KNN算法概述
KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。KNN算法的思想非常简单:对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
实现代码
代码中已包含必要的注释
import numpy as np
from collections import Counter
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
class KNN:
"""
K-最近邻分类器实现
"""
def __init__(self, k=3):
"""
初始化KNN模型
参数:
k (int): 最近邻的数量,默认为3
"""
self.k = k
self.X_train = None
self.y_train = None
def fit(self, X_train, y_train):
"""
训练模型(存储训练数据)
参数:
X_train (ndarray): 训练特征数据,形状为(n_samples, n_features)
y_train (ndarray): 训练标签数据,形状为(n_samples,)
"""
self.X_train = X_train
self.y_train = y_train
def predict(self, X_test):
"""
预测测试数据的标签
参数:
X_test (ndarray): 测试特征数据,形状为(n_samples, n_features)
返回:
ndarray: 预测的标签数组
"""
predictions = [self._predict(x) for x in X_test]
return np.array(predictions)
def _predict(self, x):
"""
单个数据点的预测方法
参数:
x (ndarray): 单个数据点的特征向量
返回:
int: 预测的类别标签
"""
# 1. 计算当前点与所有训练数据点的距离
distances = [self._euclidean_distance(x, x_train) for x_train in self.X_train]
# 2. 获取距离最近的k个样本的索引
k_indices = np.argsort(distances)[:self.k]
# 3. 获取这些样本对应的标签
k_nearest_labels = self.y_train[k_indices]
# 4. 进行多数投票,返回最常见的类别
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]
def _euclidean_distance(self, x1, x2):
"""
计算两个向量之间的欧氏距离
参数:
x1, x2 (ndarray): 两个特征向量
返回:
float: 欧氏距离
"""
return np.sqrt(np.sum((x1 - x2) ** 2))
# 示例使用:在鸢尾花数据集上测试KNN
if __name__ == "__main__":
# 1. 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. 初始化KNN模型(k=5)
knn = KNN(k=5)
# 4. 训练模型
knn.fit(X_train, y_train)
# 5. 预测测试集
predictions = knn.predict(X_test)
# 6. 计算准确率
accuracy = accuracy_score(y_test, predictions)
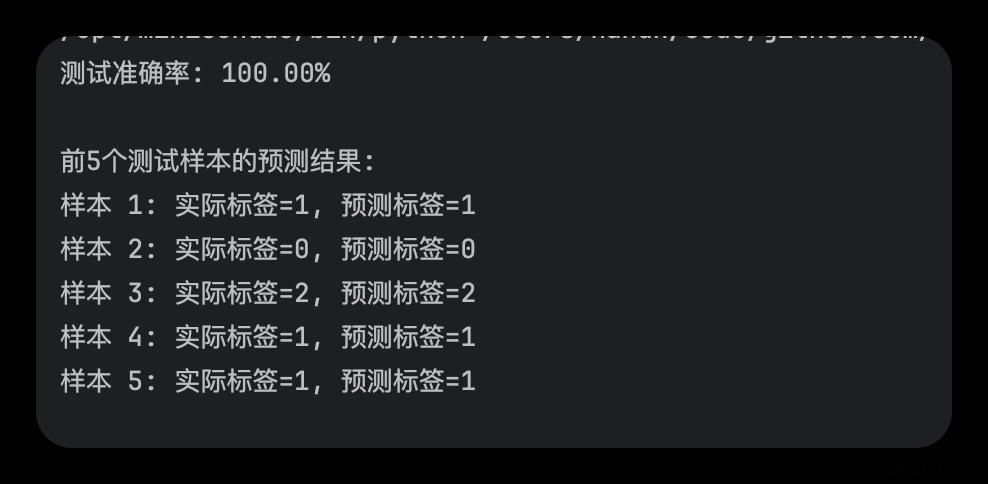
print(f"测试准确率: {accuracy:.2%}")
# 打印前5个测试样本的预测结果
print("\n前5个测试样本的预测结果:")
for i in range(5):
print(f"样本 {i + 1}: 实际标签={y_test[i]}, 预测标签={predictions[i]}")
执行结果