


一 eBPF是什么及工作流程
eBPF 源于BPF,本质上是处于内核中的一个高效与灵活的虚类虚拟机组件,以一种安全的方式在许多内核 hook 点执行字节码。BPF 最初的目的是用于高效网络报文过滤,经过重新设计,eBPF 不再局限于网络协议栈,已经成为内核顶级的子系统,演进为一个通用执行引擎。开发者可基于 eBPF 开发性能分析工具、软件定义网络、安全等诸多场景。
eBPF 分为用户空间程序和内核程序两部分:
- 用户空间程序负责加载BPF字节码至内核,如需要也会负责读取内核回传的统计信息或者事件详情
- 内核中的BPF字节码负责在内核中执行特性事件,如需要也会将执行的结果通过maps或者perf-event事件发送至用户空间
- 其中,用户空间程序和内核BPF字节码程序可以使用map结果实现双向通信,这为内核中运行的BPF字节码程序提供了更加灵活的控制
用户空间程序与内核中的BPF字节码交互的主要流程如下:
1. 使用LLVM或者GCC工具将编写的BPF代码程序编译成BPF字节码
2. 使用加载程序Loader将字节码加载至内核
3. 内核使用验证器(Verfier)组件保证执行字节码的安全性,以避免对内核造成灾难,在确认字节码安全后将其加载到对应的内核模块执行
4. 内核中运行的BPF字节码程序可以使用两种方式将数据回传至用户空间
1) Maps方式可用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间。
2) perf-event用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析
二 eBPF主要概念术语
1 bpf cmd
系统调用bpf()接口,通过cmd的参数通知内核将要执行的命令,如load prog、create map等。当前系统中支持的cmd列表如下。
enum bpf_cmd {
BPF_MAP_CREATE,
BPF_MAP_LOOKUP_ELEM,
BPF_MAP_UPDATE_ELEM,
BPF_MAP_DELETE_ELEM,
BPF_MAP_GET_NEXT_KEY,
BPF_PROG_LOAD,
BPF_OBJ_PIN,
BPF_OBJ_GET,
BPF_PROG_ATTACH,
BPF_PROG_DETACH,
BPF_PROG_TEST_RUN,
BPF_PROG_GET_NEXT_ID,
BPF_MAP_GET_NEXT_ID,
BPF_PROG_GET_FD_BY_ID,
BPF_MAP_GET_FD_BY_ID,
BPF_OBJ_GET_INFO_BY_FD,
BPF_PROG_QUERY,
BPF_RAW_TRACEPOINT_OPEN,
BPF_BTF_LOAD,
BPF_BTF_GET_FD_BY_ID,
BPF_TASK_FD_QUERY,
BPF_MAP_LOOKUP_AND_DELETE_ELEM,
};2.2 ebpf prog 类型
prog 类型与下面的attach type配合用于不同的场景,如socket_filter/sock_ops等用于过滤和重定向socket数据。随着内核版本更新,会逐步新增类型支持
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
};2.3 bpf attach 类型
通过系统调用bpf()将ebpf prog attach到具体的hook点上,这点有些类似netfilter,在内核不同流程上会有不同的hook点,ebpf程序将相关钩子函数挂载到对应hook点执行。
enum bpf_attach_type {
BPF_CGROUP_INET_INGRESS,
BPF_CGROUP_INET_EGRESS,
BPF_CGROUP_INET_SOCK_CREATE,
BPF_CGROUP_SOCK_OPS,
BPF_SK_SKB_STREAM_PARSER,
BPF_SK_SKB_STREAM_VERDICT,
BPF_CGROUP_DEVICE,
BPF_SK_MSG_VERDICT,
BPF_CGROUP_INET4_BIND,
BPF_CGROUP_INET6_BIND,
BPF_CGROUP_INET4_CONNECT,
BPF_CGROUP_INET6_CONNECT,
BPF_CGROUP_INET4_POST_BIND,
BPF_CGROUP_INET6_POST_BIND,
BPF_CGROUP_UDP4_SENDMSG,
BPF_CGROUP_UDP6_SENDMSG,
BPF_LIRC_MODE2,
BPF_FLOW_DISSECTOR,
BPF_CGROUP_SYSCTL,
BPF_CGROUP_UDP4_RECVMSG = 19,
BPF_CGROUP_UDP6_RECVMSG,
__MAX_BPF_ATTACH_TYPE
};2.4 map类型
BPF Map 是驻留在内核空间中的高效Key/Value store.BPF Map 的交互场景主要有以下几种:
- BPF 程序和用户态程序的交互:BPF 程序运行完,得到的结果存储到 map 中,供用户态程序通过文件描述符访问
- BPF 程序和内核态程序的交互:和 BPF 程序以外的内核程序交互,也可以使用 map 作为中介
- BPF 程序间交互:如果 BPF 程序内部需要用全局变量来交互,但是由于安全原因 BPF 程序不允许访问全局变量,可以使用 map 来充当全局变量
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH,
BPF_MAP_TYPE_ARRAY,
BPF_MAP_TYPE_PROG_ARRAY,
BPF_MAP_TYPE_PERF_EVENT_ARRAY,
BPF_MAP_TYPE_PERCPU_HASH,
BPF_MAP_TYPE_PERCPU_ARRAY,
BPF_MAP_TYPE_STACK_TRACE,
BPF_MAP_TYPE_CGROUP_ARRAY,
BPF_MAP_TYPE_LRU_HASH,
BPF_MAP_TYPE_LRU_PERCPU_HASH,
BPF_MAP_TYPE_LPM_TRIE,
BPF_MAP_TYPE_ARRAY_OF_MAPS,
BPF_MAP_TYPE_HASH_OF_MAPS,
BPF_MAP_TYPE_DEVMAP,
BPF_MAP_TYPE_SOCKMAP,
BPF_MAP_TYPE_CPUMAP,
BPF_MAP_TYPE_XSKMAP,
BPF_MAP_TYPE_SOCKHASH,
BPF_MAP_TYPE_CGROUP_STORAGE,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE,
BPF_MAP_TYPE_QUEUE,
BPF_MAP_TYPE_STACK,
};三 示例分析
下面以一个内核源码selftest中的简单示例,来分析ebpf程序的执行流程和主要组件之间的配合。示例文件tools/testing/selftests/bpf/test_sock.c,为了流程清晰,便于分析,仅保留“bind reject all”case,来分析整个ebpf的加载流程及工作原理。
首先,看一下ebpf具体执行指令信息,该部分大体含义为,创建ebpf钩子函数,attach到BPF_CGROUP_INET4_POST_BIND hook点,然后创建socket(AF_INET, SOCK_STREAM, 0)并bind()到指定地址。
static struct sock_test tests[] = {
{
"bind4 reject all",
.insns = {
BPF_MOV64_IMM(BPF_REG_0, 0),
BPF_EXIT_INSN(),
},
BPF_CGROUP_INET4_POST_BIND,
BPF_CGROUP_INET4_POST_BIND,
AF_INET,
SOCK_STREAM,
"0.0.0.0",
0,
BIND_REJECT,
},
}; 其中。Insns部分,BPF_MOV64_IMM(BPF_REG_0, 0)指令,将寄存器R0置为0,表示bpf函数返回值,在该示例中会导致后面的bind()函数失败。关于ebpf指令说明可参考:eBPF Instruction Set — The Linux Kernel documentation
接下来,看下具体加载过程,该示例涉及到cgroup,需要绑定到对应承担cgroup资源上如下,不过该部分非ebpf核心部件,不重点描述,感兴趣的可以看下源码文件。
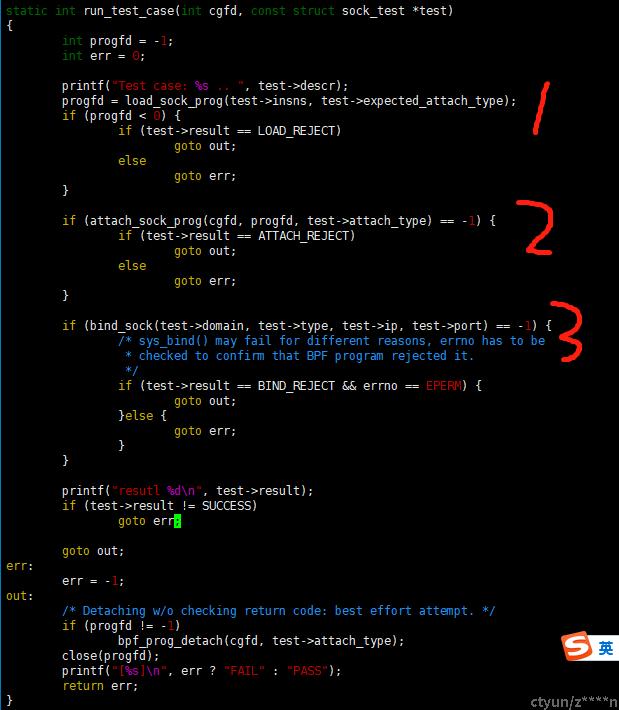
上面为示例核心流程,首先,1处创建prog,通过系统调用bpf(),使用BPF_PROG_LOAD cmd加载内核中去,其次,2处通过系统调用bpf(),使用BPF_PROG_ATTACH cmd将prog attach到BPF_CGROUP_INET4_POST_BIND对应hook点上。最后,3处创建socket,并执行bind()操作,并执行对应hook点的ebpf prog程序,阻断bing()执行。
首先,第一步创建prog
static int load_sock_prog(const struct bpf_insn *prog,
enum bpf_attach_type attach_type)
{
struct bpf_load_program_attr attr;
memset(&attr, 0, sizeof(struct bpf_load_program_attr));
attr.prog_type = BPF_PROG_TYPE_CGROUP_SOCK;
attr.expected_attach_type = attach_type;
attr.insns = prog;
attr.insns_cnt = probe_prog_length(attr.insns);
attr.license = "GPL";
return bpf_load_program_xattr(&attr, bpf_log_buf, BPF_LOG_BUF_SIZE);
}
...
static inline int sys_bpf_prog_load(union bpf_attr *attr, unsigned int size)
{
int fd;
do {
fd = sys_bpf(BPF_PROG_LOAD, attr, size);
} while (fd < 0 && errno == EAGAIN);
return fd;
}用户空间程序,最终通过bpf()系统调用进入内核空间,并通过cmd表示将要执行的操作,使用bpf_attr参数表示prog类型,指令、map等属性信息。
下面是bpf()系统调用接口,通过cmd和bpf_attr执行不同的操作,其中加载bpf程序对应cmd为BPF_PROG_LOAD
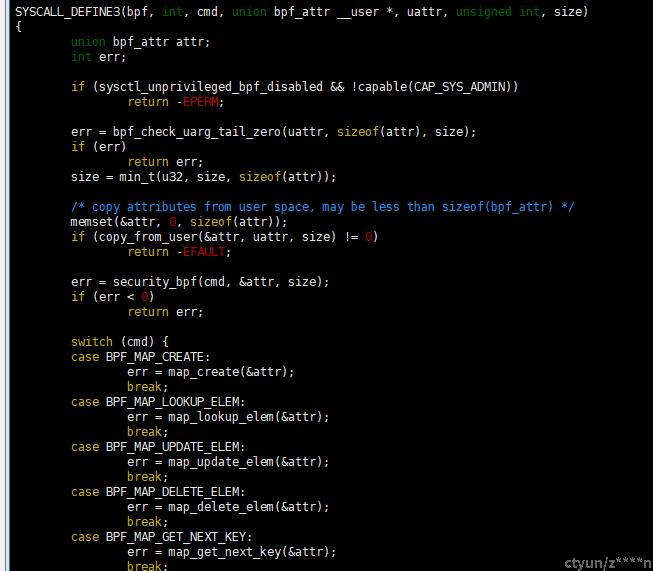
其次,第二步最终通过bpf()系统调用,BPF_PROG_ATTACH 执行将第一步创建的prog attach到对应hook点上。
其中,BPF_CGROUP_INET4_POST_BIND会在__inet_bind()流程中被执行。
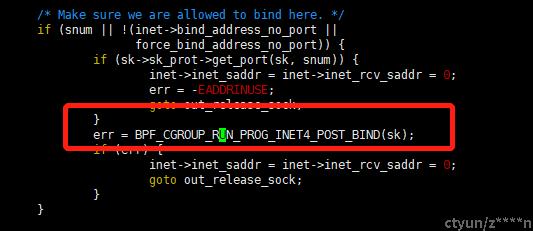
最终,在执行bind()系统调用进入内核后,在对应hook通过遍历相关ebpf钩子列表array,执行对应的过滤操作,如下
int __cgroup_bpf_run_filter_sk(struct sock *sk,
enum bpf_attach_type type)
{
struct cgroup *cgrp = sock_cgroup_ptr(&sk->sk_cgrp_data);
int ret;
ret = BPF_PROG_RUN_ARRAY(cgrp->bpf.effective[type], sk, BPF_PROG_RUN);
return ret == 1 ? 0 : -EPERM;
}
EXPORT_SYMBOL(__cgroup_bpf_run_filter_sk);
...
#define __BPF_PROG_RUN_ARRAY(array, ctx, func, check_non_null) \
({ \
struct bpf_prog_array_item *_item; \
struct bpf_prog *_prog; \
struct bpf_prog_array *_array; \
u32 _ret = 1; \
preempt_disable(); \
rcu_read_lock(); \
_array = rcu_dereference(array); \
if (unlikely(check_non_null && !_array))\
goto _out; \
_item = &_array->items[0]; \
while ((_prog = READ_ONCE(_item->prog))) { \
bpf_cgroup_storage_set(_item->cgroup_storage); \
_ret &= func(_prog, ctx); \
_item++; \
} \
_out: \
rcu_read_unlock(); \
preempt_enable(); \
_ret; \
})
#define BPF_PROG_RUN_ARRAY(array, ctx, func) \
__BPF_PROG_RUN_ARRAY(array, ctx, func, false)