


背景介绍
目标检测是计算机视觉领域的一项重要任务,其目标是在给定的图像或视频中找出并识别感兴趣的物体或目标。它广泛应用于自动驾驶、安防监控、机器人导航等领域。早期的目标检测方法主要基于手工设计的特征和机器学习算法,如Haar特征和AdaBoost分类器。随着深度学习技术的兴起,基于卷积神经网络的目标检测算法如R-CNN、Fast R-CNN和Faster R-CNN等相继问世,大幅提高了检测的准确率和速度。其中尤其以YOLO为代表的单阶段目标检测方法取得了重要进展,为实时应用提供了有力支持,并在近些年得到了广泛的工业应用。
YOLO(You Only Look Once)是由Redmon等人在2016年提出的一种单阶段目标检测算法。它将目标检测问题转化为一个单一的回归问题,直接从输入图像中预测出目标的边界框和类别。YOLO的核心思想是将整个图像划分为多个网格单元,每个网格单元负责预测其内部的目标。这种端到端的单阶段设计大大提高了检测速度,可以达到实时性能。
在YOLO发布之前,主流的目标检测方法通常采用两阶段的设计,如Faster R-CNN。这种方法先生成区域建议,然后对这些区域进行分类和回归。虽然准确率较高,但计算复杂度较大,难以满足实时应用的需求。
YOLO的提出开创了单阶段目标检测的新纪元。凭借其出色的速度和可以接受的准确率,YOLO在众多应用场景中取得了广泛应用,如自动驾驶、视频监控等。随后,研究人员又提出了YOLOv2、YOLOv3、YOLOv4等更加优化的版本,不断提高检测性能。
然而,尽管YOLO系列的传统检测方法取得了巨大成功,但它们仍存在一些局限性:
- 泛化性差:局限于特定的数据集和任务,难以推广到其他场景。这是由于它们采用的是单一的网络结构和训练策略,很难兼顾不同类型的目标。
- 准确率有限: 可以实现实时检测,但其准确率仍然低于两阶段的方法,尤其是对于小目标和密集目标场景。这是由于它们直接回归目标的边界框,难以捕捉细节特征。
- 定位精度不高:定位精度往往不如Faster R-CNN等两阶段方法,因为它只有单一的网格预测,无法充分利用多尺度特征。
- 难以迁移学习: 通常需要从头训练,很难利用已有模型进行迁移学习,这限制了它们在资源受限场景下的应用。
因此,近些年来,开集目标检测(Open-Set Object Detection)是计算机视觉领域近年来兴起的一个重要研究方向。它旨在解决传统目标检测方法面临的一个关键问题:如何在实际应用中有效地识别和处理未知的目标类别。在现实世界中,事先很难穷尽所有可能出现的目标类别,这给基于已知类别的传统目标检测方法带来了严重局限性。开集目标检测提出了一个更为广泛的问题:除了准确检测已知类别,还要能够发现并区分未知类别,甚至对其进行进一步识别。这种开放世界的目标检测能力,与人类的视觉认知过程更为贴近。
早期的开集目标检测研究主要借鉴了异常检测和零样本学习的思想,利用异常样本训练来区分未知类别。随后,基于元学习和生成对抗网络的方法也相继提出,大幅提升了开集检测的性能。此外,开放集分类、增量学习等相关技术也为开集目标检测提供了有益借鉴。
开集目标检测相对于传统目标检测方法具有以下几个主要优点:
- 更强的泛化能力:传统目标检测方法通常局限于事先定义的类别,难以应对新出现的未知类别目标。而开集目标检测能够在保留已知类别检测性能的同时,识别出图像中的未知目标,从而更好地适应实际应用场景中不断变化的环境。
- 更贴近人类认知:人类在日常生活中很容易识别出从未见过的新事物,并区分已知和未知目标。开集目标检测旨在模拟这种人类的开放世界认知能力,更好地描述现实世界的复杂性。
- 更高的实用性:在许多应用场景中,事先难以穷尽所有可能出现的目标类别。开集目标检测可以动态地发现和适应新的目标类别,大大提高了系统的实用性和可扩展性。
- 更高的安全性:在安全关键型应用中,如自动驾驶和工业机器人,能够检测出未知的危险目标至关重要。开集目标检测可以及时发现并识别这些潜在威胁,提高系统的安全性。
- 更有利于终身学习:开集目标检测与人类的终身学习能力不谋而合。它可以通过不断积累知识,持续改进检测模型,实现自主学习和进化,这对于构建真正智能的视觉系统至关重要。
开集目标检测方法简介
在前大模型时代,开集目标检测open-set object detection (OSOD)也有了相关的一些发展。但是由于一些固有的缺陷,导致没有较大的发展。原因如下:
- 知识受限:传统方法主要依赖于在已知类别上的有限训练数据,知识基础相对有限。而基于大模型的方法利用了预训练的大规模跨领域视觉-语言模型,积累了海量的视觉和语义知识,知识基础更加丰富。
- 建模方法:一般传统方法通常将已知和未知类别的检测建模为一个二分类问题,或利用异常检测来识别未知目标,而基于大模型的方法则更多地采用元学习、跨模态融合等方式,以更加灵活和高效的方式处理已知和未知类别;
- 泛化性:传统方法在面对未知类别时,泛化能力较弱,容易出现性能下降,而基于大模型的方法能够更好地将预训练的知识迁移到新的未知类别,泛化能力更强;
- 效率和可扩展性:传统方法需要重新训练模型才能应对新的未知类别,效率较低;基于大模型的方法可以通过快速微调等方式适应新的未知类别,具有更好的效率和可扩展性;
- 应用广度: 传统方法主要局限于特定的目标检测任务,基于大模型的方法可以被广泛应用于各种视觉感知任务,具有更强的通用性。
基于大模型的开集目标检测
本节主要介绍以大模型为基础的开集目标检测方法。
grouding dino
- 该篇论文发表于2023年,由IDEA发表,是一种基于大模型的开集目标检测方法。业界宣称为"在很多复杂场景,绝对吊打YOLO系列;因为它能识别所有目标,甚至能够区分紫色葡萄和绿色葡萄,区分大腿、手指和人。资源消耗也不大,CPU推理3秒一张图片,GPU占用4G,推理一张图片0.13秒。"。 其优点可以具体的列举如下:
- Grounding DINO采用预训练的DINO和CLIP模型作为视觉-语言基础,从海量的图文数据中学习到了丰富的视觉和语义表征。这为后续的开集目标检测任务提供了强大的知识基础和特征表示。
- Grounding DINO利用了元学习的思想,通过少量的样本就能快速适应新的未知目标类别。这种高效的微调机制大大提高了模型在开集场景下的泛化能力。
- Grounding DINO结合了视觉和语言两个模态的信息,充分利用了跨模态表征的能力。这种跨模态融合方式增强了已知目标的检测性能,同时也提高了对未知目标的识别能力。
- Grounding DINO采用了动态校准的方式,实时调节已知和未知目标的置信度阈值。这种自适应校准机制提高了模型在开集场景下的鲁棒性和平衡性。
- Grounding DINO通过多次反馈和微调,不断改进模型在未知类别上的检测性能。这种迭代优化策略使得模型的性能能够持续提升,更好地适应开集环境。
- 该方法通过在多个阶段执行视觉语言模态融合来扩展封闭集检测器DINO,包括特征增强器、语言指导的查询选择模块和跨模态解码器。 这种深度融合策略有效改进了开放集物体检测。将开放集物体检测的评估扩展到REC数据集。 它有助于评估模型对自由文本输入的性能。在COCO、LVIS、ODinW和RefCOCO/+/g数据集上的实验表明,Grounding DINO在开放集物体检测任务上的有效性。
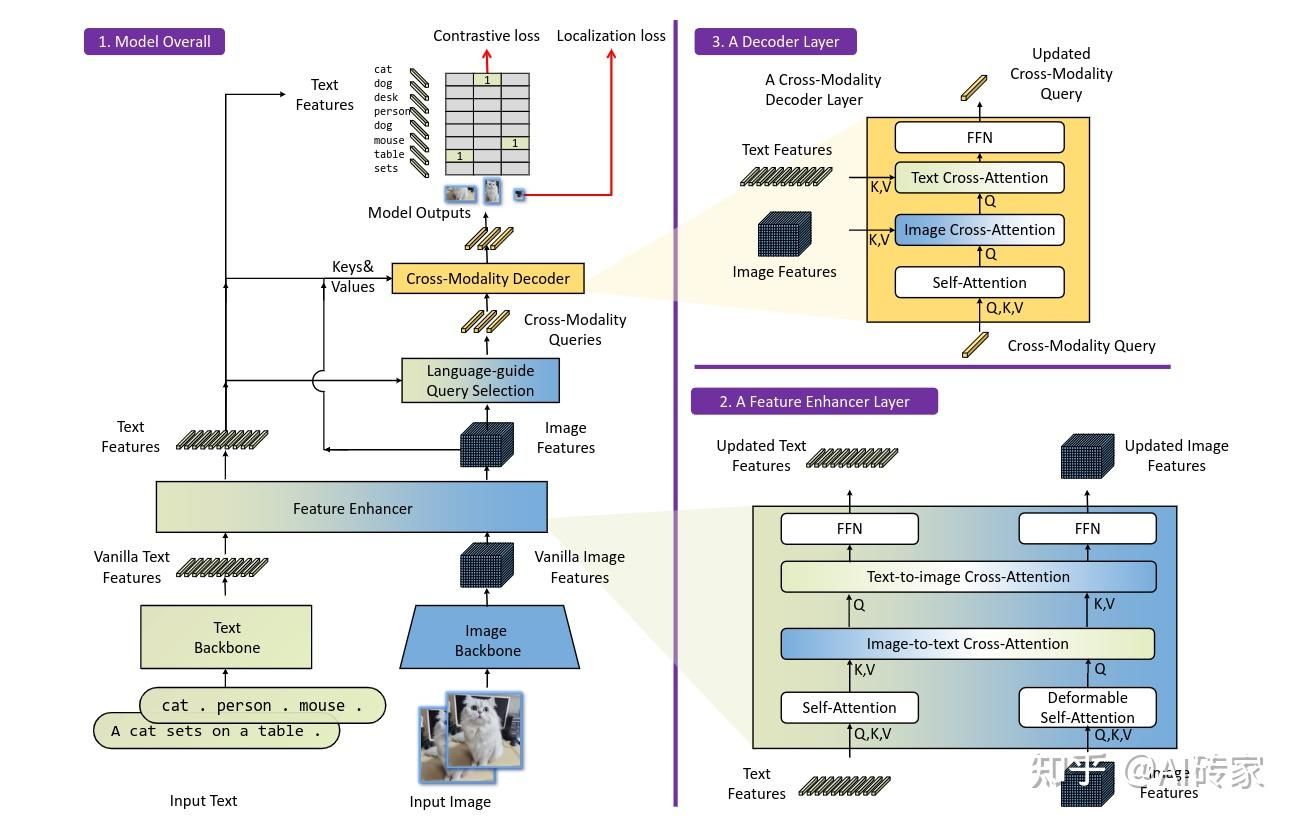
- 特征提取和增强:作者采用了类似于Swin Transformer 的图像主干网络提取多尺度图像特征,并采用类似于BERT的文本主干网络来提取文本特征。沿用DETR的检测器来从不同的模块中提取多尺度特征。在提取原始图像和文本特征后,我们将它们输入到特征增强器中进行跨模态特征融合。
- 语言指导的查询:设计了一个语言指导的查询选择模块,用于选择与输入文本更相关的特征作为解码器查询,根据所选索引提取特征来初始化查询,将位置部分形式化为动态锚框,它们使用编码器输出进行初始化。另一部分内容查询在训练期间被设置为可学习的。
- 跨模态解码器: 设计了一个跨模态解码器来组合图像和文本模态特征,每个跨模态查询被馈送到自注意力层、图像交叉注意力层以组合图像特征、文本交叉注意力层以组合文本特征和每个跨模态解码器层中的FFN层。与DINO解码器层相比,每个解码器层都有一个额外的文本交叉注意力层,因为我们需要向查询中注入文本信息以实现更好的模态对齐。
- 子句级文本特征:引入注意力屏蔽来屏蔽不相关类别名称之间的注意力,称为“子句”级表示。它在保持词级特征以进行细粒度理解的同时消除了不同类别名称之间的影响。
- 损失函数:沿用使用L1损失和GIOU损失进行边界框回归,边界框回归和分类成本首先用于在预测和真值之间进行双分匹配,在相同的损失组件下计算真值和匹配预测之间的最终损失。
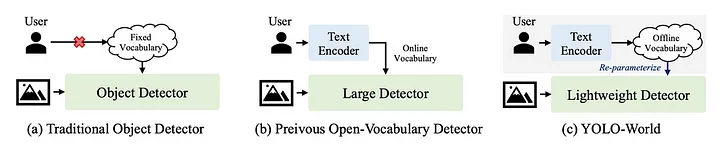
yolo world
- 2024年1月31日,由腾讯人工智能实验室发表了该篇工作,能够实时环境中进行开放词汇表识别对象,并可以进行zero-shot来进行目标检测,极大拓展了基于大模型的开集检测方法的边缘侧部署的想象空间。该篇工作填补了现有工作的空白,与领域内常见的基于Transformer的较慢模型不同,YOLO-World采用了更快的基于CNN的架构,源自YOLO框架。号称相对于上篇工作在精度相当的情况下可达到20倍的加速,从而引发了热烈的讨论。
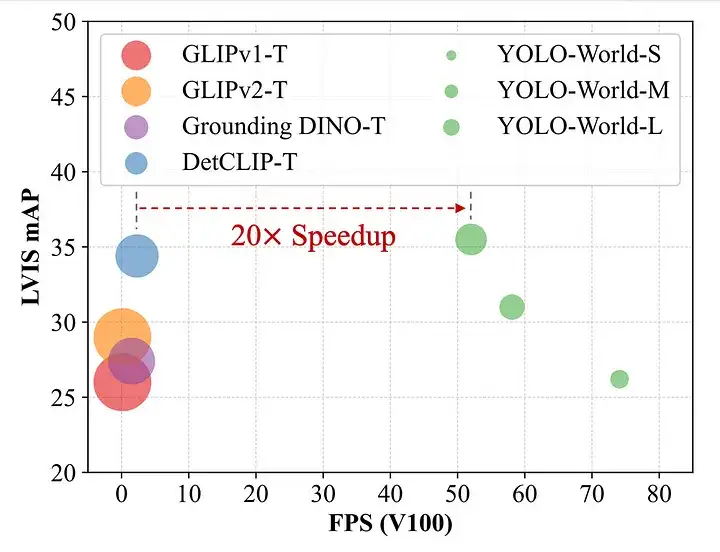
- YOLO-World代表了开放词汇目标检测技术的重大进步,尤其是其高性能,具备了高效的部署性能。在训练中,利用大量的图像-文本对和基础图像进行训练,使其能够解释提示的上下文,以进行准确的检测,而无需进行特定的类别训练。
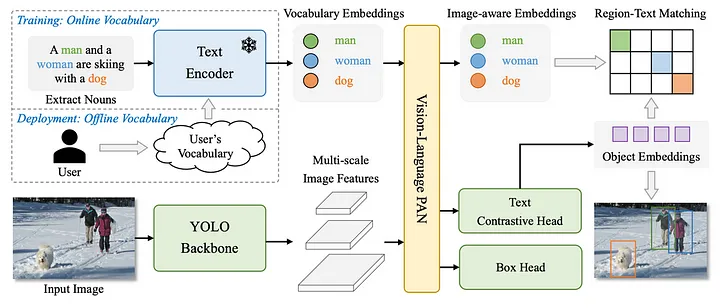
- 该篇工作的骨干网络采用了YOLO的现有结构,语言模型采用了CLIP模型。使用文本和图像特征中的特征通过区域到文本对比学习连接到 RepVL-PAN。YOLO检测将图像-文本数据集成到区域-文本对中。与传统的YOLO检测器相比,YOLO-World是一个开放的词汇检测器,它使用文本作为输入,而文本编码器首先将输入文本编码为嵌入。然后,图像编码器将输入图像编码为多层图像特征,RepVL-PAN对图像和文本特征进行多层跨模态融合。最后,YOLO-World 预测与输入文本中出现的类别或名词匹配的校准边界框和对象嵌入。
未来发展
基于大模型的开集目标检测方法,随着大模型,尤其是多模态大模型的飞速发展,也迎来了不可想象的应用空间。其未来的发展方向将可能包含以下而不限制。
- 跨模态融合能力的进一步提升:当前的方法多利用视觉和语言两个模态的信息进行开集识别,未来可以探索更丰富的多模态融合方式,如引入声音、视频等更多信息源。这种跨模态融合能力的增强可以进一步提升模型在复杂场景下的感知和理解能力。
- 小样本学习和迁移学习的深入应用:开集目标检测需要快速适应新的目标类别,小样本学习和迁移学习技术将在此发挥重要作用。未来可以研究如何更好地利用少量样本高效地微调和迁移大模型,以实现更快速的开集泛化。
- 自监督学习和无监督学习的融合:目前大模型多依赖有监督的预训练,未来可以探索如何将自监督学习和无监督学习方法融入到开集检测中。这种无监督的特征学习方式可以进一步增强模型的泛化能力和鲁棒性。
- 推理解释能力的提升: 开集目标检测需要模型能够解释其预测决策,未来可以关注如何增强大模型的推理解释能力。例如通过可视化分析、因果推理等方式,让模型对自身行为做出更加合理的解释,提高用户的信任度。
- 与元学习、强化学习等前沿技术的结合: 元学习和强化学习等前沿技术可以进一步增强大模型在开集场景下的学习和适应能力。未来可以探索如何将这些技术与基于大模型的开集目标检测方法相结合,实现更智能化的感知系统。
总的来说,基于大模型的开集目标检测方法还有很大的发展空间,未来可以从跨模态融合、小样本学习、自监督学习、推理解释能力、前沿技术结合等多个方向进行深入研究和创新,不断推动这一领域的发展。
