


一、技术背景
实时音视频通信场景(比如视频会议、云游戏等场景)对低延时、高速度的响应要求非常高,所以延时卡顿将会影响云游戏的画面呈现及用户体验。目前技术挑战主要是如何优化编解码渲染技术和传输技术,降低整体延时和卡顿,提升画面呈现效果及用户体验
二、技术目的
目前解码渲染方案是将硬解码得到的NV12数据拷贝回CPU内存,然后通过sws_scale将NV12格式转成RGBA/YUV420格式,进而再调用对应的渲染器渲染。现有方案数据拷贝回CPU将会导致解码渲染耗时较大,卡顿,影响画面呈现效果及用户体验。本专利无需将硬解码的数据拷贝回CPU内存,该方法主要是创建纹理Shader资源视图绑定渲染管线,设置扩展像素Shader访问纹理Shader资源视图,使用NV12并输出RGBA进行渲染,这样可以将解码渲染数据流工作全部交给GPU来处理,极大解放CPU,解决了因为数据拷贝导致延时卡顿问题。
三、技术方案
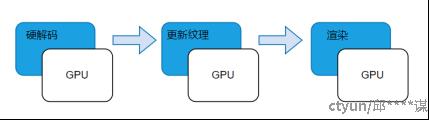
GPU解码渲染方法主要包括以下步骤:
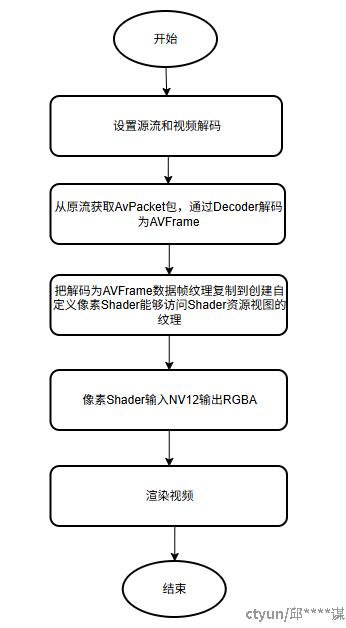
1) 设置源流和视频Decoder,该步骤主要初始化相关数据结构,设置格式上下文以及En/Decoder上下文(本发明采用FFmepg D3D11va硬解码相关初始化配置)。
2) 通过1)设置完成,从源流获取AvPacket包,使用En/Decoder解码为AVFrame。
3) 创建一个ID3D11Texture2D纹理对象,纹理对象通过创建Chroma和Luminance两个Shader资源视图绑定到渲染管线上,最后设置自定义像素Shader(输入NV12并输出RGBA)能够访问Chroma和Luminance这两个通道。
4) 将接收到的AVFrame数据帧纹理通过内置的DirectX函数复制到第3)步创建的纹理对象。
根据2),3),4)就可以无需将硬解码的数据拷贝回CPU内存,而是直接在GPU进行处理之后渲染视频帧。
四、技术方案流程图
5、总结
通过创建纹理Shader资源视图绑定渲染管线,设置扩展像素Shader访问纹理Shader资源视图,使用NV12并输出RGBA进行渲染,使解码渲染数据流都在GPU处理,极大解放CPU,降低延时
