


一. Self-Attention
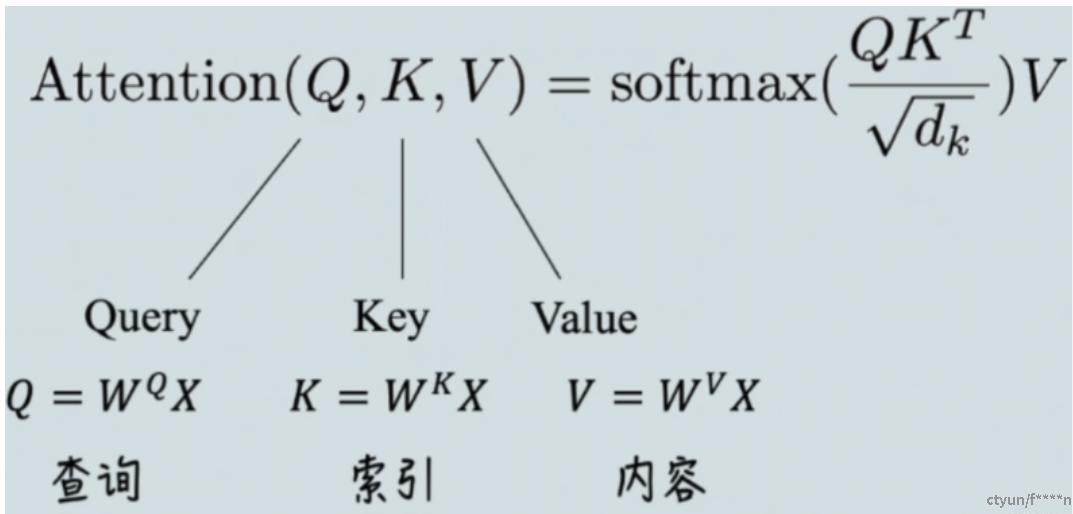
其中,X 表示输入的数据,Q , K , V 对应内容如图,其值都是通过X 和超参(先初始化,后通过训练优化)进行矩阵运算得来的。
1.Self-Attention的计算实例
Step1: 初始化Wq, Wk, Wv 矩阵
假设三种操作的输入都是同等维度的矩阵,这里每个特征维度都是768.即三者的维度:
```plaintext
WQ.shape=[768,768]
WK.shape=[768,768]
WV.shape=[768,768]
```Step2: 定义输入
输入的特征维度也为768,即:每个字用768维来进行表示,如图所示:
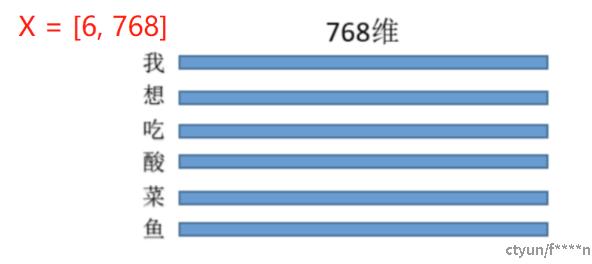
即输入的X的维度为: [6, 768].
Step3: 计算 Q , K , V
由于维度的问题,需要调换以下顺序,以及可能会涉及到转置:
根据以上公式,得到Q , K , V :
Q.shape=[6,768]∗[768,768]=[6,768]
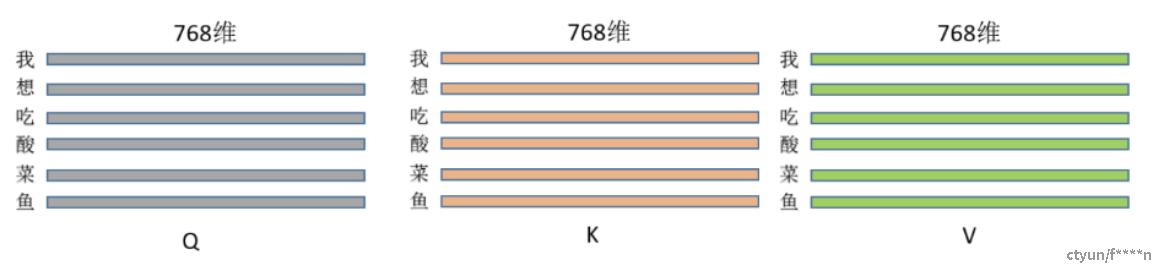
K,V同理。其维度图如下:
Step4: 根据公式计算注意力Attention的分数
First: 是Q ,K 矩阵相乘,维度变化:[ 6 , 768 ] ∗ [ 768 , 6 ] = [ 6 , 6 ]
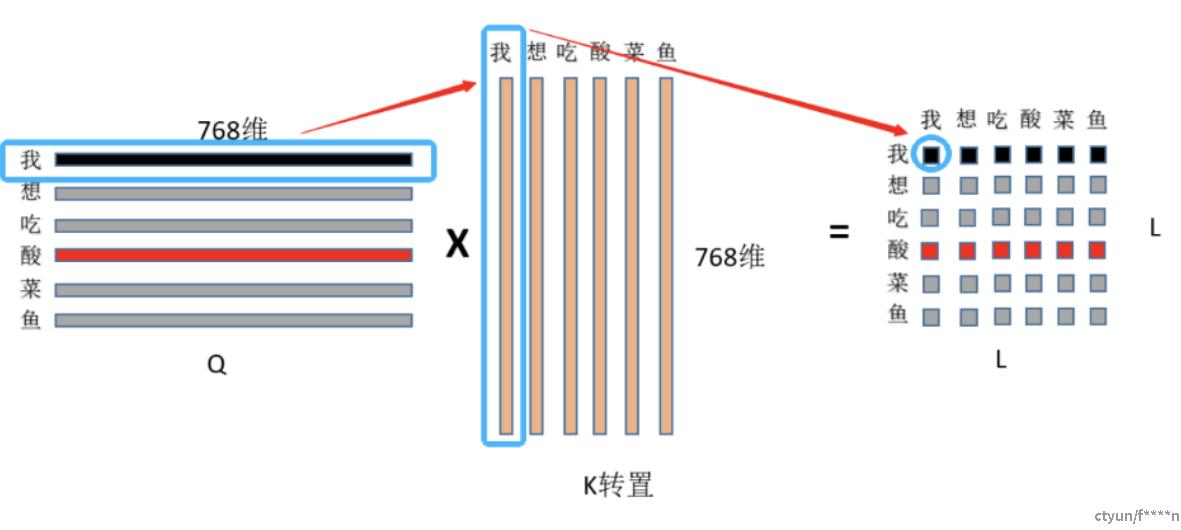
(1)首先用Q的第一行,即“我”字的768特征和K中“我”字的768为特征点乘求和,得到输出(0,0)位置的数值,这个数值就代表了“我想吃酸菜鱼”中“我”字对“我”字的注意力权重;
(2)然后显而易见输出的第一行就是“我”字对“我想吃酸菜鱼”里面每个字的注意力权重;整个结果自然就是“我想吃酸菜鱼”里面每个字对其它字(包括自己)的注意力权重(就是一个数值)了.
Second: 除以 sqrt{dk} ,dk表示特征维度,在本例中d k = 768,之所以要除以这个数,是为了矩阵点乘后的范围,确保softmax的梯度稳定性。
Three: 最后就是注意力权重和V V 矩阵相乘,如图所示:
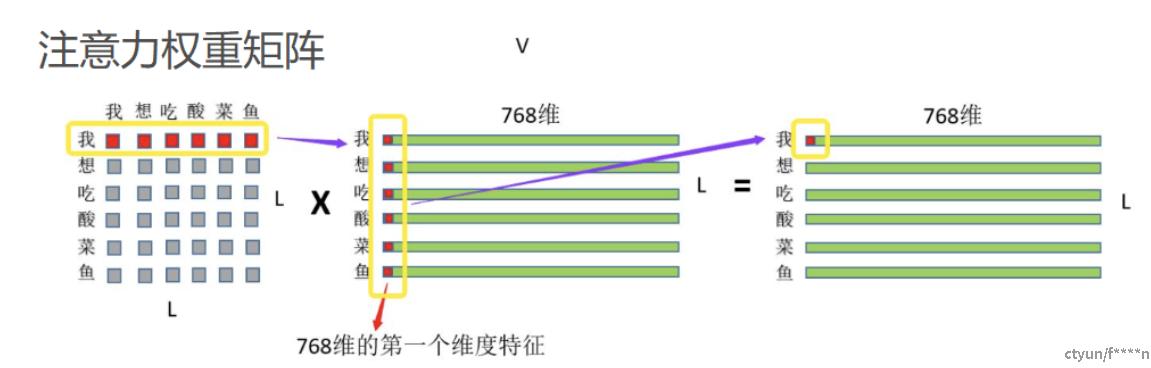
(1)首先是“我”这个字对“我想吃酸菜鱼”这句话里面每个字的注意力权重,和V中“我想吃酸菜鱼”里面每个字的第一维特征进行相乘再求和,这个过程其实就相当于用每个字的权重对每个字的特征进行加权求和,
(2)然后再用“我”这个字对对“我想吃酸菜鱼”这句话里面每个字的注意力权重和V中“我想吃酸菜鱼”里面每个字的第二维特征进行相乘再求和,依次类推最终也就得到了(L,768)的结果矩阵,和输入保持一致。
注意:相当于对V矩阵左乘一个矩阵,任何一个矩阵都是可以进行分解为初等行矩阵相乘。
参考线性变换:https://zhuanlan.zhihu.com/p/108097834
2.关键代码讲解
```plaintext
# 定义 ModelArgs 类
@dataclasses.dataclass
class ModelArgs:
dim: int = 512
n_heads: int = 8
n_kv_heads: Optional[int] = None
max_batch_size: int = 32 # 绑定显存
max_seq_len: int = 2048 # 业务上下文长度需要,小于position-embedding
```
```plaintext
# 复制kv到q维度:GQA
def repeat_kv(x, n_rep):
bz, seqlen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (x[:, :, :, None, :]
.expand(bz, seqlen, n_kv_heads, n_rep, head_dim)
.reshape(bz, seqlen, n_kv_heads*n_rep, head_dim)
)
``````plaintext
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = 1
# 将多头的分配到每一张gpu
self.n_local_heads = args.n_heads//model_parallel_size
self.n_kv_heads = self.n_kv_heads//model_parallel_size
# 假设kv的头和q的头的数量是不一致的,所以需要将kv的头的数量复制到和q的头相同的数量
self.n_rep = self.n_local_heads//self.n_kv_heads
self.head_dim = args.dim//args.n_heads
# [512,512]
self.wq = nn.Linear(args.dim, args.n_heads*self.head_dim, bias=False)
# [512,512]
self.wk = nn.Linear(args.dim, self.n_kv_heads*self.head_dim, bias=False)
# [512,512]
self.wv = nn.Linear(args.dim, self.n_kv_heads*self.head_dim, bias=False)
# [512,512]
self.wo = nn.Linear(args.n_heads*self.head_dim, args.dim)
# [32,2048,8,64]
self.cache_k = torch.zeros(args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim)
# [32,2048,8,64]
self.cache_v = torch.zeros(args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim)
def forward(self, x, start_pos, freqs_cis, mask):
# 1.x->wq,wk、wv-》q、k、v
# 2.q、k、v 【b,seq,dim】-》view ->dim -> head*head_dim(拆多头) ->[b,seq,head*head_dim]
# 3.q、k ->rope-> softmax(q*k^T/dim)*v ->output->wo->outpot->[b,seq,dim】
bz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bz, seqlen, self.n_kv_heads, self.head_dim)
xv = xv.view(bz, seqlen, self.n_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# [32, 2048, 8, 64] k/v[32,100,8,64] [32,1,8,24] start_pos=100 seqlen=1 101
self.cache_k[:bz, start_pos:start_pos+seqlen] = xk
self.cache_v[:bz, start_pos:start_pos+seqlen] = xv
keys = self.cache_k[:bz, :start_pos+seqlen]
values = self.cache_v[:bz, :start_pos + seqlen]
# 分组的时候,都说 kv_heads*n_rep-> n_local_heads
# [b,seq,n_local_head,head_dim] q,k,v
keys = repeat_kv(keys, self.n_rep)
values = repeat_kv(values, self.n_rep)
# transpose(1,2) [b,n_local_head,seq,head_dim] q,k,v
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
# q[b,n_local_head,seq,head_dim] @ k^T [b,n_local_head,head_dim,seq] -》[b,n_local_head,seq,seq]
scores = torch.matmul(xq, keys.transpose(2, 3))/math.sqrt(self.head_dim)
if mask is not None:
scores = scores+mask
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
# scores [b,n_local_head,seq,seq] @ values [b,n_local_head,seq,head_dim] ->[b,n_local_head,seq,head_dim]
output = torch.matmul(scores, values)
# transpose(1,2)->[b,seq,n_local_head,head_dim]->[b,seq,dim】
output = output.transpose(1, 2).contiguous().view(bz, seqlen, -1)
return self.wo(output)
``````plaintext
# 第一次是需要mask
def create_mask(seq_len, n_heads):
mask = torch.triu(torch.ones(seq_len, seq_len),diagonal=1)
mask = mask.masked_fill(mask==1, float('-inf')).masked_fill(mask==0, float(0.0))
mask = mask.repeat(n_heads, 1, 1)
return mask
args = ModelArgs(dim=512, n_heads=8, max_batch_size=32, max_seq_len=200)
attention = Attention(args)
x = torch.randn(1, 50, 512)
# 创建mask
mask = create_mask(50, 8)
mask = mask.unsqueeze(0).expand(1, -1, -1, -1)
# [400,64]
freqs_cis = precompute_freqs_cis(args.dim//args.n_heads, args.max_seq_len*2)
freqs_cis_1 = freqs_cis[:50, :]
# 第一次forward
ouput = attention(x, start_pos=0, freqs_cis=freqs_cis_1, mask=mask)
print(ouput.shape)
# 第二次forward
x_2 = torch.randn(1, 1, 512)
freqs_cis_2 = freqs_cis[50:50+1, :]
output_2 = attention(x_2, start_pos=50, freqs_cis=freqs_cis_2, mask=None)
print(output_2.shape)
```关键点讲解:
- q,k 需要进行旋转位置编码,v不需要旋转位置编码,TP切分针对head维度做,要求head能整除TP
- 第一次forward 需要mask,并保存k,v值,第二次forward不需要mask。
