


一、引言
在自然语言处理(NLP)的迅猛发展浪潮中,大型语言模型(LLMs)凭借其强大的语言理解与生成能力,成为众多应用的核心驱动力。而 Prompt 作为连接用户意图与模型输出的关键纽带,其设计的优劣直接决定了模型能否生成符合预期的高质量内容。因此,深入探索 Prompt 的奥秘,对于充分释放 LLMs 的潜力具有至关重要的意义。
二、Prompt 基础
(一)定义
Prompt 是输入给语言模型的特定文本,它如同精确的指令,引导模型生成符合特定需求的输出。例如,当我们期望模型创作一段富有创意的科幻故事时,“在遥远的 2999年,人类发现了一颗神秘的星球,基于此创作一个充满悬念的科幻故事开头” 这样的文本就是一个典型的 Prompt。
(二)基本组成
- 指令表述:清晰地向模型传达所需执行的任务类型,如 “创作诗歌”“进行情感分析”“完成代码转换” 等。例如,“将以下中文句子转换为日语:我喜欢探索新的技术。”
- 上下文:提供任务相关的背景信息或约束条件,比如,“以轻松活泼的风格写一篇不超过 150 字的旅游景点介绍”。
- 输入文本:针对需要处理特定文本的任务,提供相应的文本内容。例如在文本摘要任务中,“对下面这篇关于人工智能发展趋势的文章进行摘要:[文章具体内容]”。
- 示例:给出部分样例,比如今天天气真好->情感:正面。
三、Prompt流程
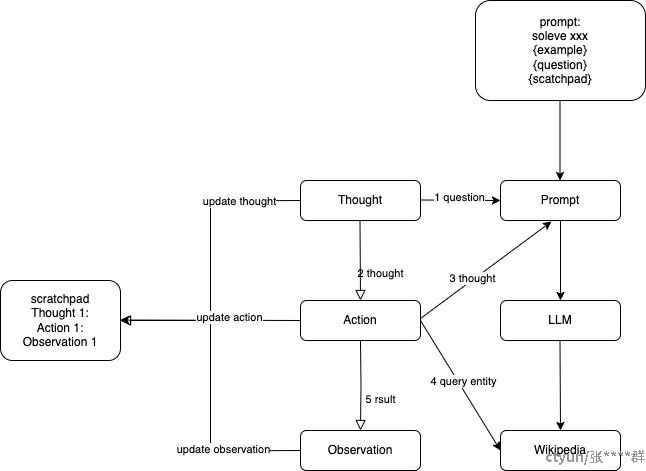
ReAct提供了一种更易于人类理解、诊断的决策和推理过程,他的流程如上,可以用一个有趣的循环来描述:思考-> 行动->观察,简称TAO循环。
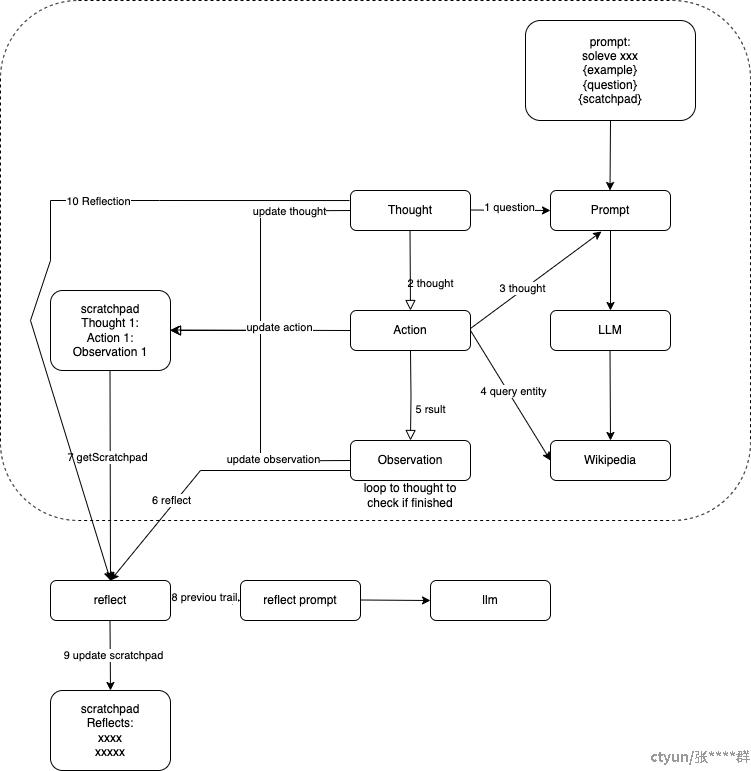
或者在现有问答的基础上更近一步指导模型进行自我优化和排除错误答案的过程,流程如下:
四、Prompt 设计原则
(一)清晰明确
Prompt 必须清晰避免歧义,确保模型能够精准把握任务要求。例如,“解释量子计算中量子比特的概念及应用” 相较于 “说说量子计算里量子比特是啥”,表述更为清晰准确,能引导模型生成更具针对性和深度的回答。以下通过 Python 代码结合 Hugging Face 的 Transformers 库展示不同 Prompt 的效果:
from transformers import pipeline
generator = pipeline('text - generation', model='gpt2')
# 加入prompt之前
vague_prompt = "说说量子计算里量子比特是啥"
vague_result = generator(vague_prompt, max_length = 200, num_return_sequences = 1, temperature = 0.7)
print("加入prompt之前的结果:")
print(vague_result[0]['generated_text'])
# 加入prompt之后
clear_prompt = "解释量子计算中量子比特的概念及应用"
clear_result = generator(clear_prompt, max_length = 200, num_return_sequences = 1, temperature = 0.7)
print("\n加入prompt之后的结果:")
print(clear_result[0]['generated_text'])
在上述代码中,
temperature 参数用于调节生成文本的随机性,值越趋近于 0,生成结果越稳定、确定;值越大,生成内容的多样性越高。通过对比可以明显看出,清晰的 Prompt 促使模型生成的内容更准确、详实。(二)简洁性
在完整传达任务信息的前提下,Prompt 应尽量简洁。过于冗长复杂的表述可能会分散模型的注意力,降低其处理效率。例如,“以秋天为主题创作一首短诗” 相较于详细描述秋天的各种景色、氛围,再提出写诗要求,更为简洁高效。
from transformers import pipeline
generator = pipeline('text - generation', model='gpt2')
# 加入prompt之前
lengthy_prompt = "秋天是一个非常美丽的季节,树叶开始变色,从绿色变成金黄色、红色,秋风轻轻吹过,带来丝丝凉意。在这样的情境下,创作一首以秋天为主题的诗,要体现出秋天的独特韵味。"
lengthy_result = generator(lengthy_prompt, max_length = 150, num_return_sequences = 1, top_p = 0.9)
print("加入prompt之前的结果:")
print(lengthy_result[0]['generated_text'])
# 加入prompt之后
concise_prompt = "以秋天为主题创作一首短诗"
concise_result = generator(concise_prompt, max_length = 150, num_return_sequences = 1, top_p = 0.9)
print("\n加入prompt之后的结果:")
print(concise_result[0]['generated_text'])
这里的
top_p 参数运用核采样方法,从概率质量排名在前 top_p 比例的词中进行采样,使生成的文本更自然、丰富。对比结果显示,简洁的 Prompt 让模型更专注于核心任务,生成的诗歌更贴合主题。(三)相关性
Prompt 的内容应与期望的输出紧密相关。若希望模型生成有关美食烹饪的内容,Prompt 应围绕美食主题展开,如 “描述如何制作一道美味的意大利面”。
from transformers import pipeline
generator = pipeline('text - generation', model='gpt2')
# 加入prompt之前
irrelevant_prompt = "谈谈最近的科技新闻,顺便说一下如何制作一道美味的意大利面"
irrelevant_result = generator(irrelevant_prompt, max_length = 250, num_return_sequences = 1, repetition_penalty = 1.2)
print("加入prompt之前的结果:")
print(irrelevant_result[0]['generated_text'])
# 加入prompt之后
relevant_prompt = "描述如何制作一道美味的意大利面"
relevant_result = generator(relevant_prompt, max_length = 250, num_return_sequences = 1, repetition_penalty = 1.2)
print("\n加入prompt之后的结果:")
print(relevant_result[0]['generated_text'])
repetition_penalty 参数用于抑制模型生成重复内容,值大于 1 时,可有效减少重复的可能性。从对比可知,相关性强的 Prompt 能使模型生成的内容更符合用户需求,避免因无关信息导致的偏离。(四)引导性
为模型提供适当的思考方向引导,有助于生成更契合预期的内容。在故事创作中,“在一个充满神秘色彩的魔法小镇,住着一位拥有神奇画笔的小女孩,以此为背景创作一个故事的开头” 为模型构建了清晰的创作框架。
from transformers import pipeline
generator = pipeline('text - generation', model='gpt2')
# 加入prompt之前
unguided_prompt = "创作一个故事"
unguided_result = generator(unguided_prompt, max_length = 180, num_return_sequences = 1, no_repeat_ngram_size = 2)
print("加入prompt之前的结果:")
print(unguided_result[0]['generated_text'])
# 加入prompt之后
guided_prompt = "在一个充满神秘色彩的魔法小镇,住着一位拥有神奇画笔的小女孩,以此为背景创作一个故事的开头"
guided_result = generator(guided_prompt, max_length = 180, num_return_sequences = 1, no_repeat_ngram_size = 2)
print("\n加入prompt之后的结果:")
print(guided_result[0]['generated_text'])
no_repeat_ngram_size 参数防止模型生成相同的连续 n 个词,避免内容重复。通过对比,具有引导性的 Prompt 使模型生成的故事开头更具针对性和吸引力。五、Prompt 类型及应用
(一)问题型 Prompt
- 定义与应用:以提问的形式引导模型依据其知识储备给出答案,广泛应用于问答系统。例如,“地球的公转周期精确到天是多少天?”
from transformers import pipeline
qa_pipeline = pipeline('question - answering', model='distilbert - base - uncased - squad2')
context = "地球绕太阳公转一周的时间约为365.24219天,这就是我们通常所说的一年。这种公转运动对地球的气候和季节变化有着深远影响。"
# 加入prompt之前
general_question = "地球公转相关信息"
general_qa_result = qa_pipeline({'question': general_question, 'context': context})
print("加入prompt之前的回答:")
print(general_qa_result.get('answer', '回答不明确'))
# 加入prompt之后
specific_question = "地球的公转周期精确到天是多少天?"
specific_qa_result = qa_pipeline({'question': specific_question, 'context': context})
print("\n加入prompt之后的回答:")
print(specific_qa_result.get('answer', '回答不明确'))
从上述代码可以看出,明确具体的问题型 Prompt 能够让模型给出更准确的答案。在实际应用中,还可通过优化上下文内容或选用更强大的问答模型来提升回答质量。
(二)指令型 Prompt
- 定义与应用:明确指示模型执行特定任务,如文本创作、语言翻译、代码编写等。例如,“将以下 JavaScript 函数转换为 Python 函数:[JavaScript 函数代码]”
# 假设这里使用一个简单的代码转换示例,实际应用可能需要更复杂的处理
javascript_code = "function addNumbers(a, b) { return a + b; }"
# 加入prompt之前
basic_instruction = "处理这段代码"
print(f"加入prompt之前的指令:{basic_instruction}")
# 这里可以使用专门的代码转换工具或模型,为简化示例,暂不实际调用
# 加入prompt之后
specific_instruction = f"将以下JavaScript函数转换为Python函数:{javascript_code}"
print(f"\n加入prompt之后的指令:{specific_instruction}")
对比前后指令,具体的指令型 Prompt 清晰地告知模型任务内容,有助于模型准确执行任务。在实际场景中,可结合专业的代码分析库和自然语言处理技术,实现更高效准确的代码转换。
(三)示例型 Prompt
- 定义与应用:通过给出示例,让模型模仿生成类似的内容,适用于风格模仿、格式生成等任务。例如,“按照以下格式撰写一份宠物猫饲养指南:饮食 - [具体饮食建议],生活环境 - [环境要求],常见健康问题 - [相关问题及解决方法]”
from transformers import pipeline
generator = pipeline('text - generation', model='gpt2')
# 加入prompt之前
basic_example_prompt = "写一份宠物猫饲养指南"
basic_example_result = generator(basic_example_prompt, max_length = 200, num_return_sequences = 1, attention_mask = None)
print("加入prompt之前的结果:")
print(basic_example_result[0]['generated_text'])
# 加入prompt之后
example_prompt = "宠物狗饲养指南:饮食 - 以优质狗粮为主,适当添加肉类和蔬菜;生活环境 - 保持狗窝清洁干燥,提供充足活动空间;常见健康问题 - 易患皮肤病,定期洗澡驱虫。"
new_prompt = "按照上述格式撰写一份宠物猫饲养指南"
new_example_result = generator(new_prompt, max_length = 200, num_return_sequences = 1, attention_mask = None)
print("\n加入prompt之后的结果:")
print(new_example_result[0]['generated_text'])
attention_mask 参数用于指定模型对哪些标记予以关注,默认 None 时模型自动处理。通过对比可见,示例型 Prompt 为模型提供了明确的格式和风格范例,使生成的内容更符合要求。六、Prompt 优化与案例研究
(一)优化方法
- 增加上下文:为模型提供更多背景信息,帮助其更好地理解任务。在情感分析中,除了待分析文本,增添文本来源背景信息,能使模型更精准地判断情感倾向。
from transformers import pipeline
sentiment_pipeline = pipeline('sentiment - analysis', model='distilbert - base - uncased - finetuned - sst - 2 - english')
text = "这家餐厅的菜品味道还不错,但服务速度有待提高。"
# 加入context之前
basic_sentiment_prompt = text
basic_sentiment_result = sentiment_pipeline(basic_sentiment_prompt)
print("加入context之前的情感判断:")
print(basic_sentiment_result[0]['label'])
# 加入context之后
context = "这是一位顾客在大众点评上对一家餐厅的评价"
full_prompt = f"{context}:{text}"
full_sentiment_result = sentiment_pipeline(full_prompt)
print("\n加入context之后的情感判断:")
print(full_sentiment_result[0]['label'])
进一步优化时,可以引入外部知识库或情感词典,如
VADER 情感词典,对文本进行预处理,为模型提供更丰富的情感线索。通过对比发现,增加上下文后的 Prompt 使模型对情感倾向的判断更为准确。