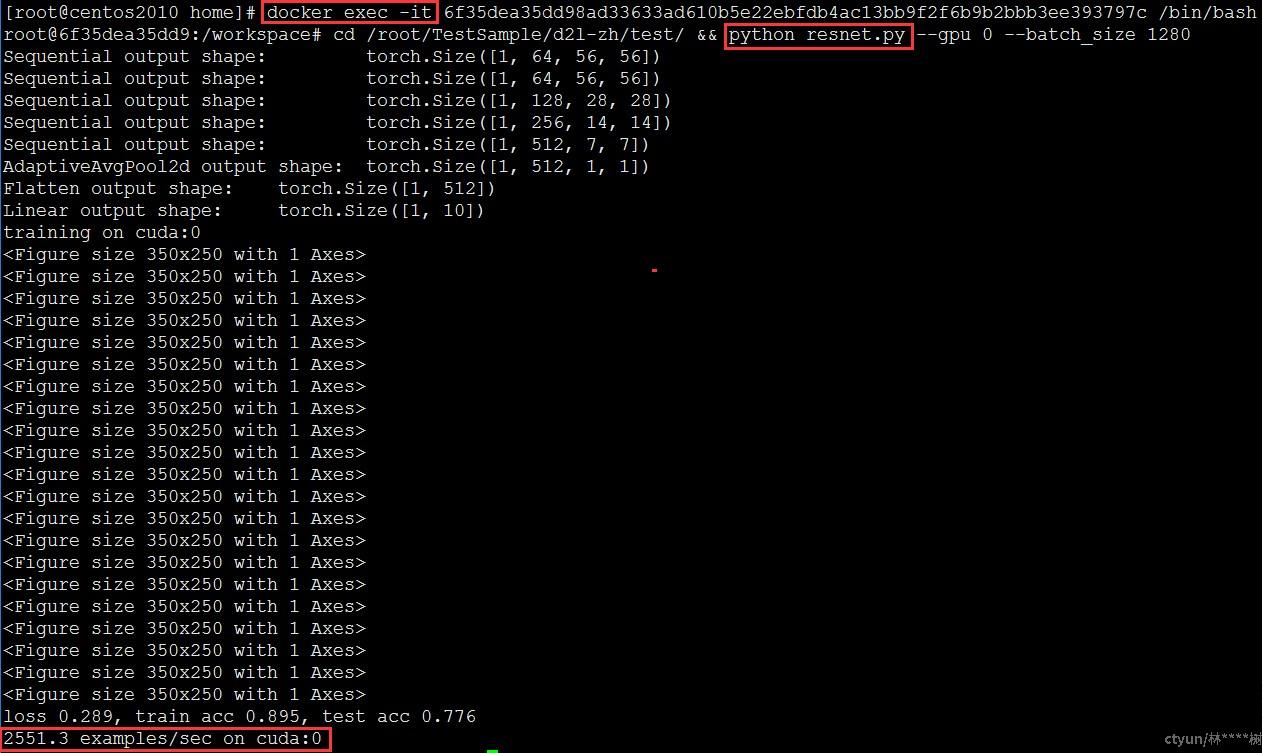
预期结果:5040 examples/sec
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=10240,WEIGHT=100:PGPU=1,MEM=10240,WEIGHT=100:PGPU=2,MEM=10240,WEIGHT=100" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
cd /root/TestSample/d2l-zh/test/ && python resnet.py --gpu 0 --batch_size 1280 |
- 测试结果
docker run命令启动容器,指定容器分别使用物理卡0、1、2上10240 MB显存和100%的算力,成功创建将返回容器id。

docker exec命令以交互形式在容器内部进行操作,算例已通过docker –v数据卷挂载至容器内,执行算例python resnet.py查看结果,训练结果为5045.5 examples/sec,符合预期结果,测试通过。
预期结果:容器创建失败
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=20480,WEIGHT=10:PGPU=1,MEM=20480,WEIGHT=10:PGPU=2,MEM=40960,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
cat /var/log/nvidia-egpu-prestart-hook.log |
- 测试结果
docker run命令启动容器,指定容器分别使用物理卡0、1、2上20480MB、20480MB、40960MB显存和10%、10%、10%的算力,成功创建将返回容器id,创建失败则销毁容器。由于显存配额为48G,超出物理卡限制(32G),创建容器失败,符合预期结果,测试通过。

使用cat命令查看/var/log/nvidia-egpu-prestart-hook.log,查看日志信息,其中包括回收前序预分配显存的回滚逻辑与容器销毁。
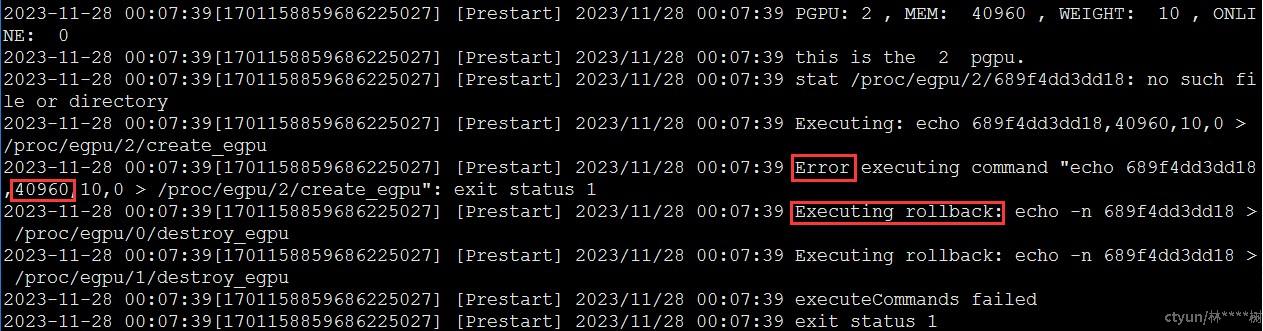
预期结果:容器4创建失败
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=20480,WEIGHT=10:PGPU=1,MEM=20480,WEIGHT=10:PGPU=2,MEM=10240,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=10240,WEIGHT=10:PGPU=1,MEM=10240,WEIGHT=10:PGPU=2,MEM=20480,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=2048,WEIGHT=10:PGPU=1,MEM=2048,WEIGHT=10:PGPU=2,MEM=2048,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=1024,WEIGHT=10:PGPU=1,MEM=1024,WEIGHT=10:PGPU=2,MEM=1024,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
cat /var/log/nvidia-egpu-prestart-hook.log |
- 测试结果
docker run命令启动容器,指定容器1使用物理卡0、1、2上20480MB、20480MB、10240MB显存和10%、10%、10%的算力,成功创建将返回容器id;指定容器2使用物理卡0、1、2上10240MB、10240MB、20480MB显存和10%、10%、10%的算力,成功创建将返回容器id;指定容器3使用物理卡0、1、2上2048MB、2048MB、2048MB显存和10%、10%、10%的算力,成功创建将返回容器id。至此3个容器显存累计占用已达物理卡限制(3*32G),指定容器4使用物理卡0、1、2上1024MB、1024MB、1024MB显存和10%、10%、10%的算力,容器创建失败,符合预期结果,测试通过。
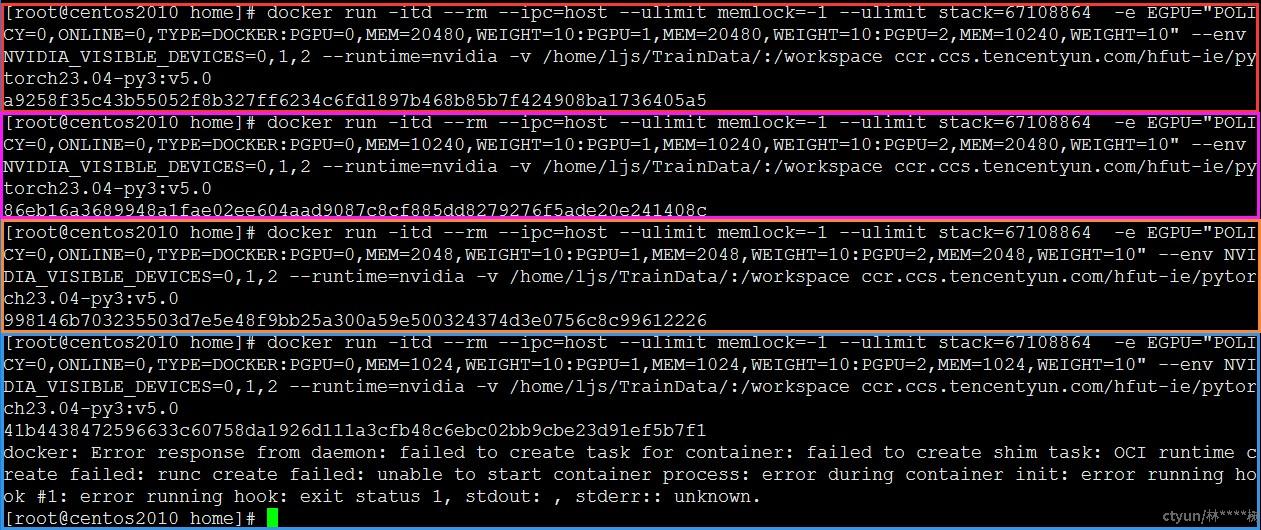
容器1、2、3分别占用物理卡1、2、3共3*32G显存,达到显存配额上限,对容器4进行显存分配报错。使用cat命令查看/var/log/nvidia-egpu-prestart-hook.log,查看日志信息。

预期结果:容器创建失败
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=20480,WEIGHT=10:PGPU=1,MEM=20480,WEIGHT=10:PGPU=2,MEM=10240,WEIGHT=110" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
cat /var/log/nvidia-egpu-prestart-hook.log |
- 测试结果
docker run命令启动容器,指定容器分别使用物理卡0、1、2上20480MB、20480MB、10240MB显存和10%、10%、110%的算力,成功创建将返回容器id,创建失败则销毁容器。算力配额为110%,超出物理卡限制(100%),创建容器失败,符合预期结果,测试通过。

使用cat命令查看/var/log/nvidia-egpu-prestart-hook.log,查看日志信息,单容器算力检测发生于参数校验阶段,并无预分配,减少无效操作提高资源利用率。
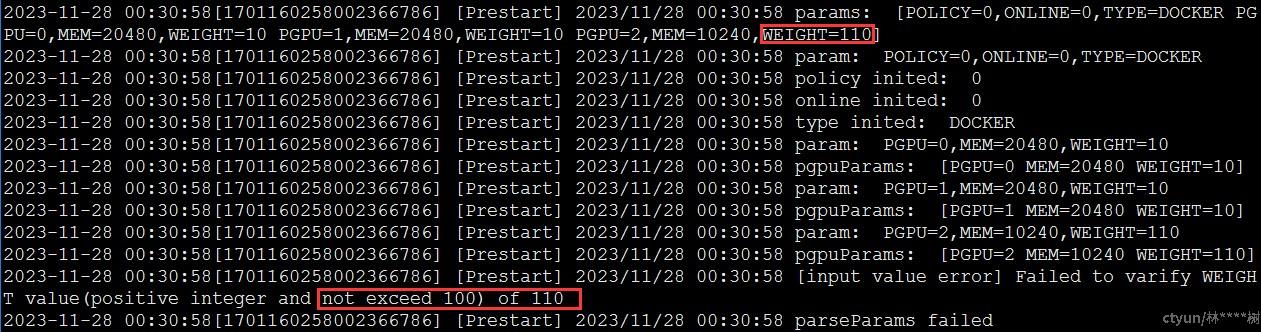
预期结果:容器4创建失败
是否通过:通过
测试命令:
- 容器启动命令
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=20480,WEIGHT=25:PGPU=1,MEM=20480,WEIGHT=25:PGPU=2,MEM=10240,WEIGHT=25" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=10240,WEIGHT=25:PGPU=1,MEM=10240,WEIGHT=25:PGPU=2,MEM=20480,WEIGHT=25" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=1024,WEIGHT=50:PGPU=1,MEM=1024,WEIGHT=50:PGPU=2,MEM=1024,WEIGHT=50" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
|
docker run -itd --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -e EGPU="POLICY=0,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=1024,WEIGHT=10:PGPU=1,MEM=1024,WEIGHT=10:PGPU=2,MEM=1024,WEIGHT=10" --env NVIDIA_VISIBLE_DEVICES=0,1,2 --runtime=nvidia -v /home/ljs/TrainData/:/workspace ccr.ccs.tencentyun.com/hfut-ie/pytorch23.04-py3:v5.0 |
- 执行命令
|
cat /var/log/nvidia-egpu-prestart-hook.log |
- 测试结果
docker run命令启动容器,指定容器1使用物理卡0、1、2上20480MB、20480MB、20480MB显存和25%、25%、25%的算力,成功创建将返回容器id;指定容器2使用物理卡0、1、2上10240MB、10240MB、10240MB显存和25%、25%、25%的算力,成功创建将返回容器id;指定容器3使用物理卡0、1、2上1024MB、1024MB、1024MB显存和50%、50%、50%的算力,成功创建将返回容器id。至此3个容器算力累计已达物理卡限制(3*100%),指定容器4使用物理卡0、1、2上1024MB、1024MB、1024MB显存和10%、10%、10%的算力,容器创建失败,符合预期结果,测试通过。
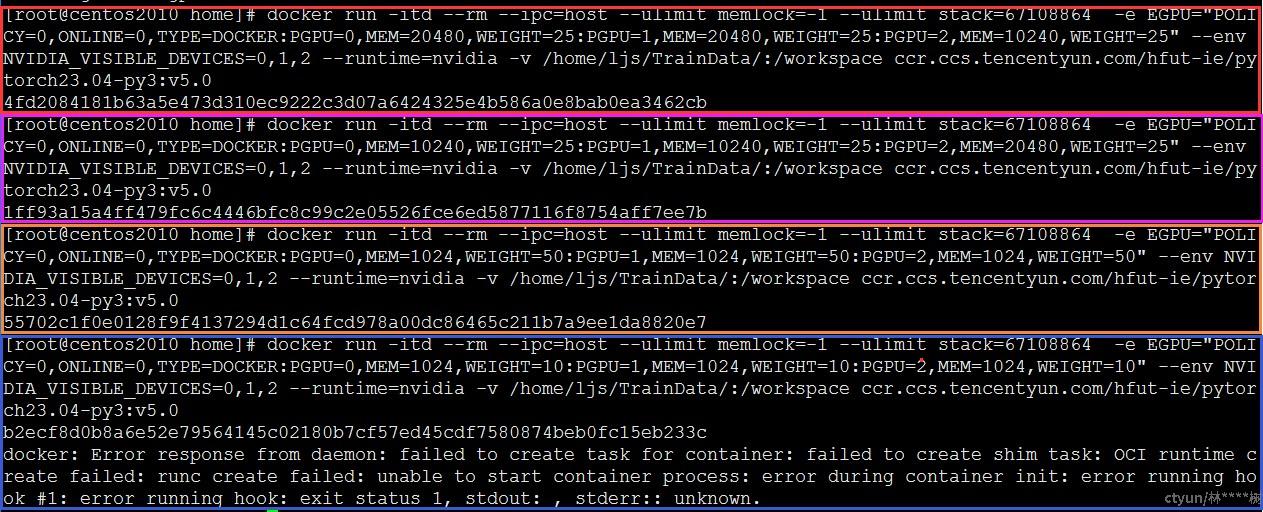
容器1、2、3分别占用物理卡1、2、3共3*100%算力,达到算力配额上限,对容器4进行算力分配报错。使用cat命令查看/var/log/nvidia-egpu-prestart-hook.log,查看日志信息。

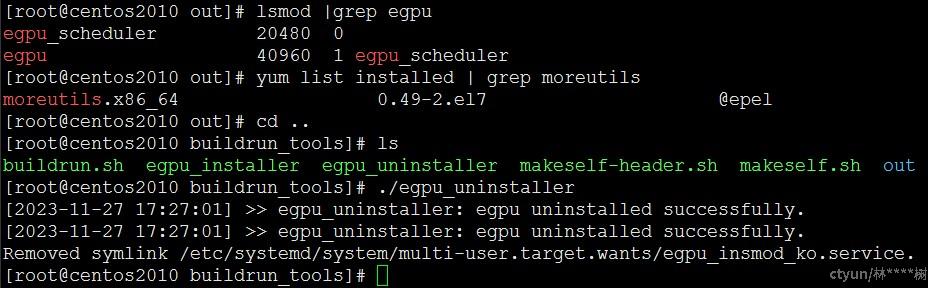
若存在使用eGPU的容器,卸载将会失败。因此eGPU在卸载前应确保销毁使用eGPU的容器,保证eGPU模块的引用计数为0方可正确被卸载。