社区专栏>GPT4o 真正的实时交互产品>
当各家科技公司还在追赶大模型多模态能力,把总结文本、P 图等功能放进手机里的时候,遥遥领先的 OpenAI 直接开了大招,发布的产品连自家 CEO 奥特曼都惊叹:就像电影里一样。
5 月 14 日凌晨,OpenAI 在首次「春季新品发布会」上搬出了新一代旗舰生成模型 GPT-4o、桌面 App,并展示了一系列新能力。这一次,技术颠覆了产品形态,OpenAI 用行动给全世界的科技公司上了一课。
今天的主持人是 OpenAI 的首席技术官 Mira Murati,她表示,今天主要讲三件事:
-
第一,以后 OpenAI 做产品就是要免费优先,为的就是让更多的人能使用。
-
第二,因此 OpenAI 此次发布了桌面版本的程序和更新后的 UI,其使用起来更简单,也更自然。
-
第三,GPT-4 之后,新版本的大模型来了,名字叫 GPT-4o。GPT-4o 的特别之处在于它以极为自然的交互方式为每个人带来了 GPT-4 级别的智能,包括免费用户。
ChatGPT 的这次更新以后,大模型可以接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合输出 —— 这才是属于未来的交互方式。
最近,ChatGPT 不用注册也可以使用了,今天又增加了桌面程序,OpenAI 的目标就是让人们可以随时随地的无感使用它,让 ChatGPT 集成在你的工作流中。这 AI 现在就是生产力了。GPT-4o 是面向未来人机交互范式的全新大模型,具有文本、语音、图像三种模态的理解力,反应极快还带有感情,也很通人性。在现场,OpenAI 的工程师拿出一个 iPhone 演示了新模型的几种主要能力。最重要的是实时语音对话,Mark Chen 说:「我第一次来直播的发布会,有点紧张。」ChatGPT 说,要不你深呼吸一下。
ChatGPT 立即回答说,你这不行,喘得也太大了。
如果你之前用过 Siri 之类的语音助手,这里就可以看出明显的不同了。首先,你可以随时打断 AI 的话,不用等它说完就可以继续下一轮对话。其次,你不用等待,模型反应极快,比人类的回应还快。第三,模型能够充分理解人类的情感,自己也能表现出各种感情。
随后是视觉能力。另一个工程师在纸上现写的方程,让 ChatGPT 不是直接给答案,而是让它解释要一步步怎么做。看起来,它在教人做题方面很有潜力。
接下来尝试 GPT-4o 的代码能力。这有一些代码,打开电脑里桌面版的 ChatGPT 用语音和它交互,让它解释一下代码是用来做什么的,某个函数是在做什么,ChatGPT 都对答如流。输出代码的结果,是一个温度曲线图,让 ChatGPT 以一句话的方式回应所有有关此图的问题。最热的月份在几月,Y 轴是摄氏度还是华氏度,它都能回答得上来。
OpenAI 还回应了一些 X/Twitter 上网友们实时提出的问题。比如实时语音翻译,手机可以拿来当翻译机来回翻译西班牙语和英语。
首先介绍的是 GPT-4o,o 代表 Omnimodel(全能模型)。第一次,OpenAI 在一个模型中集成了所有模态,大幅提升了大模型的实用性。OpenAI CTO Muri Murati 表示,GPT-4o 提供了「GPT-4 水准」的智能,但在 GPT-4 的基础上改进了文本、视觉和音频方面的能力,将在未来几周内「迭代式」地在公司产品中推出。「GPT-4o 的理由横跨语音、文本和视觉,」Muri Murati 说道:「我们知道这些模型越来越复杂,但我们希望交互体验变得更自然、更简单,让你完全不用关注用户界面,而只关注与 GPT 的协作。」GPT-4o 在英语文本和代码上的性能与 GPT-4 Turbo 的性能相匹配,但在非英语文本上的性能显著提高,同时 API 的速度也更快,成本降低了 50%。与现有模型相比,GPT-4o 在视觉和音频理解方面尤其出色。它最快可以在 232 毫秒的时间内响应音频输入,平均响应时长 320 毫秒,与人类相似。在 GPT-4o 发布之前,体验过 ChatGPT 语音对话能力的用户能够感知到 ChatGPT 的平均延迟为 2.8 秒 (GPT-3.5) 和 5.4 秒 (GPT-4)。这种语音响应模式是由三个独立模型组成的 pipeline:一个简单模型将音频转录为文本,GPT-3.5 或 GPT-4 接收文本并输出文本,第三个简单模型将该文本转换回音频。但 OpenAI 发现这种方法意味着 GPT-4 会丢失大量信息,例如模型无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。而在 GPT-4o 上,OpenAI 跨文本、视觉和音频端到端地训练了一个新模型,这意味着所有输入和输出都由同一神经网络处理。
「从技术角度来看,OpenAI 已经找到了一种方法,可以将音频直接映射到音频作为一级模态,并将视频实时传输到 transformer。这些需要对 token 化和架构进行一些新的研究,但总体来说是一个数据和系统优化问题(大多数事情都是如此)。」英伟达科学家 Jim Fan 如此评论道。
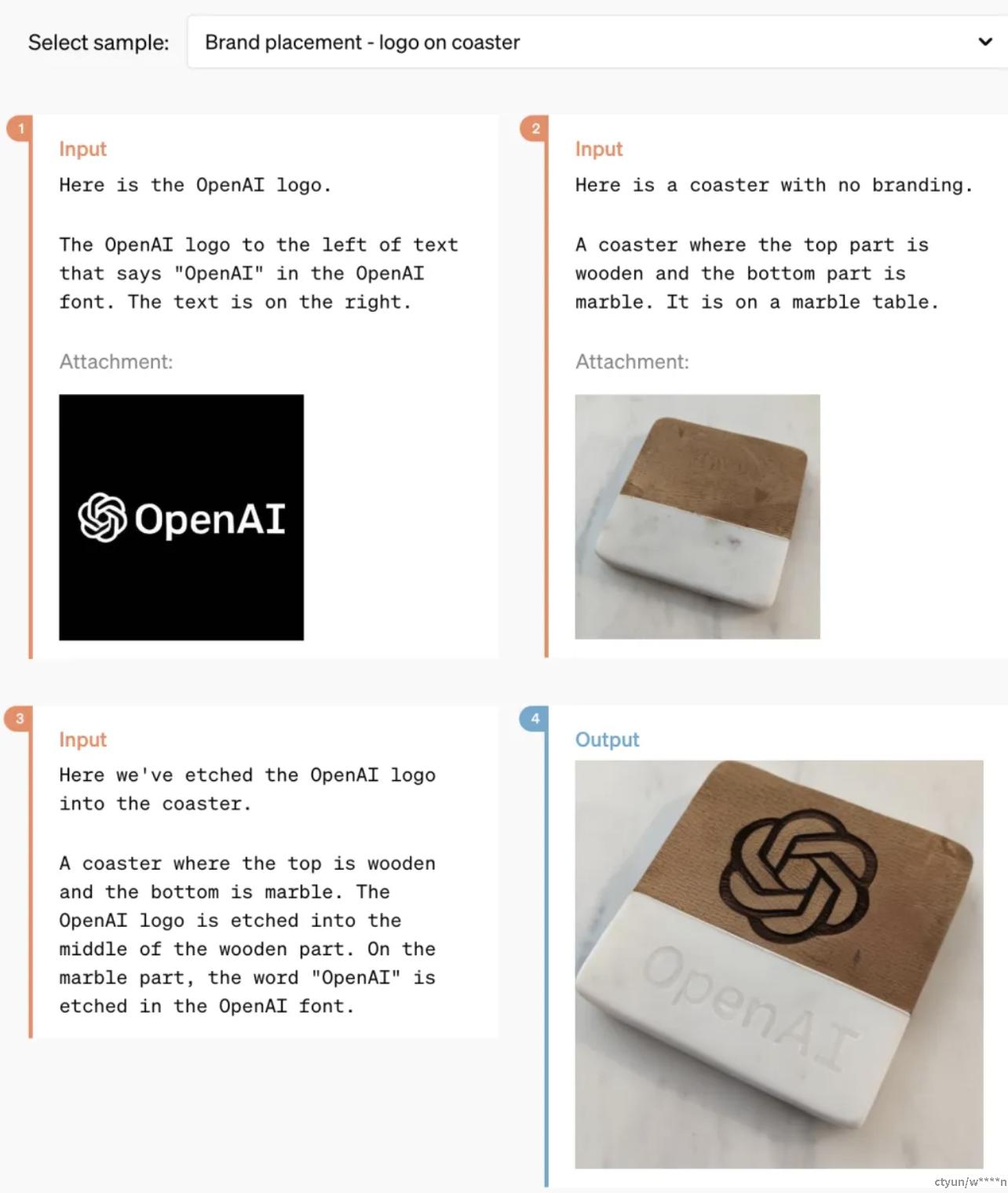
GPT-4o 可以跨文本、音频和视频进行实时推理,这是向更自然的人机交互(甚至是人 - 机器 - 机器交互)迈出的重要一步。OpenAI 总裁 Greg Brockman 也在线「整活」,不仅让两个 GPT-4o 实时对话,还让它们即兴创作了一首歌曲,虽然旋律有点「感人」,但歌词涵盖房间的装饰风格、人物穿着特点以及期间发生的小插曲等。此外,GPT-4o 在理解和生成图像方面的能力比任何现有模型都要好得多,此前很多不可能的任务都变得「易如反掌」。比如,你可以让它帮忙把 OpenAI 的 logo 印到杯垫上:
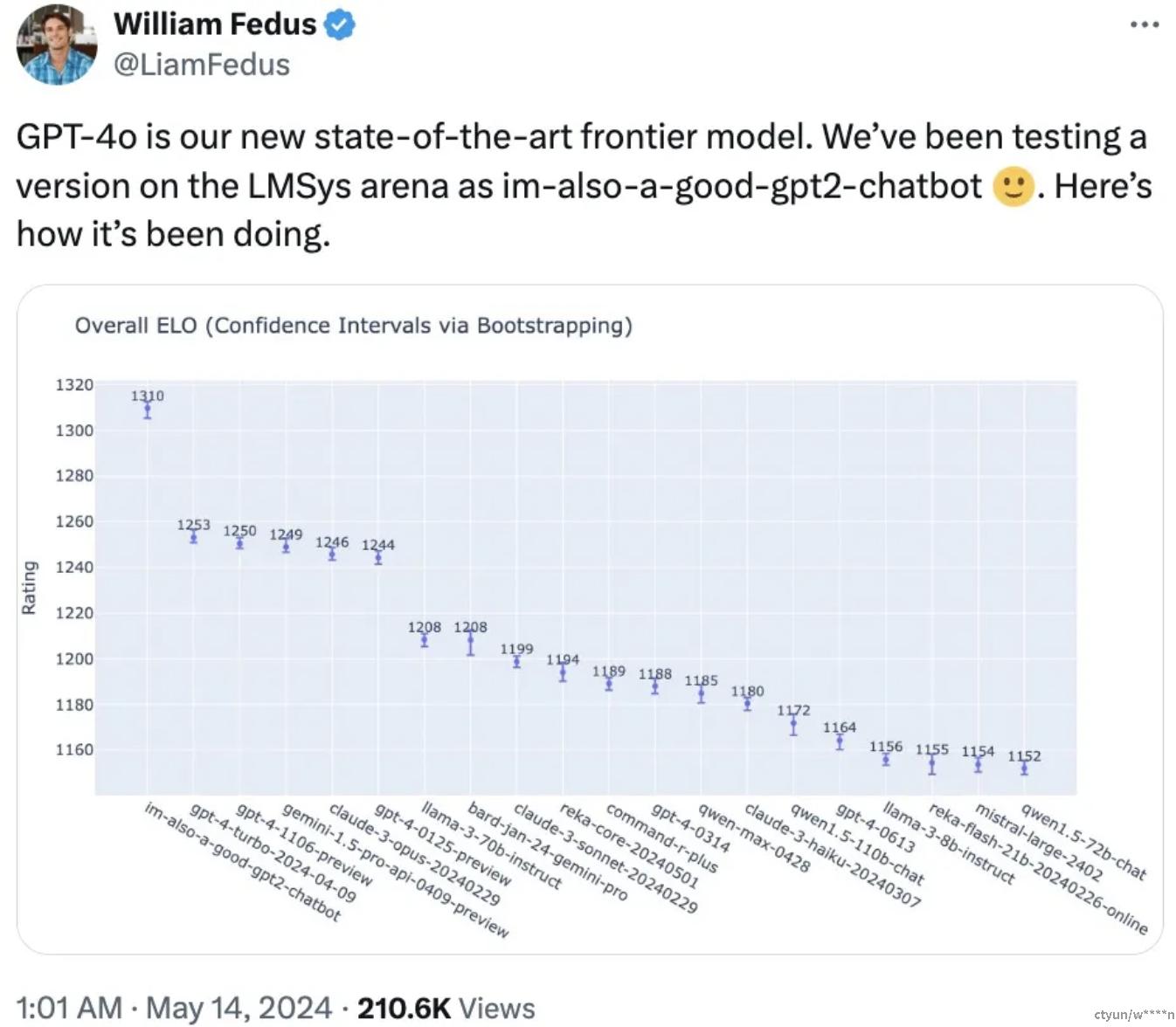
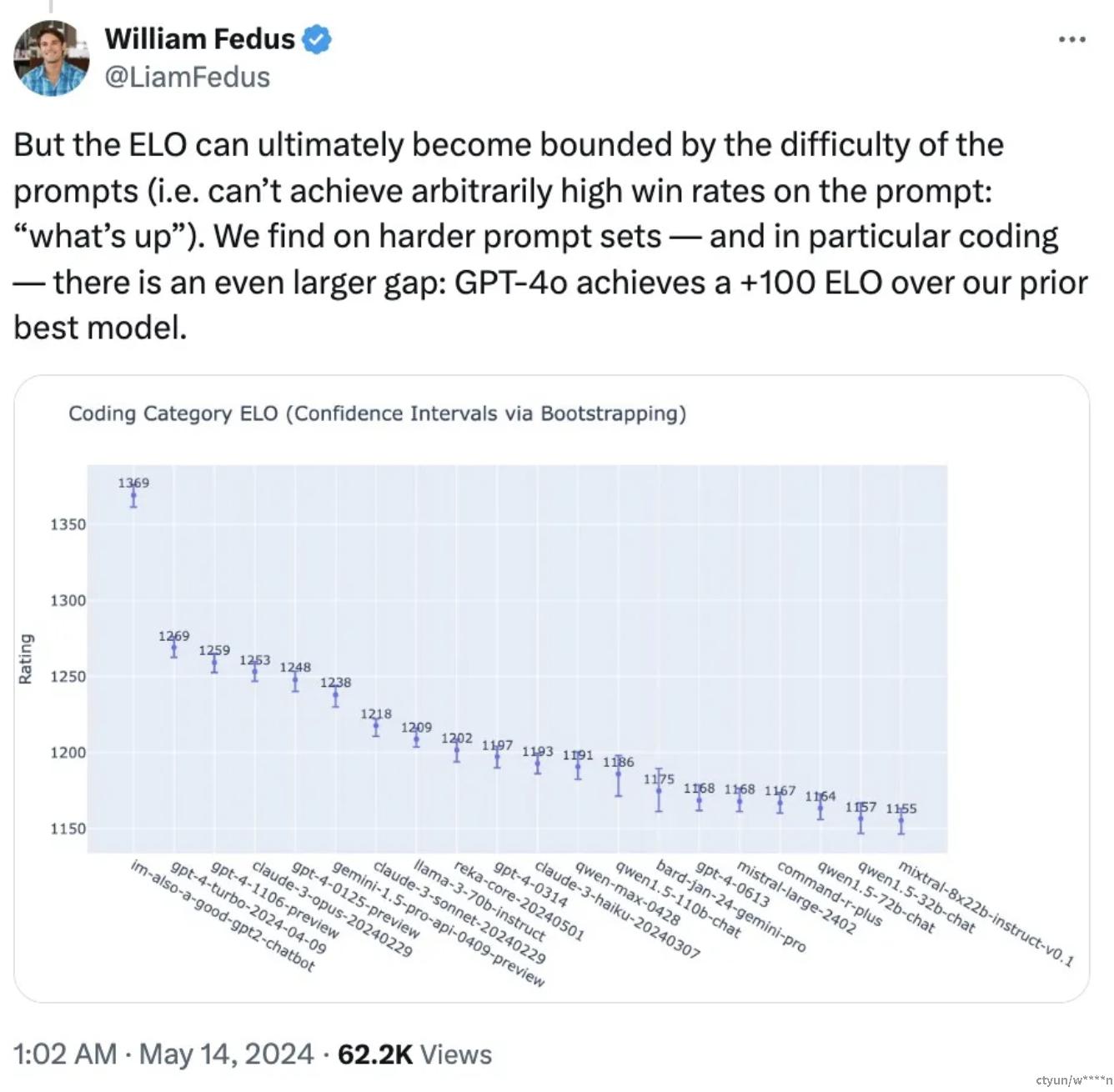
OpenAI 技术团队成员在 X 上表示,之前在 LMSYS Chatbot Arena 上引起广泛热议的神秘模型「im-also-a-good-gpt2-chatbot」就是 GPT-4o 的一个版本。在比较困难的 prompt 集上 —— 特别是编码方面:GPT-4o 相比于 OpenAI 之前的最佳模型,性能提升幅度尤其显著。具体来说,在多项基准测试中,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上实现了新高。
每周都有超过一亿人使用 ChatGPT,OpenAI 表示 GPT-4o 的文本和图像功能今天开始免费在 ChatGPT 中推出,并向 Plus 用户提供高达 5 倍的消息上限。使用 GPT-4o 时,ChatGPT 免费用户现在可以访问以下功能:体验 GPT-4 级别智能;用户可以从模型和网络获取响应。
此外,OpenAI 还将在未来几周内在 ChatGPT Plus 中推出新版本的语音模式 GPT-4o alpha,并通过 API 向一小部分值得信赖的合作伙伴推出对 GPT-4o 更多新的音频和视频功能。当然了,通过多次的模型测试和迭代,GPT-4o 在所有模态下都存在一些局限性。在这些不完美的地方,OpenAI 表示正努力改进 GPT-4o。
可以想到的是, GPT-4o 音频模式的开放肯定会带来各种新的风险。在安全性问题上,GPT-4o 通过过滤训练数据和通过训练后细化模型行为等技术,在跨模态设计中内置了安全性。OpenAI 还创建了新的安全系统,为语音输出提供防护。
当各家科技公司还在追赶大模型多模态能力,把总结文本、P 图等功能放进手机里的时候,遥遥领先的 OpenAI 直接开了大招,发布的产品连自家 CEO 奥特曼都惊叹:就像电影里一样。
5 月 14 日凌晨,OpenAI 在首次「春季新品发布会」上搬出了新一代旗舰生成模型 GPT-4o、桌面 App,并展示了一系列新能力。这一次,技术颠覆了产品形态,OpenAI 用行动给全世界的科技公司上了一课。
今天的主持人是 OpenAI 的首席技术官 Mira Murati,她表示,今天主要讲三件事:
-
第一,以后 OpenAI 做产品就是要免费优先,为的就是让更多的人能使用。
-
第二,因此 OpenAI 此次发布了桌面版本的程序和更新后的 UI,其使用起来更简单,也更自然。
-
第三,GPT-4 之后,新版本的大模型来了,名字叫 GPT-4o。GPT-4o 的特别之处在于它以极为自然的交互方式为每个人带来了 GPT-4 级别的智能,包括免费用户。
ChatGPT 的这次更新以后,大模型可以接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合输出 —— 这才是属于未来的交互方式。
最近,ChatGPT 不用注册也可以使用了,今天又增加了桌面程序,OpenAI 的目标就是让人们可以随时随地的无感使用它,让 ChatGPT 集成在你的工作流中。这 AI 现在就是生产力了。GPT-4o 是面向未来人机交互范式的全新大模型,具有文本、语音、图像三种模态的理解力,反应极快还带有感情,也很通人性。在现场,OpenAI 的工程师拿出一个 iPhone 演示了新模型的几种主要能力。最重要的是实时语音对话,Mark Chen 说:「我第一次来直播的发布会,有点紧张。」ChatGPT 说,要不你深呼吸一下。
ChatGPT 立即回答说,你这不行,喘得也太大了。
如果你之前用过 Siri 之类的语音助手,这里就可以看出明显的不同了。首先,你可以随时打断 AI 的话,不用等它说完就可以继续下一轮对话。其次,你不用等待,模型反应极快,比人类的回应还快。第三,模型能够充分理解人类的情感,自己也能表现出各种感情。
随后是视觉能力。另一个工程师在纸上现写的方程,让 ChatGPT 不是直接给答案,而是让它解释要一步步怎么做。看起来,它在教人做题方面很有潜力。
接下来尝试 GPT-4o 的代码能力。这有一些代码,打开电脑里桌面版的 ChatGPT 用语音和它交互,让它解释一下代码是用来做什么的,某个函数是在做什么,ChatGPT 都对答如流。输出代码的结果,是一个温度曲线图,让 ChatGPT 以一句话的方式回应所有有关此图的问题。最热的月份在几月,Y 轴是摄氏度还是华氏度,它都能回答得上来。
OpenAI 还回应了一些 X/Twitter 上网友们实时提出的问题。比如实时语音翻译,手机可以拿来当翻译机来回翻译西班牙语和英语。
首先介绍的是 GPT-4o,o 代表 Omnimodel(全能模型)。第一次,OpenAI 在一个模型中集成了所有模态,大幅提升了大模型的实用性。OpenAI CTO Muri Murati 表示,GPT-4o 提供了「GPT-4 水准」的智能,但在 GPT-4 的基础上改进了文本、视觉和音频方面的能力,将在未来几周内「迭代式」地在公司产品中推出。「GPT-4o 的理由横跨语音、文本和视觉,」Muri Murati 说道:「我们知道这些模型越来越复杂,但我们希望交互体验变得更自然、更简单,让你完全不用关注用户界面,而只关注与 GPT 的协作。」GPT-4o 在英语文本和代码上的性能与 GPT-4 Turbo 的性能相匹配,但在非英语文本上的性能显著提高,同时 API 的速度也更快,成本降低了 50%。与现有模型相比,GPT-4o 在视觉和音频理解方面尤其出色。它最快可以在 232 毫秒的时间内响应音频输入,平均响应时长 320 毫秒,与人类相似。在 GPT-4o 发布之前,体验过 ChatGPT 语音对话能力的用户能够感知到 ChatGPT 的平均延迟为 2.8 秒 (GPT-3.5) 和 5.4 秒 (GPT-4)。这种语音响应模式是由三个独立模型组成的 pipeline:一个简单模型将音频转录为文本,GPT-3.5 或 GPT-4 接收文本并输出文本,第三个简单模型将该文本转换回音频。但 OpenAI 发现这种方法意味着 GPT-4 会丢失大量信息,例如模型无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。而在 GPT-4o 上,OpenAI 跨文本、视觉和音频端到端地训练了一个新模型,这意味着所有输入和输出都由同一神经网络处理。
「从技术角度来看,OpenAI 已经找到了一种方法,可以将音频直接映射到音频作为一级模态,并将视频实时传输到 transformer。这些需要对 token 化和架构进行一些新的研究,但总体来说是一个数据和系统优化问题(大多数事情都是如此)。」英伟达科学家 Jim Fan 如此评论道。
GPT-4o 可以跨文本、音频和视频进行实时推理,这是向更自然的人机交互(甚至是人 - 机器 - 机器交互)迈出的重要一步。OpenAI 总裁 Greg Brockman 也在线「整活」,不仅让两个 GPT-4o 实时对话,还让它们即兴创作了一首歌曲,虽然旋律有点「感人」,但歌词涵盖房间的装饰风格、人物穿着特点以及期间发生的小插曲等。此外,GPT-4o 在理解和生成图像方面的能力比任何现有模型都要好得多,此前很多不可能的任务都变得「易如反掌」。比如,你可以让它帮忙把 OpenAI 的 logo 印到杯垫上:
OpenAI 技术团队成员在 X 上表示,之前在 LMSYS Chatbot Arena 上引起广泛热议的神秘模型「im-also-a-good-gpt2-chatbot」就是 GPT-4o 的一个版本。在比较困难的 prompt 集上 —— 特别是编码方面:GPT-4o 相比于 OpenAI 之前的最佳模型,性能提升幅度尤其显著。具体来说,在多项基准测试中,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上实现了新高。
每周都有超过一亿人使用 ChatGPT,OpenAI 表示 GPT-4o 的文本和图像功能今天开始免费在 ChatGPT 中推出,并向 Plus 用户提供高达 5 倍的消息上限。使用 GPT-4o 时,ChatGPT 免费用户现在可以访问以下功能:体验 GPT-4 级别智能;用户可以从模型和网络获取响应。
此外,OpenAI 还将在未来几周内在 ChatGPT Plus 中推出新版本的语音模式 GPT-4o alpha,并通过 API 向一小部分值得信赖的合作伙伴推出对 GPT-4o 更多新的音频和视频功能。当然了,通过多次的模型测试和迭代,GPT-4o 在所有模态下都存在一些局限性。在这些不完美的地方,OpenAI 表示正努力改进 GPT-4o。
可以想到的是, GPT-4o 音频模式的开放肯定会带来各种新的风险。在安全性问题上,GPT-4o 通过过滤训练数据和通过训练后细化模型行为等技术,在跨模态设计中内置了安全性。OpenAI 还创建了新的安全系统,为语音输出提供防护。