


一、赛题回顾
1. 赛题内容
本赛道旨在通过多任务联合训练来提升模型的泛化能力,同时解决多任务、多数据之间冲突的问题。根据给出的分类、检测、分割三任务的数据集,使用统一大模型进行AllInOne联合训练,使得单一模型能够具备分类、检测、分割的能力。
2.评价指标
分类任务(Classification task):Top-1 accuracy
检测任务(Detection task):mAP50
分割任务(Segmentation task):mIoU
3.难点分析
3.1 多任务特征冲突
对于多个不同任务(例如分割、分类、检测),其所需要的特征是不同的,有的需要浅层特征,有的关注深层特征,有的关注局部,有的关注全局。
3.2 Loss数量级不一致
对于多任务学习,每个任务都有专属Loss,若各任务数量级不一致,会使得大数量级的任务占据主导,小数量级任务不易收敛。
3.3 各任务收敛速度不一致
不同任务收敛速度不一致,例如分类任务简单,更易收敛,检测任务则需要更多训练轮数,可能导致分类已过拟合,检测仍未收敛。
3.4 多任务训练显存占用大
多任务Head和数据需要保存更多的梯度以及其它优化器变量,显存占用成倍增长,限制Batch size大小,影响训练速度和精度。
二、解题思路
1. 数据分析
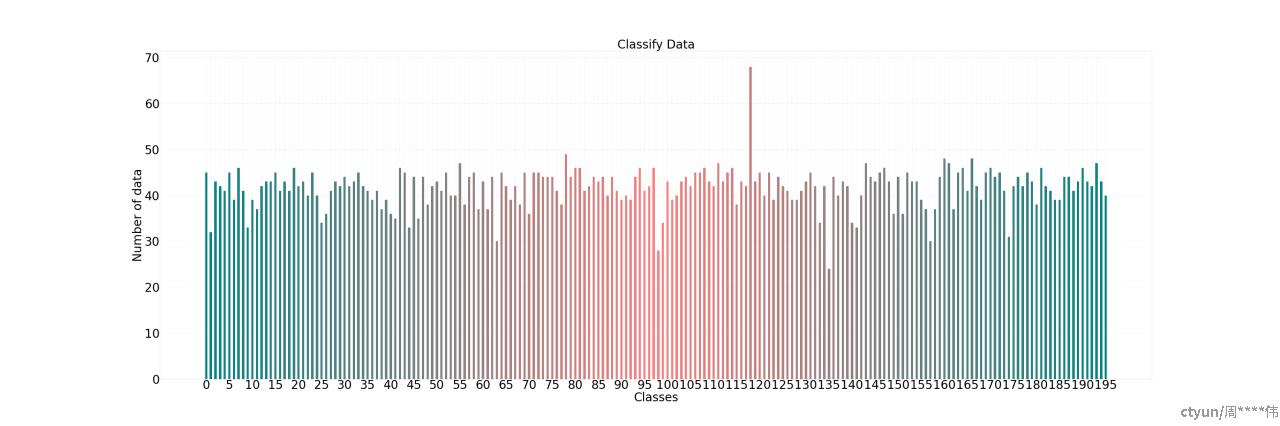
分类数据类别分布,不存在长尾问题
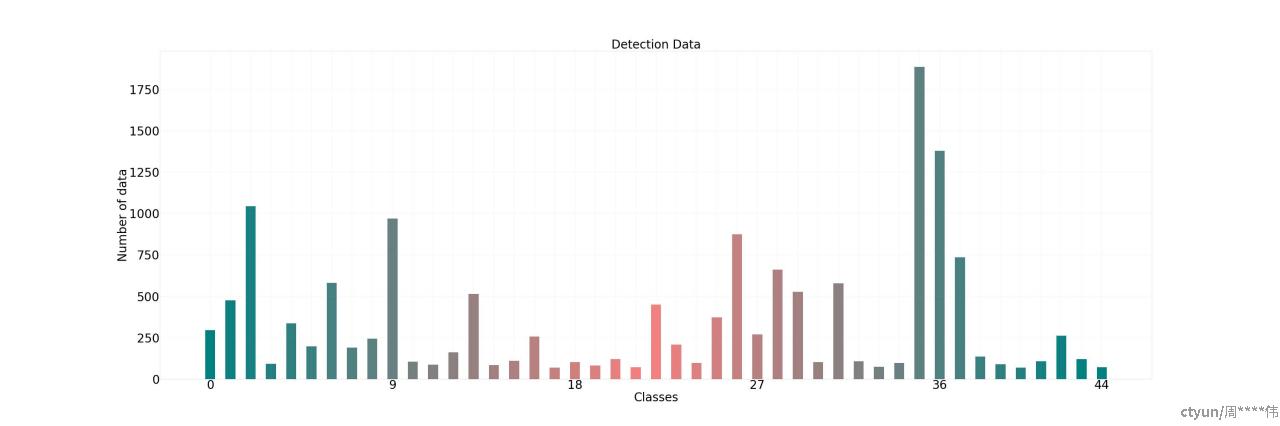
目标检测数据各类别分布,存在一些小类别
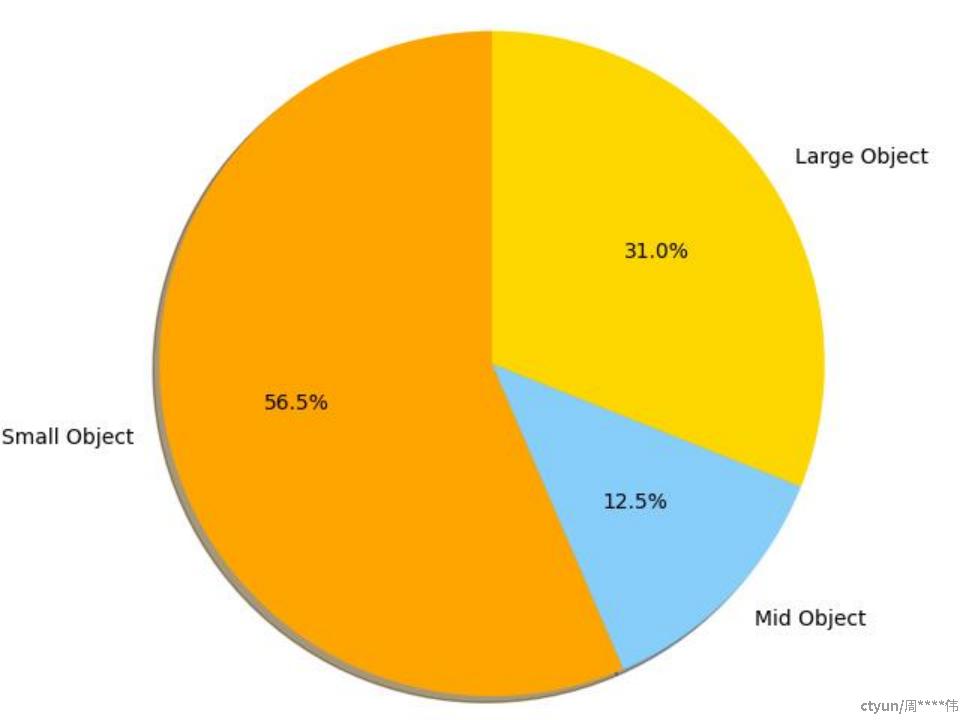
分割数据不同大小目标分布,存在较多小目标(32x32以下)
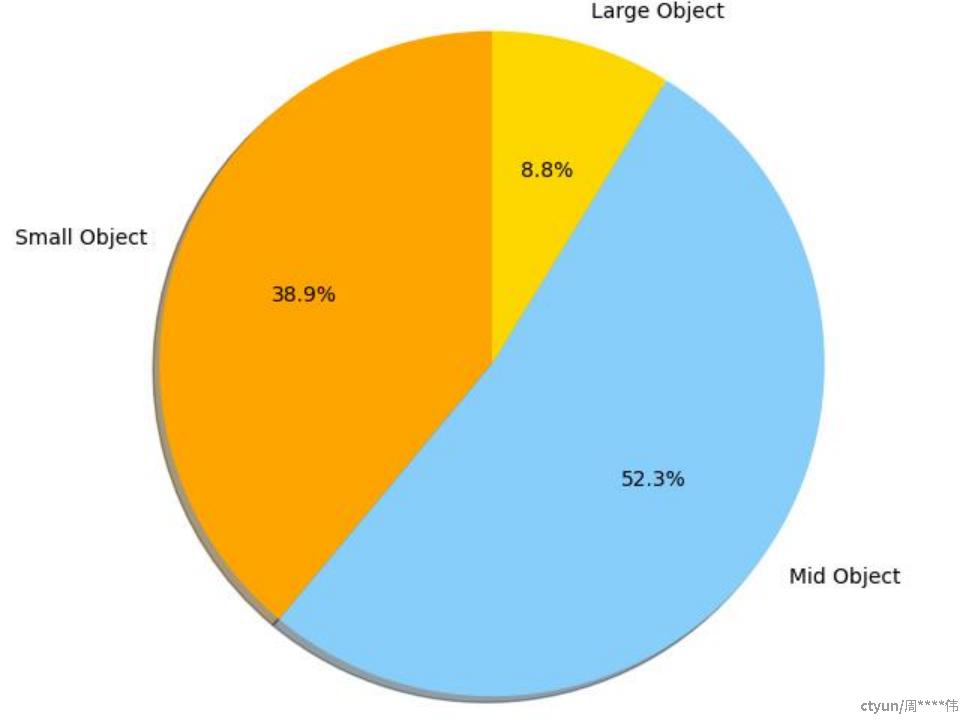
目标检测数据不同大小目标分布,存在较多小目标(32x32以下)
2.模型设计
2.1 Backbone选择
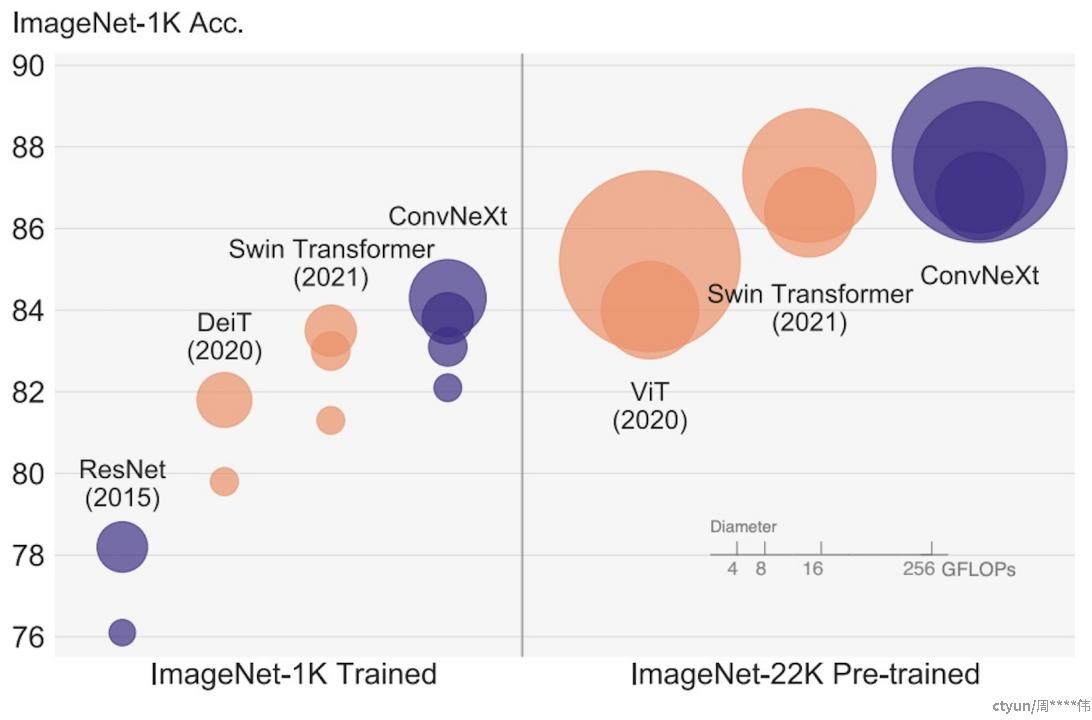
同颜色表示同家族模型,圆圈越大表示FLOPS越高,计算量越大; 同等计算量下,ConvNeXt精度优于Swin和ViT; 在比赛数据集上,相同输入大小和数据增强下,ConvNeXt的精度和显存占用优于Swin和ViT。
2.2 分割head设计
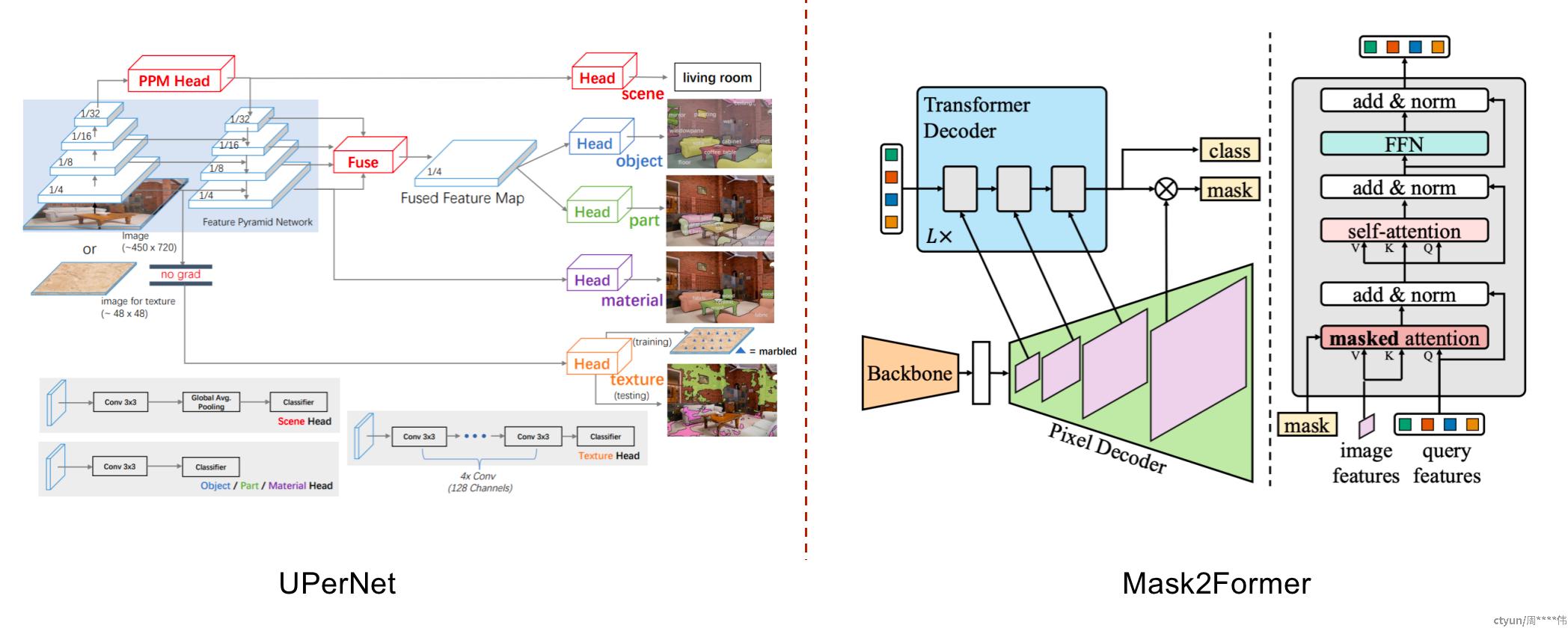
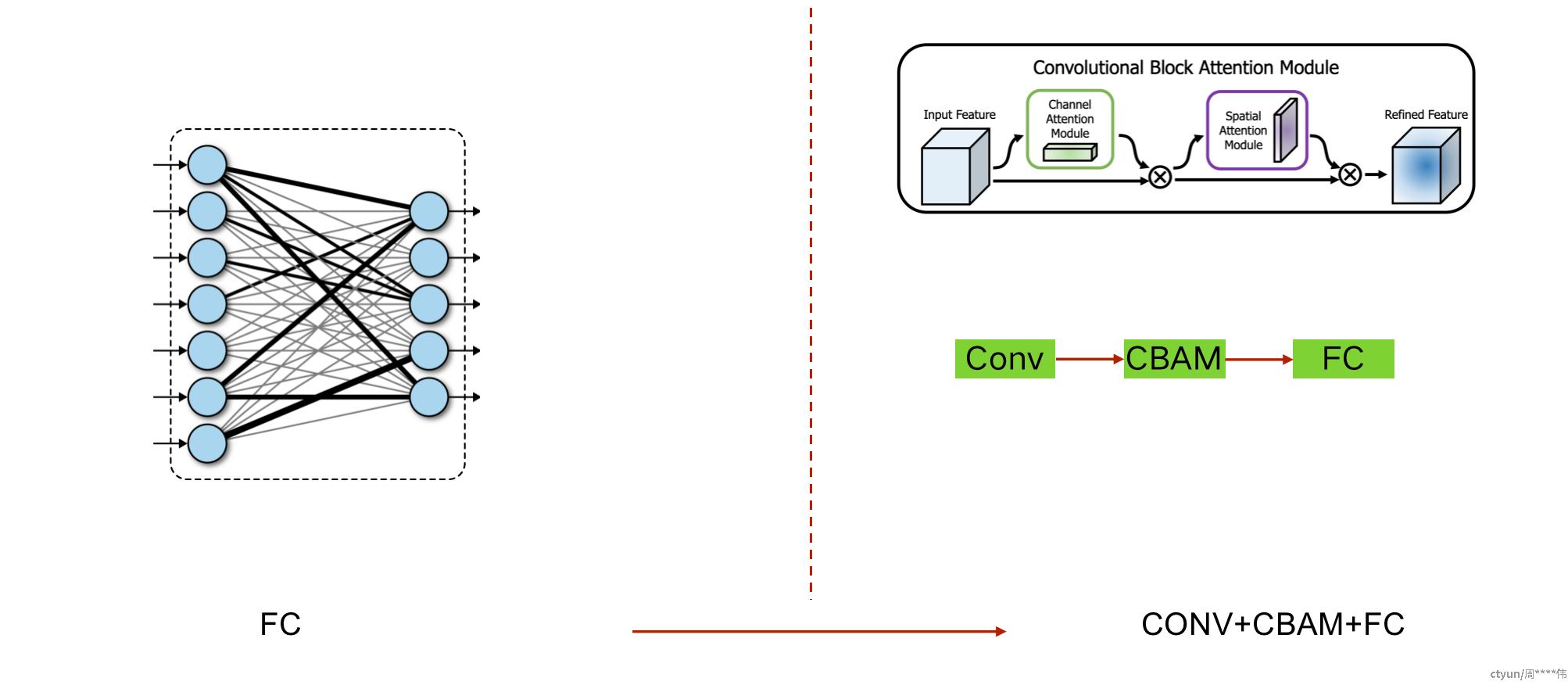
2.3 分类head设计
2.4 检测head设计
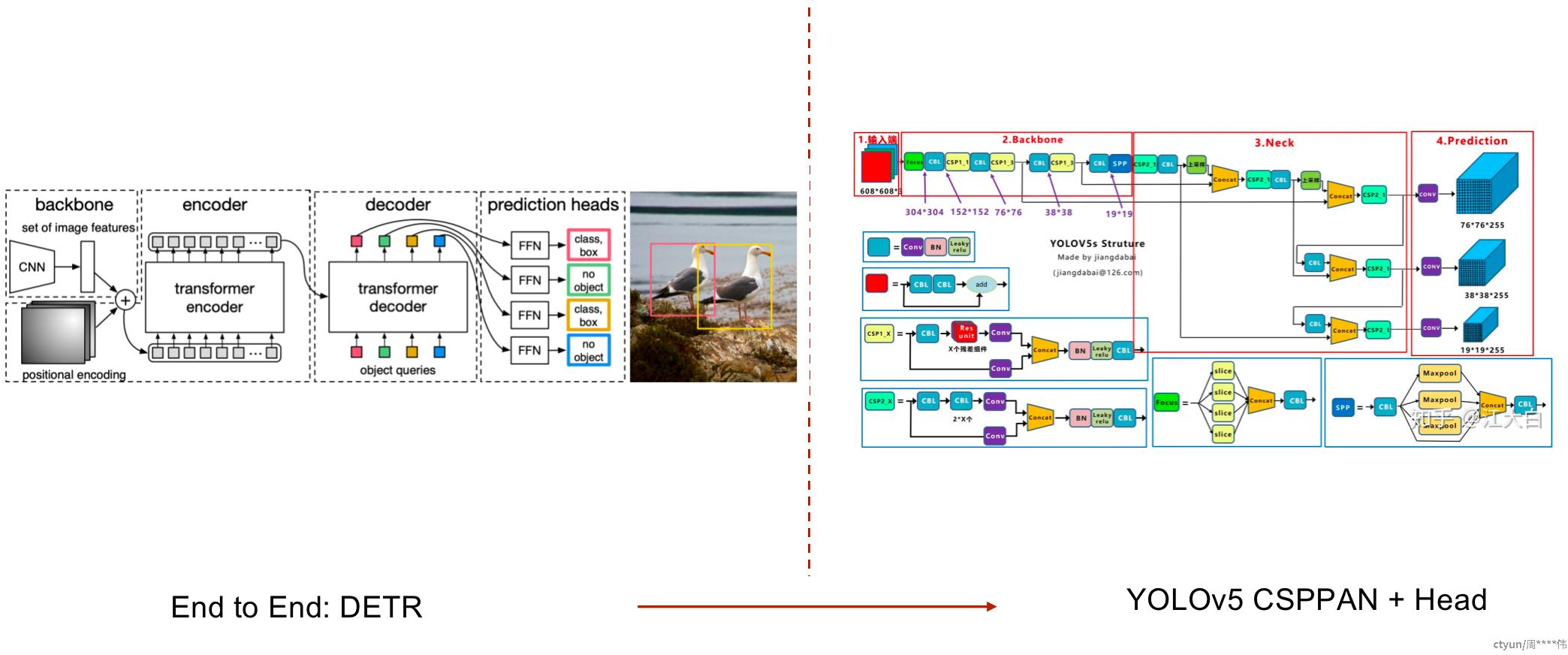
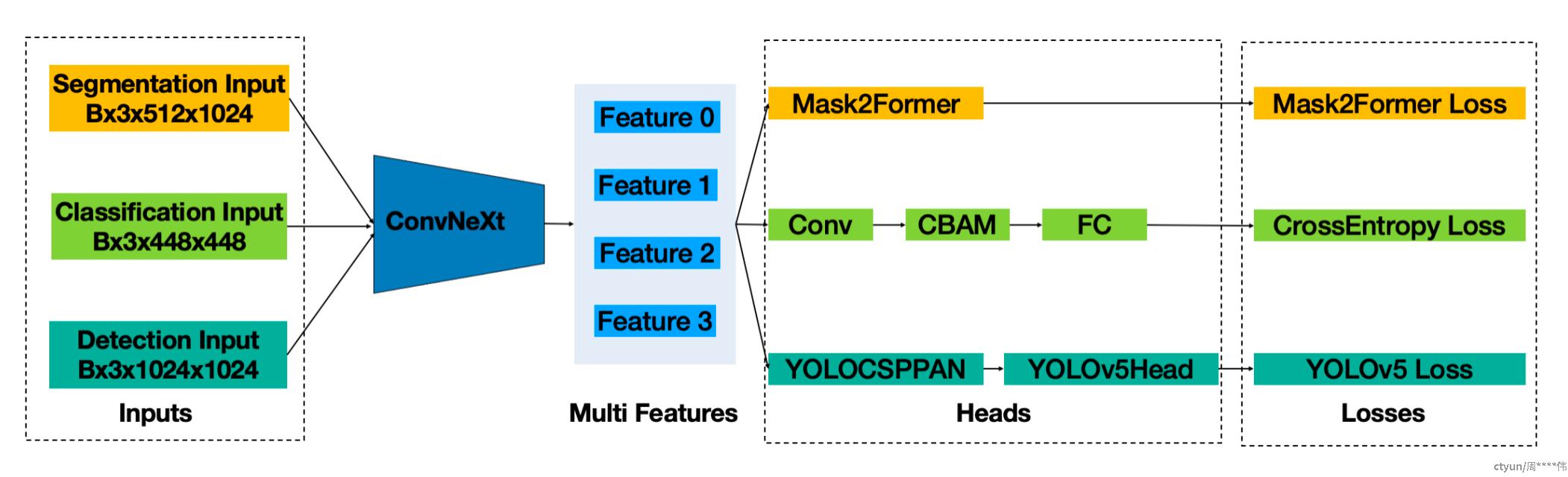
本队伍最终采用的网络结构,通过Backbone输出多尺度特征, 各任务通过注意力机制或者特征金字塔按需使用,减轻特征冲突; 针对Loss数量级不一致,分别调整任务Loss内部权重,保证Loss数量级差异倍数不超过10。
3. 训练方案
先训练最难收敛或者最重要的任务,比如Task2, 固定Backbone和Task2 Head的参数,再训练其他任务,只更新对应的Task Head参数。 交替训练方法,即每次更新参数时,依次使用Task1、Task2、Task3的数据forward,再更新参数。 先交替训练,固定Backbone参数,然后分别对每个Task Head微调.
|
训练方案 |
分割 |
分类 |
检测 |
总分 |
|
1 |
0.66447 |
0.9321 |
0.95564 |
0.8507 |
|
2 |
0.70532 |
0.95436 |
0.94549 |
*0.8684 |
|
3 |
0.65625 |
0.95374 |
0.94094 |
0.8503 |
4. 训练技巧

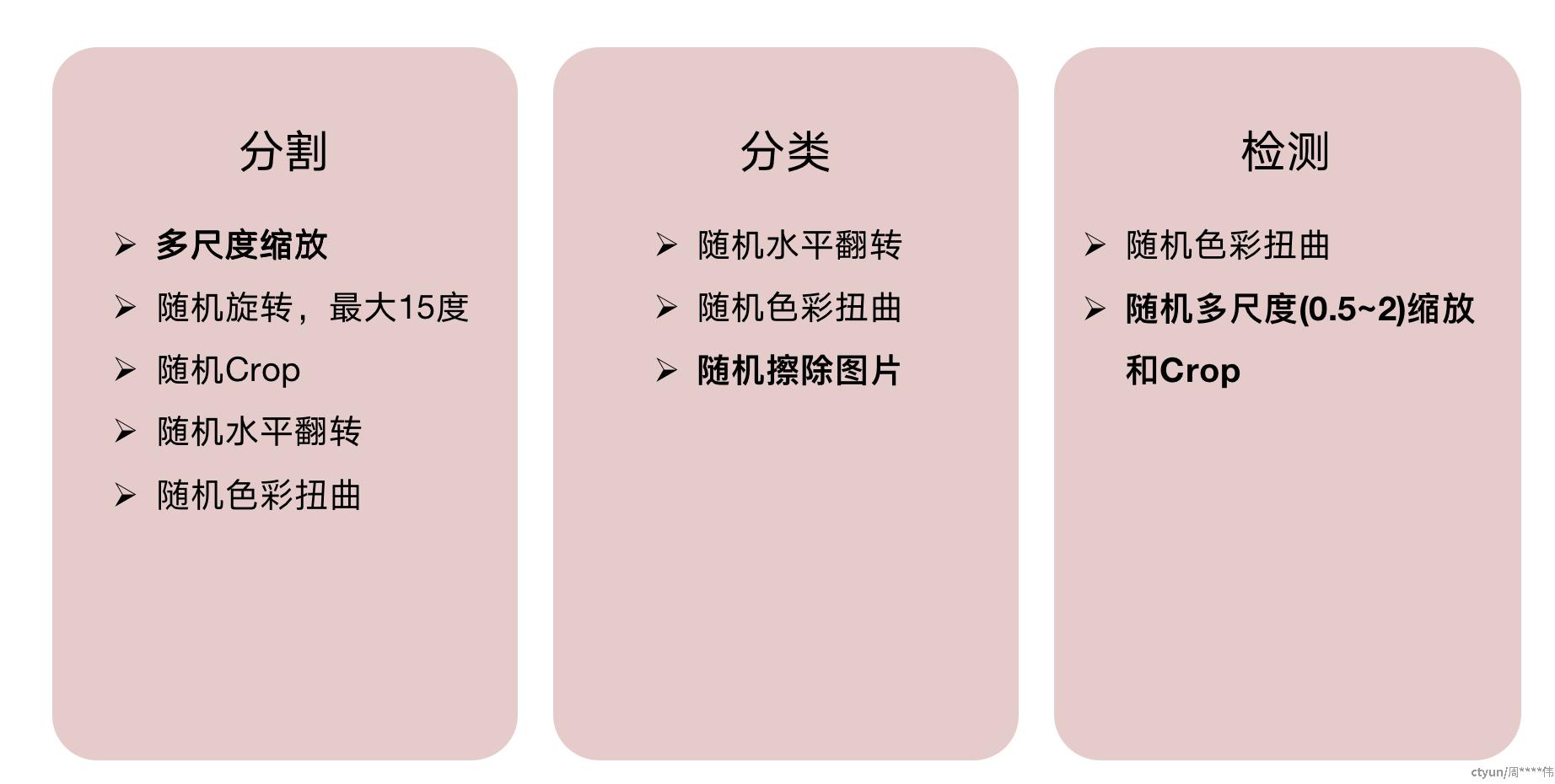
5. 数据增强
6. Test Time Adapation

7. 思考总结
7.1 模型选型
Transformer能捕捉全局信息,逐渐在CV领域大放异彩,有一统江湖的趋势。
CNN具有平移不变性和局部相关性,处理2D图像出色,算子成熟,速度快易部署。
Transformer在大数据集中上限高于CNN。
CNN在小数据集中更容易训练,有非常多成熟的网络结构。
Transformer 还是 CNN?根据具体场景灵活选用网络结构,Transformer和CNN可以互相借鉴优秀的网络结构和训练方法,可以两者结合起来使用。
7.2 网络结构设计
Mask2Former在Transformer结构上达到了sota,其分割head优秀,同样值得CNN借鉴。 YOLOv5网络结构在业界大量使用,优秀的特征金字塔和损失设计可以移植到优秀的CNN backbone上。 单 FC层无法很好学习分类特征,使用CBAM注意力增强特征注意力。 使用了ConvNext的多尺度特征,来捕捉不同层级的语义。多任务Head按需索取,进一步提升总体精度。
灵活运用各领域优秀的结构,站在巨人的肩膀上,合理选用优秀的网络结构设计!
7.3 多任务训练心得
在有限的显存下,通过梯度累积实现更大的batch size 平衡各任务的Loss, 可以获得更加均衡的结果,避免参数朝向单一任务最优去更新。 根据各任务的收敛速度调整任务的epoch数以达到同时收敛。 选择合适的数据增强方法,减少过拟合,且增加难例和小目标的精度。
多分析训练时各任务的Loss、收敛速度、验证精度以及显存占用等,在有限的资源下实现多任务的最佳平衡。
