


什么是向量检索
现实世界中的图片、语言、语音、视频、社交网络等均可以通过相关Embedding模型转换为低维空间中的向量,这项技术称为Embedding技术。在诸如信息检索、语义检索、推荐、以文搜图、蛋白质结构检索等应用中,向量检索是其中不可或缺的一项技术。
向量检索,顾名思义,是针对向量数据的检索技术。经典的检索算法KNN算法(K-Nearest Neighbor),即从给定的向量数据集中,按特定的度量方式,检索出与查询向量最相似的K个候选向量的算法。KNN算法为精确检索算法,需要扫描全量向量数据集进行暴搜,其时间复杂度随数据集规模和维度增大而急剧恶化。ANN算法(Approximate Nearest Neighbor)是一类近似K近邻检索算法,其通过特定的索引结构,加速近邻检索过程,保障近邻检索质量。近似检索技术可细分为两大类技术:索引技术与量化压缩技术。经典的索引算法如树索引算法、局部敏感哈希算法、倒排索引算法以及图索引算法。量化压缩算法如PQ、OPQ、SQ、LVQ、PCA降维等。两类技术可交叉组合,形成组合技。
随着向量数据库、RAG等应用的兴起,近似向量检索技术再次成为热点,本文将聚焦于近似向量检索中的图检索技术,该技术在面对海量高维向量检索场景时表现出了极强的竞争力。
本文将面向不同的计算/存储硬件,探索不同形式的图检索技术:全内存图检索技术、混合存储图检索技术、硬件加速的图检索技术等。
全内存图检索技术
HNSW(2016)
HNSW(Hierarchical, Navigable Small World graphs,分层可导航小世界图)及其变种是目前工业界影响力最大的近似最近邻检索算法之一,具有非常优秀的搜索速度和出色的召回率。在Faiss(开源)、nmslib(开源),proxima(阿里)等均有实现。
HNSW基于NSW(可导航小世界图)构建分层图,小世界图具有以下特性:
- 短路径长度:尽管网络可能很大,但大部分节点节点两两之间的路径长度通常都很短。
- 高聚集系数:网络中的节点会存在较多的社区结构,即相似的节点会聚集在一起。
- 较好的连通性:网络中的节点不仅与自己相似的邻居节点相连,也会通过多跳关系与陌生节点相连。
以上三大特性可很好的保障近似最近邻检索的准确率与召回率。
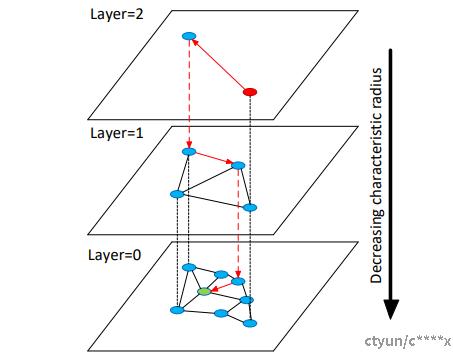
其次,HNSW通过构建分层结构,在检索过程中快速从全局收敛到局部,加速检索。HNSW支持增量构建,但不支持动态删除。
技术点
-
分层导航技术
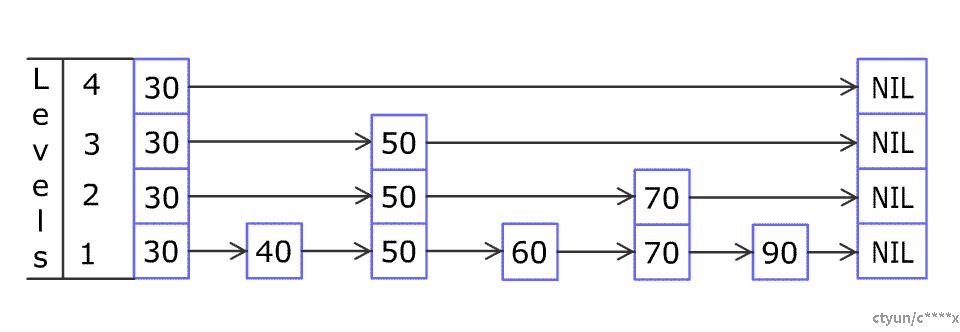
HNSW利用跳表的思想构建分层结构,概率跳表最早由William Pugh于1990年提出,跳表可以通过多个链表层来构建,越往上层可跳过多个中间节点(即两个上层节点间的距离一般更远),越往下层跳过节点越少(下层节点间的距离一般更近),底层只能逐个节点遍历。在HNSW构建过程中,会基于顶点数量确定分层层数,同时每一层的插入概率有概率函数给出。从最顶层开始,若节点需要被插入,则将该节点插入当前层及以下所有层,否则,逐步向下层移动。
在检索过程中,从顶层的enter point开始进行顶层图BFS检索,当收敛时,跳至下一层图,进行BFS检索,逐级向下,直至最底层。
-
稀疏化选边技术
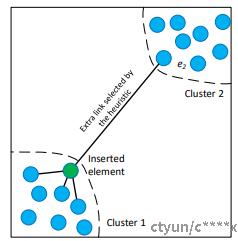
HNSW的剪枝策略与RNG相似,目的是增强图的可导航性或单调性,提升近似近邻检索的准确率。
如下图所示,针对绿色节点进行选边时,会对所有候选点按相似性排序,HNSW的选边策略会更倾向于选出更离散分布的邻居。
贡献点
- 改进了NSW的选边策略,开创性的提粗了分层导航图思想,刷新了近邻检索的精度和性能指标。
- 在高维数据集上的表现远高于其他类型索引,例如树、LSH等。
- HNSW作为最经典的图索引算法,在当今工业界依旧是SOTA方案之一。
NSSG(2020)
NSSG(Navigate Statellite System Graph,可导航卫星图),是一种高效的近似最近邻检索算法。其于HNSW等图检索算法明显的区别在于:1)单层图;2)利用SSG选边策略进行稀疏化;3)利用利用DFS算法进行连通性增强。该算法由浙大与阿里联合发表。在最新的glass库、kgn graph中均有实现(ANN Benchmark 打榜算法)。
整体方案
NSSG需要基于KNNG进行构建,KNNG的构建算法可以基于NNDescent或RNNDescent进行高效构建。完成KNNG的构建后,遍历所有节点,在KNNG上查找候选点并基于SSG选边策略进行正向边构建,正向SSG构建完成后,基于正向SSG进行边翻转构建反向SSG,并在反向SSG上基于SSG选边策略进行反向边构建,完成构建后,对正向SSG和反向SSG进行图融合。融合完成后,为了保证全图连通,通过DFS进行连通性增强。

技术点
1)SSG选边策略
通过实验与研究发现,图索引过于稀疏将导致检索半径增加,检索时延增加,因此适当的增加邻边选择可改善图索引的搜索效果。如下图所示,图c比图a有更小的搜索半径。
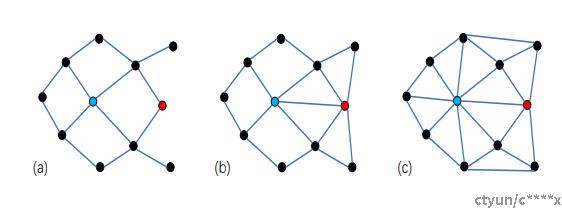
SSG选边旨在选择更加多样化的点作为当前候选点的邻居,防止候选点附近出现真空地带。如下图所示,SSG选边在构建边pq之后,尽可能在远离q的方向添加第二个邻居,因此其增加约束:
2)连通性增强
正向SSG与反向SSG进行图融合后,从图中随机选择一个点进行DFS遍历,检测图中是否存在多个连通分量,若存在,则需要将多个连通分量进行连边。
贡献点
- 提出了一种新的图索引结构和新的选边策略,并提供了详细的理论分析与证明
混合存储图检索技术
DiskANN(NIPS2019),DiskANN++(2023)
整体方案
随着十亿级高维向量检索需求、向量数据库场景需求,内存-磁盘混合存储得到广泛关注。DiskANN算法是微软发布的基于内存+SSD磁盘混合存储的向量检索算法,该算法可在64G内存+足量SSD磁盘上构建十亿级以上的向量索引,在 16 核 64G 内存的机器上对十亿级别的数据集 SIFT1B 建基于磁盘的图索引,并且 recall@1 > 95% 的情况下 qps 达到了 5000, 平均时延不到 3ms。,已被Milvus所支持。
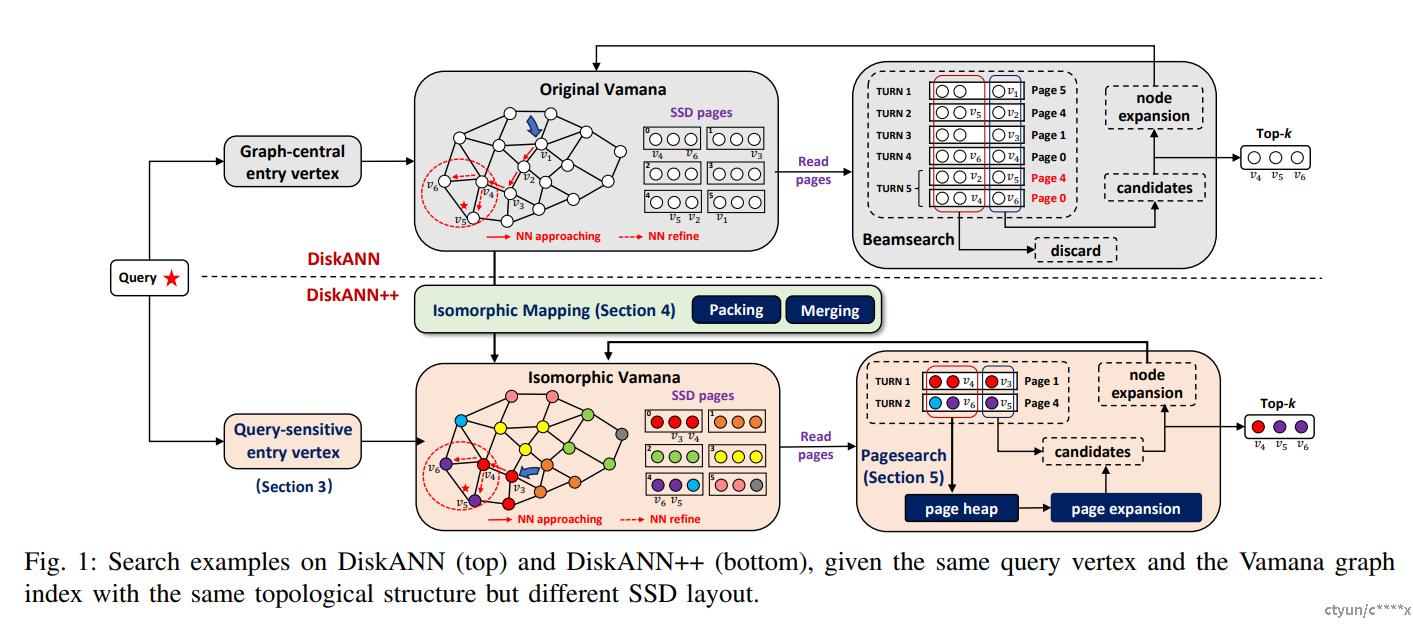
技术点
- 分片构图与合并:构建时基于KMean算法对全量数据进行冗余分桶,此时各个分桶之间可以保证有部分边界点重合。每一个分片分别构建Vamana图,构建完成后,不同分桶两两进行图融合。
- 松弛选边策略:相比与RNG选边策略,增加松弛因子控制图索引的稀疏和稠密状态。
- 缓存热点:将入口点附近的3~4跳子图缓存在内存中。
- beam search:通过beam search,可以减小搜索半径,减少磁盘访问次数。
贡献点
- DiskANN可支持在有限内存+足量SSD磁盘的机器上对十亿级别高维向量数据集进行索引构建和查询,并且 recall@1 > 95% 的情况下 qps 达到了 5000, 平均时延不到 3ms。
- 提出了新的图索引方案Vamana,相比HNSW、NSW等具有更小的搜索半径,最小化磁盘访问次数
- DiskANN提供了针对大规模数据集的构建方案,解决了在内存受限环境中图索引的构建问题。
- DiskANN可与现有的量化方案(如PQ)结合,量化数据存储在内存中,索引数据和向量数据存储在SSD中,加速整体的检索过程。
Starling(SIGMOD 2024)
整体方案
面向高维向量近似近邻检索场景,在向量数据库中,每个数据段所关联的内存和磁盘资源极为有限(2G内存、10G磁盘),STarling提出了一种混合磁盘的检索框架,只在内存限制的情况下,通过优化数据布局和搜索策略实现高效的高维向量检索。Starling相比其他索引,更偏向专为向量数据库设计的检索框架。
什么是数据段:向量数据库中向量数据的存储单元,一般一个分段的向量数据集规模在千万级。
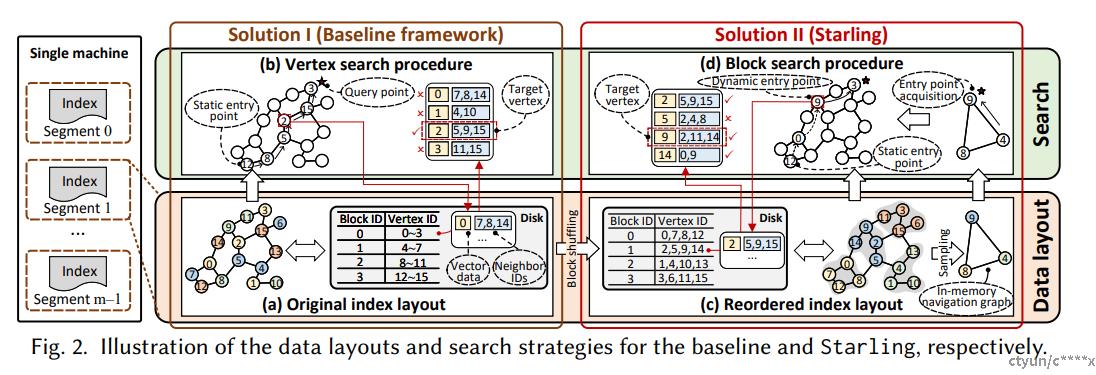
技术点
- 数据布局优化
- 基于采样数据的内存导航图:用于进行查询感知的入口点选择,与HNSW相似,快速收敛至query的邻域空间,可降低在磁盘图中的搜索半径。
- 磁盘存储的重排图:将空间临近的节点存储在一个block中,提高数据局部性,提升一次磁盘IO的节点利用率。
- 搜索策略优化:基于区块的搜索策略可以有效探索在该块中的所有有效数据,通过计算结果集中在线块中的节点与query距离并迭代更新位于下一跳搜索路径中的所有节点距离,尽可能一次加载充分计算。
贡献点
- 在具有2GB内存和10GB磁盘容量的数据段上,Starling可以容纳多达3300万个128维向量,提供平均精度超过0.9和前10个召回率,并且延迟低于1毫秒
- Starling是一个图索引框架,提供各种图索引算法,例如Vamana、NSG、HNSW等。
- 提出了一种新的数据布局方案,该方案包含两个部件:内存中的采样导航图和重排后的磁盘图。
- 提出了一种块搜索策略,该策略利用充足索引布局的局部性来减少磁盘I/O
硬件加速的图检索技术
Cagra(2023),CagraQ(2024)
整体方案
Cagra是NVIDIA在其基于GPU加速的向量检索加速库中发布的图检索算法,并且在GTC 2024大会上发布了CagraQ算法,一种基于图索引和量化加速的GPU图检索算法,其在大批量检索、小批量检索、索引构建上都刷新了基线。已集成至Milvus2.4版本,使能Milvus高达50倍检索性能提升。
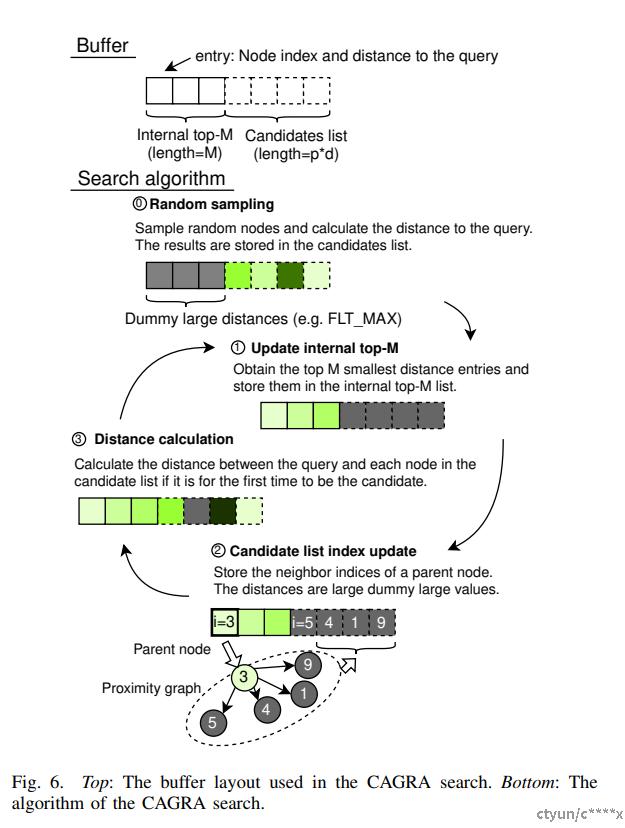
如下图所示,是Cagra算法的检索过程
Step 0:随机选取E个节点,计算他们与 query 的距离,并存在 candidate buffer 中
Step 1:在 top-M buffer(这里应该是上一轮的结果) 和 candidate buffer 中选取 top M 个结果存储在 Top-M buffer中
Step 2:在Top-M buffer中选取一个还没有被 traverse 的离 query 最近的节点
Step 3:选取与 Step 2 中选择的节点近邻的E个没有访问的节点,并计算他们与query的距离,然后存储在 Candidate buffer 中
Step1到Step3循环,直到Step 2找不到节点,或者满足其他条件
技术点
-
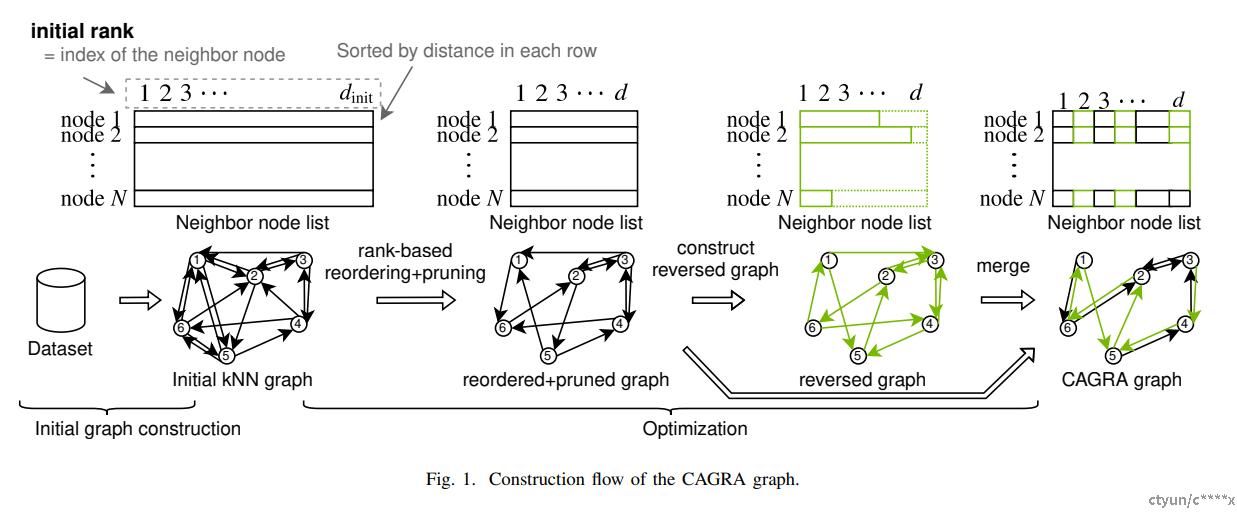
固定出度的图索引结构
Cagra在进行存储结构设计时考虑到GPU硬件特性,设置图出度为固定出度,此时在进行图遍历时可以避免不必要的逻辑判断和非对齐内存的拷贝,以小量的计算代价(可忽略不计)减少访存开销。
-
Small Hash Table:构建一个在共享内存中的Hash Table(周期性Reset),从而降低对全局现存的访问和同步代价。
-
team划分:对Warp中的线程进行软件层面的二次划分,从而提高对Cuda core的算力利用率
贡献点
- 针对不同batch提供不同的搜索策略:针对大batch,SingleCTA策略为每一个query分配一个thread-block进行计算;针对小batch,MultiCTA策略为一个query分配多个thread-block以充分利用GPU计算资源。
- 提供了在GPU上的图索引加速构建算法,可实现图索引的高质量高效构建
- CagraQ提供了一种基于异构加速的向量检索新范式,即在GPU上进行粗搜在CPU上进行精搜的检索流程。
- 在90%到95%召回率范围内的大批量查询吞吐量方面,Cagra比HNSW快33
77倍,并且比GPU的SOTA实现快3.88.8倍。对于单个查询,在95%召回率时比HNSW快3.4~53倍。
小结
上述几类图算法均是当前学术界与工业界的主流算法,目前图索引的几类优化思路总结如下:
- 优化图索引结构
- 通过data layout设计降低访存开销
- 通过量化、压缩、指令优化等方式进行亲和硬件的计算优化,增强计算效率
趋势展望
- 随着数据体量的逐步增加及应用场景的约束,混合磁盘存储的向量检索技术
- 向量数据库、互联网推荐等实际应用场景中都提出了属性过滤的诉求
- 硬件加速会基于性价比综合考虑,不会存在完全取代的形式。
- 图向量检索的构建应该被重视。
参考资料
[1] Ootomo, Hiroyuki et al. “CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs.” 2024 IEEE 40th International Conference on Data Engineering (ICDE) (2023): 4236-4247.
[2] Fu, Cong et al. “Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Graph.” Proc. VLDB Endow. 12 (2017): 461-474.
[3] Suhas Jayaram Subramanya, Devvrit, Rohan Kadekodi, Ravishankar Krishaswamy, and Harsha Vardhan Simhadri. 2019. DiskANN: fast accurate billion-point nearest neighbor search on a single node. Proceedings of the 33rd International Conference on Neural Information Processing Systems. Curran Associates Inc., Red Hook, NY, USA, Article 1233, 13766–13776.
[4] Cong Fu, Changxu Wang, and Deng Cai. 2022. High Dimensional Similarity Search With Satellite System Graph: Efficiency, Scalability, and Unindexed Query Compatibility. IEEE Trans. Pattern Anal. Mach. Intell. 44, 8 (Aug. 2022), 4139–4150.
