


作者训练模型和使用模型的设备为mac,如果使用cuda加速需要按需修改代码中的device字段
1. 项目概述与目标
手写数字识别是计算机视觉和深度学习领域的经典入门项目。MNIST数据集(Modified National Institute of Standards and Technology database)包含了大量0-9的手写数字灰度图片,每张图片的尺寸为28x28像素。我们的目标是构建一个深度学习模型,能够准确地对这些图片进行分类。
项目目标:
- 实现一个模型,在MNIST测试集上达到99%+的准确率。
- 理解卷积神经网络(CNN)的基本构件和工作流程。
- 提供一个清晰、可复现的代码框架。
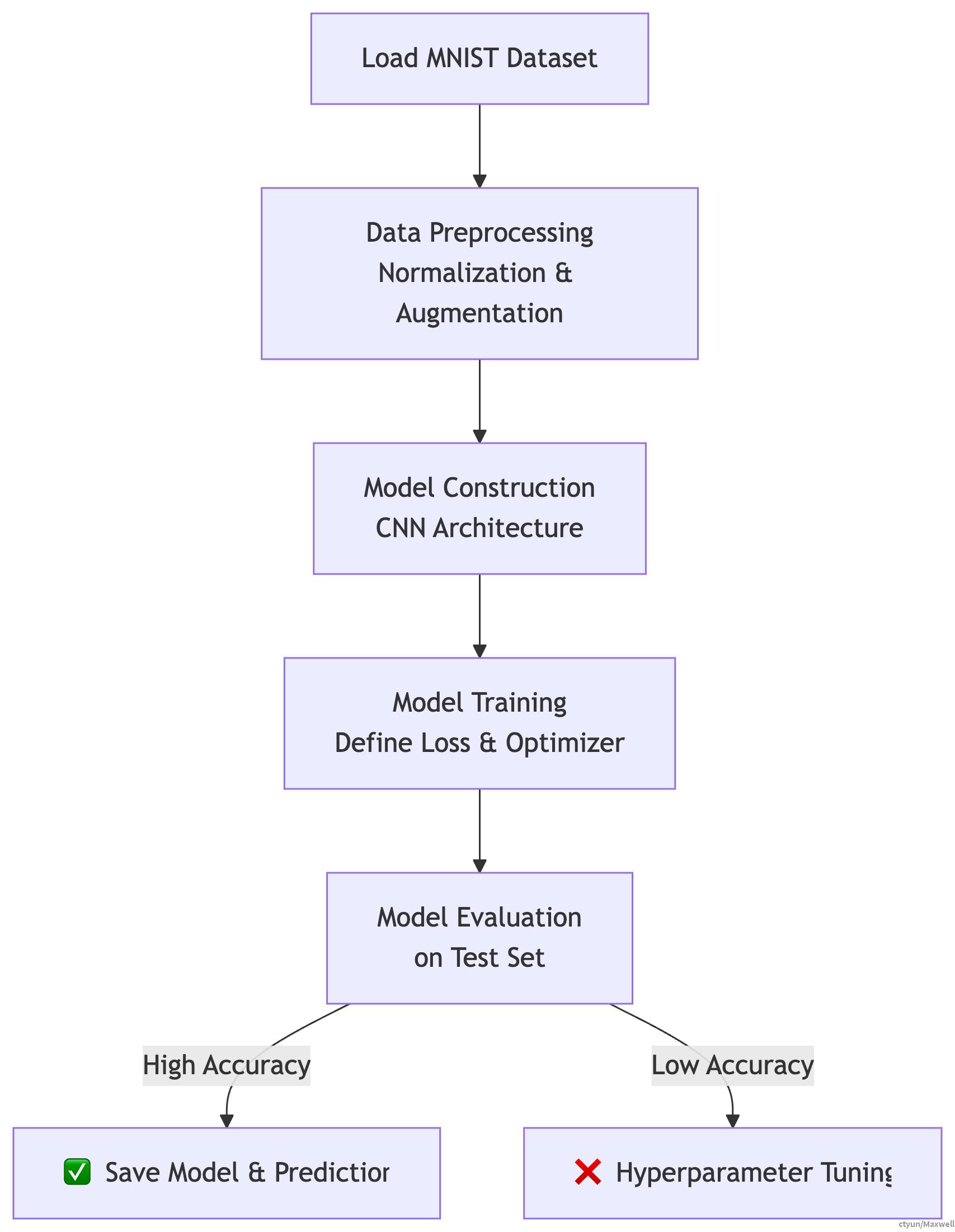
2. 整体流程
我们将遵循一个标准的深度学习工作流,其全过程如下图所示:
3. 核心步骤详解
3.1 数据准备与预处理 (Data Preparation)
MNIST数据集非常流行,可以通过PyTorch的torchvision库直接下载和加载。
关键步骤:
- 加载数据: 使用
torchvision.datasets.MNIST获取已经划分好的训练集和测试集。 - 数据预处理:
- **归一化 (Normalization)**: 将像素值从[0, 255]缩放到[0, 1]或使用均值和标准差归一化。我们通常采用
transforms.Normalize((0.1307,), (0.3081,)),这是MNIST常用的均值和标准差。 - 转换为张量: 使用
transforms.ToTensor()将图像转换为PyTorch张量,并自动将维度从(H, W, C)变为(C, H, W)。 - **数据增强 (可选)**: 可以添加旋转、平移等增强方式,但MNIST比较简单,通常不需要复杂的增强。
- **归一化 (Normalization)**: 将像素值从[0, 255]缩放到[0, 1]或使用均值和标准差归一化。我们通常采用
- 数据加载器: 使用
DataLoader进行批量加载和数据打乱。
3.2 模型构建:CNN架构
我们将构建一个包含两个卷积层、两个 dropout 层和两个全连接层的CNN。具体结构如下:
网络结构:
| 层 (Layer) | 参数 | 输出形状 (Batch, ...) |
|---|---|---|
| Input | - | (1, 28, 28) |
| Conv2d | in_channels=1, out_channels=32, kernel_size=3, stride=1 | (32, 26, 26) |
| ReLU | - | (32, 26, 26) |
| Conv2d | in_channels=32, out_channels=64, kernel_size=3, stride=1 | (64, 24, 24) |
| ReLU | - | (64, 24, 24) |
| MaxPool2d | kernel_size=2 | (64, 12, 12) |
| Dropout | p=0.25 | (64, 12, 12) |
| Flatten | - | (64*12*12=9216) |
| Linear | in_features=9216, out_features=128 | (128) |
| ReLU | - | (128) |
| Dropout | p=0.5 | (128) |
| Linear | in_features=128, out_features=10 | (10) |
3.3 模型训练 (Training)
在训练之前,我们需要定义损失函数和优化器。
- **损失函数 (Loss Function)**: 由于是多分类问题,使用交叉熵损失
nn.CrossEntropyLoss()。 - **优化器 (Optimizer)**: 选择
Adam优化器。 - 训练循环: 逐批次数据训练模型,并定期在验证集上评估性能。
3.4 模型评估与预测 (Evaluation & Prediction)
- 评估: 在测试集上计算准确率,评估模型性能。
- 预测: 对新的图片数据进行预测,使用
torch.argmax()函数获取预测类别。
代码实现:
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from PIL import Image
import argparse
import os
# 模型定义
class MNISTModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = torch.relu(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
return x
# 训练函数
def train_model(epochs=15, batch_size=128, lr=0.001):
device = torch.device("mps" if torch.mps.is_available() else "cpu")
model = MNISTModel().to(device)
optimizer = optim.AdamW(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_set = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
start = time.time()
for epoch in range(epochs):
model.train()
total_loss = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {total_loss / len(train_loader):.4f}')
os.makedirs('models', exist_ok=True)
torch.save(model.state_dict(), 'models/mnist_model.pth')
print("模型已保存到 models/mnist_model.pth")
print("训练耗时: {:.3f} 秒".format(time.time() - start))
# 推理函数
def predict_image(image_path, model_path='models/mnist_model.pth'):
device = torch.device("mps" if torch.mps.is_available() else "cpu")
model = MNISTModel().to(device)
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval()
transform = transforms.Compose([
transforms.Grayscale(),
transforms.Resize((28, 28)),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
result = []
if os.path.isdir(image_path):
for file in os.listdir(image_path):
if file.endswith('.png'):
image = Image.open(os.path.join(image_path, file))
tensor = transform(image).unsqueeze(0).to(device)
with torch.no_grad():
output = model(tensor)
pred = output.argmax(dim=1).item()
result.append(pred)
print("file: {}, predict: {}".format(file, pred))
else:
print("image_path is not a directory")
image = Image.open(image_path)
tensor = transform(image).unsqueeze(0).to(device)
with torch.no_grad():
output = model(tensor)
pred = output.argmax(dim=1).item()
result.append(pred)
print("file: {}, predict: {}\n".format(image_path, pred))
return result
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='MNIST训练与推理脚本')
parser.add_argument('--train', action='store_true', help='训练模型')
parser.add_argument('--predict', type=str, help='预测图片路径')
parser.add_argument('--epochs', type=int, default=15, help='训练轮数')
parser.add_argument('--batch_size', type=int, default=128, help='批次大小')
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
args = parser.parse_args()
if args.train:
train_model(epochs=args.epochs, batch_size=args.batch_size, lr=args.lr)
elif args.predict:
predict_image(args.predict)
else:
print("请指定 --train 或 --predict 参数")
4. 超越基准:优化技巧
达到99%的准确率后,你可以尝试以下方法进一步提升模型性能或深化理解:
- 调整超参数: 如学习率、批量大小、 dropout 比率等。
- 更改网络结构: 如增加卷积层、使用批归一化(Batch Normalization)等。
- 使用不同的优化器: 如SGD、RMSprop等。
- 数据增强: 对训练图像进行随机旋转、缩放、平移等,增加模型的泛化能力。
5. 总结
通过本项目,你已经成功实现了一个CNN模型来解决手写数字识别问题。这个从数据准备到模型评估的流程,是解决绝大多数图像分类问题的通用模板。希望这个清晰的指南能为你更深入地探索计算机视觉世界打下坚实的基础!
现在,去填充代码,运行它,亲眼见证你的第一个AI模型工作起来吧!
