


1.背景介绍
主要功能
- 多步骤信息收集与推理:Deep Research能够自主进行多步骤的网络检索,快速整合来自互联网的海量信息,包括文本、图像和PDF文件。
- 专业级报告生成:通过分析和综合数百个在线资源,Deep Research能在5到30分钟内生成一份带有详细引用的专业报告,大幅缩短传统研究所需时间。
应用场景
- 学术研究:学生和研究人员可以利用Deep Research快速获取相关领域的深入资料,辅助论文写作和课题研究。
- 市场分析:企业可以使用该工具进行市场调研、竞争对手分析及产品比较等,支持商业决策。
- 产品评估:消费者能够借助Deep Research对比不同产品的特性和评价,做出明智的购买决策。
2. DeepResearch、Deep Search、RAG三者有什么区别?
2.1.1. RAG是什么?
RAG(增强检索生成)是去年比较火的概念,因为大模型不具备实时联网的能力,所以在问答的时候需要通过搜索引擎来检索实时的信息,所以RAG成为了一种通用AI产品的标配,RAG的原理很简单,就是大模型在执行回答的时候,先检索与用户输入的提示词相关的信息,然后阅读检索的内容,最后针对问题做出回答,整个过程中,只执行一次检索,然后直接做出回答;
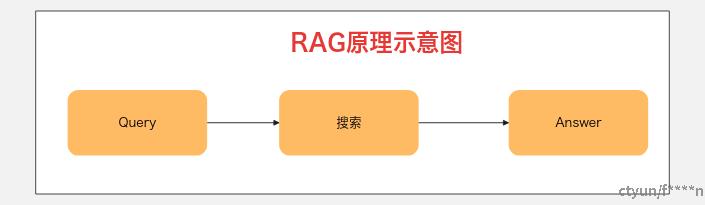
RAG的局限性就是比较依赖搜索引擎和检索数据源,想要一次性就准确并且完整的检索到回答用户问题需要的参考信息难度比较大,很容易出现检索数据缺漏,或者检索结果质量深度不够的问题,比较适合快搜索以及简单问答场景。
2.1.2. Deep Search是什么?
Deep Search则是在RAG 基础上引入多步迭代机制,通过「搜索→阅读→推理→再搜索」的循环流程持续的检索,直到满足某一业务设定的条件才终止,最终最大限度的获得更好的结果。Deep Search的价值在于提升检索结果的相关性和全面性,让用户在面对复杂问题时更容易找到所需信息。
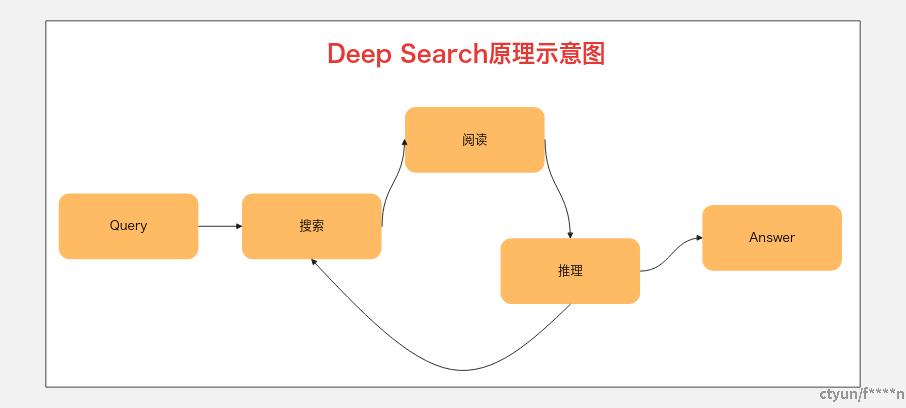
这个过程中,用户输入提示词之后,系统会初步检索,并阅读检索的结果,然后推理判断目前的检索结果是否足以很好的回答当前的问题,比如如果分析发现依然存在信息缺口后触发二次检索,直至满足预设终止条件(比如token 预算耗尽或答案结果的置信度达标)。
这种设计方式,构建了一个机制,让系统能够尽可能更多的去检索更多的结果,并且在检索的过程中能够及时的发现存在的问题,并进一步努力优化,从而可以显著提升检索结果的丰富度和准确度,并且提升回答结果的准确度、完整性等。但是可想而知的是,这个方式,必然导致的是检索和响应问答的时间会延长,问答的成本会提高很多。
2.1.3. Deep ReSearch是什么?
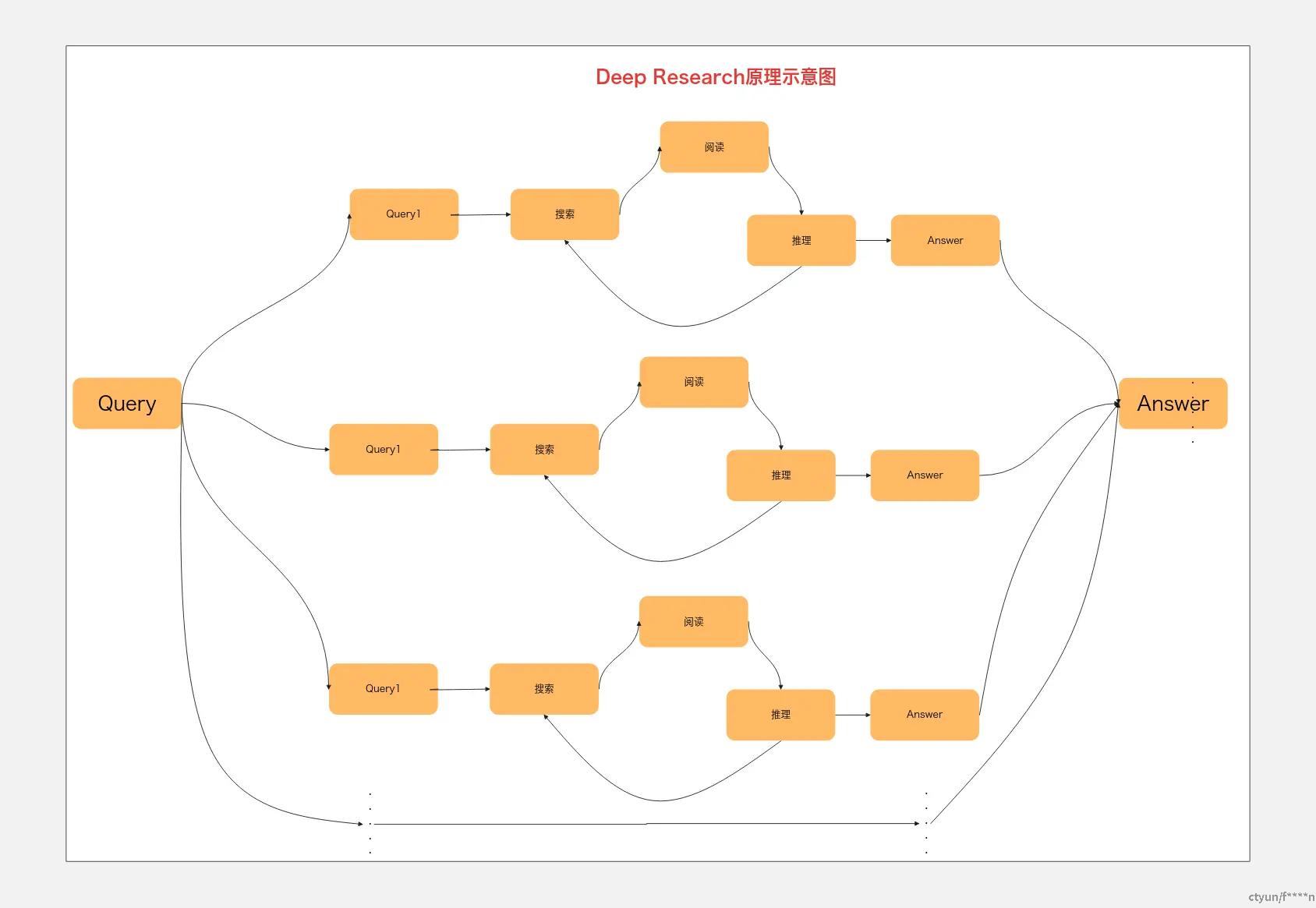
DeepResearch的功能侧重在于自动化的深度分析与综合。它不仅检索信息,还对信息进行推理判断、归纳总结,最终输出结构化的见解。Deep Research和Deep Search的区别在于,Deep Research模式之下,系统会在回答用户的问题的时候,会先构建一个系统的提纲,然后在回答每一级提纲的内容的时候,都走一遍Deep Search的流程,假如有100个大纲,则需要执行100次Deep Search的过程;因此Deep Research模式下可以生成非常长、且有深度的内容,达到超长的研究报告的水平。
3. 目前市面上有哪些DeepResearch产品?
3.1. 海外的DeepResearch产品
- OpenAI Deep Research
目前仅针对付费用户开放使用,20美元/月的PLUS用户每月开放10次免费使用额度,200美元/月的PRO会员每月可免费使用120次;该能力基于o3模型,主打高端用户市场,面向有深度研究需求的用户群体,强调推理能力和高质量报告生成。
- Gemini DeepResearch
Google是最早提出 DeepResearch这个概念的企业,目前在Gemini中也推出了Gemini DeepResearch的功能,且针对免费用户每月可免费体验5次,相比ChatGPT相对更加友好。
- Perplexity Pro Search
Perplexity在2025年2月13日也推出了自己的Deep Research 产品,并且面向免费用户每天提供3次的使用权限,付费订阅用户每个月可使用300次,免费权益粒度比Gemini更高。
- node-DeepResearch
这是一个开源的DeepResearch产品,代码完全公开在github,访问链接为 https://github.com/jina-ai/node-DeepResearch,产品的基础模型基于开源模型(如DeepSeek-R1等),支持切换OpenAI等其他模型,也支持支持本地部署和二次开发,该产品不可直接体验,适用于企业研发使用。
3.2. 国内的DeepResearch产品
- 研学智得AI
研学智得AI是由中国知网(CNKI)基于”华知大模型”开发的AI学术文献阅读与写作辅助工具。作为国内最大的学术资源平台,中国知网依托其海量学术文献资源,将AI技术与学术研究需求相结合,为学术界提供专业服务。
- Reportify
Reportify由北京积沙成塔科技有限公司开发。该产品专注于财经领域的深度内容问答和AI搜索。近期,Reportify已与摩尔线程公司达成合作,集成MUSAChat大语言模型推理API云服务,以提升问答系统效率。
- OpenDeepResearcher
Open Deep Research 是一个开源的 AI 智能体,旨在通过推理大量网络数据完成复杂的多步骤研究任务。它是 Deep Research 的开源复现项目,不依赖 OpenAI 的 o3 微调模型,而是使用 Firecrawl 的搜索和提取功能,结合多种语言模型(如 OpenAI、Anthropic、Cohere 等)进行数据分析和推理。
作为参考对比,智谱AutoGLM沉思是由智谱AI推出的一款集深度研究与实际操作能力于一体的AI智能体。它融合了GLM-4通用能力、GLM-Z1反思能力与AutoGLM执行能力,通过强化学习实现”边想边干”的创新模式。
- 秘塔AI
秘塔科技旗下的产品,由输入复杂问题,即可获得一份由“问题链”层层展开、自动检索、交叉验证并以表格或段落形式呈现的全景报告,而整个过程的推理路径可被实时查看和回溯。
4. DeepResearch核心组件
4.1. 搜索引擎:API vs. 浏览器
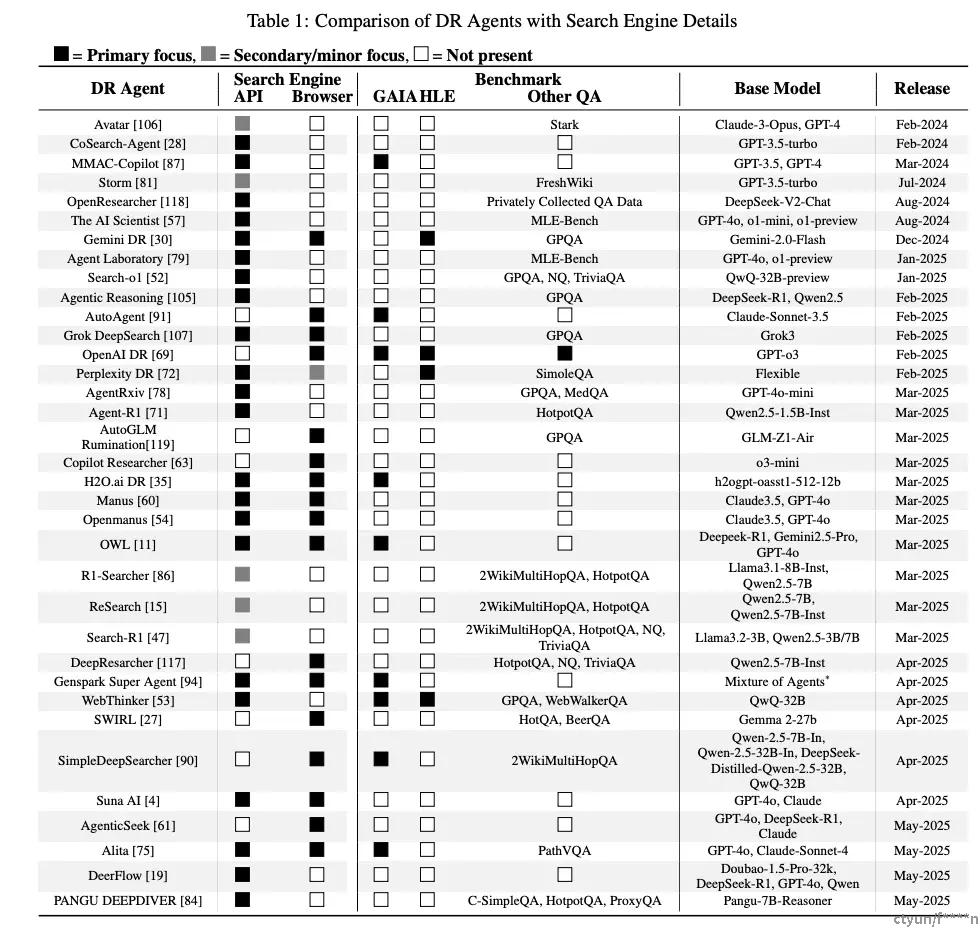
为提升推理深度和应对动态任务,DR智能体通过搜索引擎(SE)与外部环境交互,实时更新知识。表格展示了主流DR智能体采用的搜索引擎、基础模型和评测基准。搜索引擎主要分为两类:
- API型搜索引擎:通过结构化API(如搜索引擎API、科学数据库API)高效获取有组织的信息。
比如,谷歌 Gemini Deep Research 通过 Google Search API 和 arXiv API,对数百至数千个网页进行大规模检索,从而显著扩展其信息覆盖范围;Grok DeepSearch 宣称通过新闻媒体源、 X 的原生接口持续索引,以及根据需要激活查询驱动的代理来生成有针对性的子查询并实时获取相关页面,从而确保其知识库的新鲜度和深度。
2.浏览器型搜索引擎:模拟人类浏览网页,实时提取动态或非结构化内容,提升外部知识的全面性。
Manus 就是其典型代表,其浏览器代理会为每个研究会话运行一个沙箱环境(Sandbox),程序化地打开新标签页、发出搜索查询、点击结果链接、滚动页面直到达到内容阈值、在必要时填写表单元素、执行页面内 JavaScript 以显示延迟加载部分以及下载文件或 PDF 以供本地分析。
两种方式各有优劣。基于 API 调用的搜索引擎往往有更高的效率,但高度依赖内容源的开放性,它更适合谷歌这种本身就做搜索引擎的企业;基于浏览器的搜索引擎会像人类操作一样获取任何浏览器内的信息,但带来了更大的延迟与成本。在实际的应用中,两者可能会深度结合在一起使用。
4.2. 工具使用:为agent赋能扩展功能
为扩展DR智能体在复杂研究任务中与外部环境交互的能力,特别是主动调用和处理多样化工具与数据源,众多DR智能体引入了几大核心工具模块:代码解释器、数据分析、多模态处理等。
- 代码解释器
代码解释器能力使DR智能体能够在推理过程中执行脚本,实现数据处理、算法验证和模型仿真。除CoSearchAgent外,大多数DR智能体都内置了脚本执行环境,通常依赖Python工具(如Aider)和Java工具,支持动态脚本编排、文献驱动分析以及实时计算推理。
- 数据分析
通过集成数据分析模块,DR智能体能够将原始检索结果转化为结构化数据,包括计算统计摘要、生成可视化图表和进行定量模型评估,从而加速假设验证和决策过程。许多商业DR智能体已实现本地或远程的数据分析功能,如图表生成、表格制作和统计分析,但大多未公开具体技术细节。学术研究中,CoSearchAgent在团队协作平台中集成了基于SQL的查询,实现聚合分析和报告生成;AutoGLM可直接从网页表格中提取和分析结构化数据;Search-o1的Reason-in-Documents模块则对长文本检索结果进行精炼,提取关键指标用于后续评估。
- 多模态处理与生成
多模态处理与生成工具使DR智能体能够在统一推理流程中集成、分析和生成文本、图片、音频、视频等异构数据,丰富了上下文理解并拓展了输出形式。目前仅有部分成熟的商业和开源项目(如Manus、OWL、AutoAgent、AutoGLM、OpenAI、Gemini、Perplexity、Grok DeepSearch)支持该能力,大多数学术原型因计算资源限制尚未实现。以OWL和Openmanus为例,它们将推理流程扩展到与GitHub、Notion、Google Maps等平台交互,并结合Sympy、Excel等数值库,实现数据分析与多模态媒体处理。
- 具备计算机操作能力的深度研究智能体
近期,DR智能体的边界正通过集成计算机辅助任务执行能力(即计算机使用)不断拓展。例如,智谱AI推出的AutoGLM Rumination系统,基于强化学习,融合了自反思和迭代优化机制,显著提升了多步推理和复杂函数调用能力。AutoGLM Rumination可自主与网页环境交互、执行代码、调用外部API,完成数据检索、分析和结构化报告生成等复杂任务。与OpenAI DR主要聚焦于复杂推理和信息检索不同,AutoGLM Rumination在实际执行层面展现出更强的自主性,能够将抽象分析转化为具体操作,如自动化网页交互和实时数据处理。此外,AutoGLM Rumination通过与真实浏览器环境无缝集成,突破了模拟浏览环境的局限,实现了对如CNKI、小红书等需用户认证资源的可靠访问,极大提升了智能体在信息获取和实际任务执行中的自主性与适应性。-
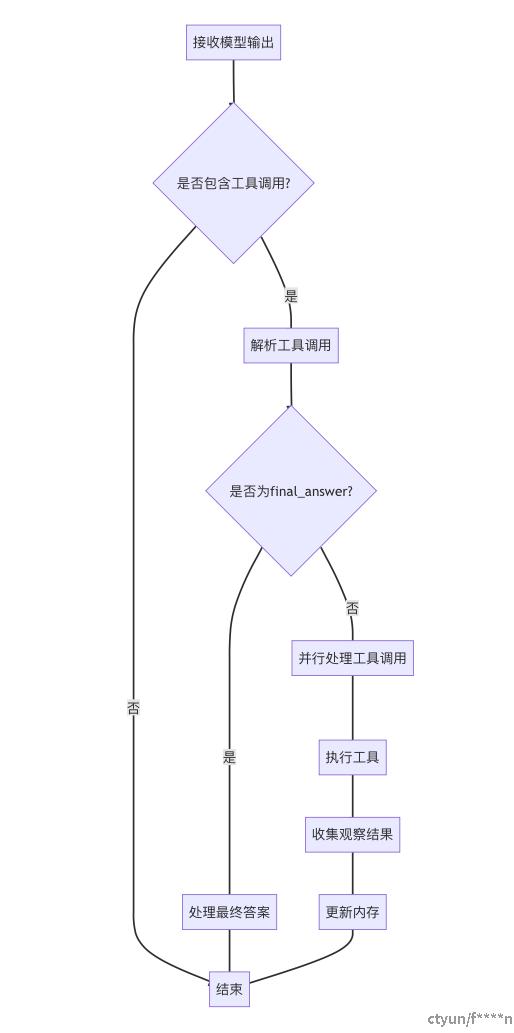
4.3. 架构和工作流
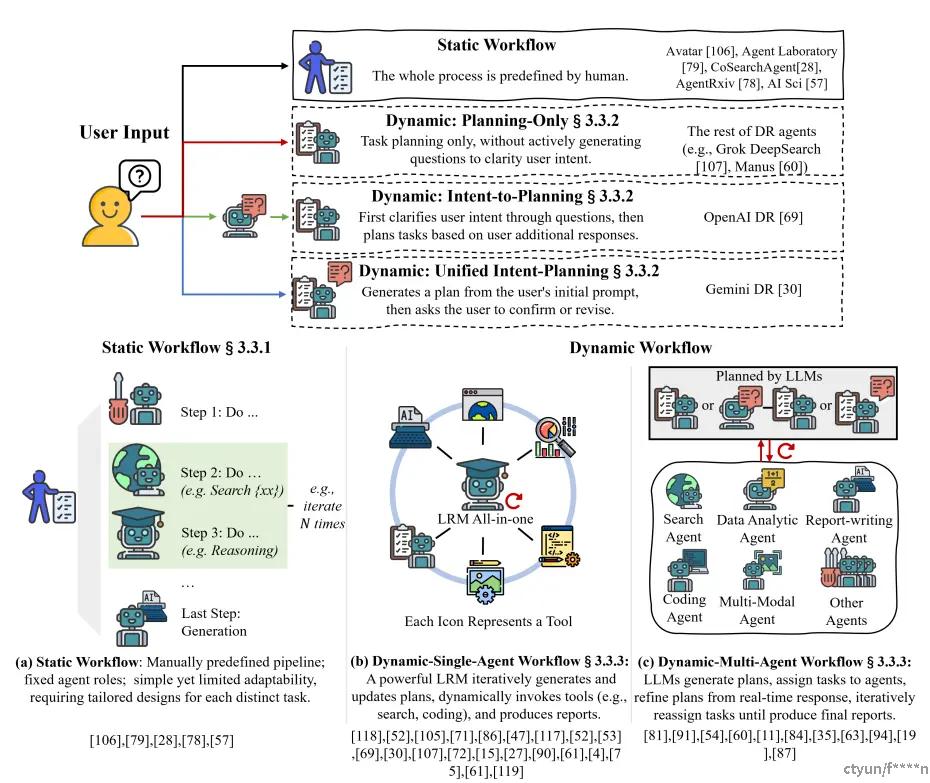
4.3.1. 静态与动态工作流程
- 静态工作流通过手动预定义的任务管道,将研究过程分解为顺序子任务,适合结构化研究场景。例如,AI Scientist 通过构思、实验和报告阶段自动化科学发现;Agent Laboratory 划分文献综述、实验和综合阶段;AgentRxiv 通过代理间协作共享中间结果,实现知识重用。
- 动态工作流支持自适应任务规划,允许代理根据反馈和上下文动态调整任务结构。它利用自动化规划、迭代细化和互动式任务分配,使任务能实时演变,展现出卓越的泛化能力和适应性,非常适合复杂、知识密集型的 AI 研究任务。
4.3.2. 动态工作流:规划策略
为了增强 Deep Research 对演变的用户需求和上下文的适应性,现有研究提出了三种基于 LLM 的规划策略,每种策略在是否以及如何与用户互动以澄清意图方面有所不同:
- Planning-Only:直接根据初始用户提示生成任务计划,而不主动进一步澄清意图,这是大多数现有的 Deep Research 代理所采用的方法,包括 Grok、H2O 和 Manus。
- Intent-to-Planning:意图到规划策略,通过有针对性的问题在规划之前主动澄清用户意图,然后根据用户额外的回应生成量身定制的任务序列;这种方法被 OpenAI Deep Research 所采用。
- Unified Intent-Planning,统一意图规划方法综合了这些方法,从初始提示生成初步计划,并与用户互动以确认或修订提出的计划。Gemini Deep Research 是这种策略的代表,有效地利用了用户引导式细化的优势。
4.3.3. 动态工作流:单代理与多代理
动态工作流的 Deep Research 代理可以根据代理架构分为单代理和多代理框架。
- 动态单代理系统
动态单代理系统将规划、工具调用和执行整合到一个统一的大语言模型中,将任务管理简化为一个连贯的认知循环。单代理架构自主地根据演变的上下文细化任务计划并调用适当的工具,通常无需明确的代理间协调。单代理系统允许在整个工作流上直接进行端到端的强化学习(RL)优化,促进推理、规划和工具调用的更顺畅、更连贯的整合。例如,Agent-R1、ReSearch 和 Search-R1 等系统通过明确推理、行动和反思的迭代循环,与 ReAct 框架一致。
- 动态多代理系统
动态多代理系统利用多个专门代理协作执行由自适应规划策略生成和动态分配的子任务。这些系统通常采用分层或集中式规划机制,其中协调代理根据实时反馈和重新规划持续地分配和重新分配任务。代表性的框架包括 OpenManus 和 Manus,都采用了分层规划者 - 工具调用者架构。
4.3.4. 用于长上下文优化的记忆机制
尽管最近 LLM 的进展显著扩大了上下文窗口大小,但当前的限制仍然限制了涉及极长上下文的任务。为了解决这些挑战,Deep Research 系统实施了各种优化,用于处理扩展上下文。这些优化可以分为以下三种主要策略:(i)扩展上下文窗口长度;(ii)压缩中间步骤;(iii)利用外部结构化存储用于临时结果。
- 扩展上下文窗口长度是最直观有效的办法,以谷歌的 Gemini 模型为例,它支持长达一百万个标记的上下文窗口,并辅以 RAG 设置。尽管这种方法直观有效,但往往会导致高昂的计算成本,并且在实际部署中可能会导致资源利用效率低下。
- 另一种策略是压缩或总结中间推理步骤,显著减少模型处理的标记数量,从而提高效率和输出质量。例如,AI Scientist 和 CycleResearcher 等代表性框架在工作流阶段之间传递总结的中间结果。然而,这种方法的潜在缺点是可能会丢失详细信息,从而影响后续推理的准确性。
- 利用外部结构化存储来保存和检索历史信息,使 Deep Research 代理能够在上下文窗口的限制之外持续且高效地存储大量过去上下文,提高记忆容量、检索速度和语义相关性。流行的开源框架,如 Manus、OWL、Open Manus 和 Avatar,利用外部文件系统存储中间结果和历史数据以便后续检索。WebThinker 和 AutoAgent 等框架开发了自我管理模块,利用向量数据库支持可扩展的记忆存储和基于相似性的快速查找。
4.4. 参数调优:从SFT微调到强化学习
基于Prompt的方法直接利用了预训练大模型的能力,无需昂贵的微调或额外训练即可实现复杂功能。然而,这类方法难以系统性地优化Prompt结构和工作流,并且智能体的性能受限于底层大模型,随着决策复杂度提升,模型能力很快达到瓶颈。为突破这些限制,研究者越来越多地探索如何引入SFT微调、强化学习(RL)或混合训练等高级优化技术,进一步扩展模型的固有能力,系统性地优化大模型在深度研究智能体中的关键组件,如搜索查询生成、结构化报告生成和外部工具调用等,以提升检索质量、减少幻觉、实现更可靠的长文本和证据支撑生成。
