


前言
设计一种写入框架实现类似于logstash般可配置化消费kfk数据到异构数据源(clickhouse),同时能实现数据的去重。相当于是做了一个java去重版本的cksinker。其他整体流程不变
架构

系统流程设计
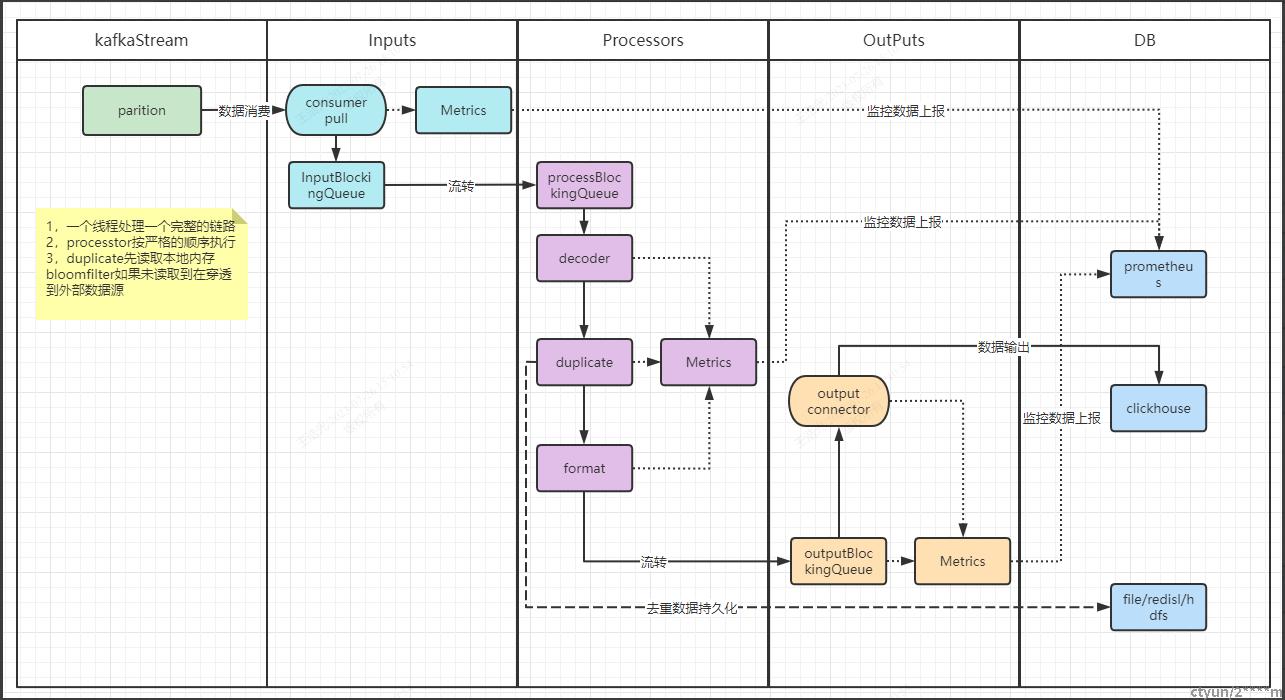
注意:
1,只做消费kafka写clickhouse功能。
2,process只做去重功能。
3,数据一致性只能保证,至少一次。
4,当前版本只实现了数据快照到本地文件的功能,当前服务只能支持单进程去重一致性,因此可能存在单节点问题,如果需要多节点多进程只能将Bloomfilter放到远程(redis:rebloom,其他的第三方存储考察来看暂时都不行),且要免快照化才能实现去重bloomfilter数据的一致性。
5,由于bloomfilter存在误判,在判断存在的情况下可能是错误的,但是判断不存在的情况下,肯定是不存在的,那这样可能会导致数据丢失,所以一定要控制好错误比例,如果后期出现确实大量的数据丢失,那只能改下bitmap位图的形式了,或者(Roaringbitmaps更好的压缩性能),不过要花费大量的内存成本,以及极大降低系统的稳定性。不过也可以考虑类似于logstash那样的死队列的思路。
配置参数说明
{
"job": {
"setting": {
"channel": 10,
"data.dir":"/ssd1/services/jchsinker",
"keep.alive.timeout.mspoll.duration.ms":1000,
"name":"jchsinker_demo1"
},
"content": {
"inputs": [{
"name": "kafkareader",
"parameter": {
"bootstrap.servers": "host:6667",
"topic": "test-topic-in",
"codec": "json",
"auto.offset.reset": "earliest",
"value.deserializer": "org.apache.kafka.common.serialization.StringDeserializer",
"key.deserializer": "org.apache.kafka.common.serialization.StringDeserializer",
"poll.interval.ms": "5000",
"max.poll.records":1000,
"group.id": "chpipeline_groupid_001",
"security.protocol": "SASL_PLAINTEXT",
"sasl.mechanism": "PLAIN",
"sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"xxxx\" password=\"xxxx\";",
"table": {
"name": "kfk_demo_view",
"column": [{
"alias": "beginTime",
"name": "BeginTime"
},
{
"alias": "endTime",
"name": "EndTime"
},
{
"alias": "chargingItem",
"name": "ChargingItem"
},
{
"alias": "chargingUnit",
"name": "ChargingUnit"
},
{
"alias": "chargingValue",
"name": "ChargingValue"
},
{
"alias": "inValue",
"name": "InValue"
},
{
"alias": "outValue",
"name": "OutValue"
},
{
"alias": "model",
"name": "Model"
},
{
"alias": "nodeCode",
"name": "NodeCode"
},
{
"alias": "recordType",
"name": "RecordType"
},
{
"alias": "resourceId",
"name": "ResourceId"
},
{
"alias": "resourceType",
"name": "ResourceType"
},
{
"alias": "userId",
"name": "UserId"
}
]
}
}
}],
"processors": [{
"name": "memduplicate",
"enable": true,
"parameter": {
"duplicate.key": [
"resourceId",
"userId",
"chargingItem",
"beginTime"
],
"engine": {
"name": "bloomfilter",
"time.column": "beginTime",
"time.data.type": "string_t",
"time.format":"yyyy-MM-dd HH:mm:ss",
"cardinality": 1000000,
"fpp": 0.01,
"instances": 200,
"cache.day": 1,
"snapshot.interval.ms":60
},
"data.source": {
"type": "file"
}
}
}],
"outputs": [{
"name": "clickhousewriter",
"parameter": {
"batch.size": 10000,
"flush.interval": 3000,
"connection": {
"jdbc.url": "jdbc:clickhouse://ip:port/test_db",
"table": "test_table_all"
},
"retry.times": 3,
"username": "xxxx",
"password": "xxxx"
}
}],
"metrics": [{
"Prometheus": {
"host": "127.0.0.1",
"interval": "5 SECONDS",
"class": "cn.chinatelecom.jchsinker.metrics.promethues.PrometheusReporter",
"port": "29091"
}
}]
}
}
}
参数详解
参数 |
类型 |
必须? |
默认值 |
描述 |
|---|---|---|---|---|
| job.setting.channel | int | 否 | 5 | 并发线程数,注意:必须和kafka的topic分区数一致,否则会出现消费丢失获得线程空闲 |
| job.setting.data.dir | string | 否 | /soft/jchsinker/ | 数据缓存目录,比如bloomfilter快照文件,task状态文件register.json,如果是docker或者k8s部署,切记需要配置然后挂载到本机文件目录上,否则会出现进程重启或者奔溃后数据丢失或者去重失效。 |
| job.setting.keep.alive.timeout.ms | int | 否 | 5000 | 单位ms,系统在关闭后,进程继续存活最大时间 |
| job.setting.name | string | 否 | jchsinker | 任务名 |
| job.setting.max.queue.size | int | 否 | 50000 | 阻塞队列长度 |
| job.content.inputs.name | string | 是 | 消费名,当前为kafka | |
| job.content.inputs.parameter.bootstrap.servers | string | 是 | kafka 服务器地址 | |
| job.content.inputs.parameter.topic | string | 是 | kafka topic | |
| job.content.inputs.parameter.auto.offset.reset | string | 否 | earliest | groupid 第一次默认消费位置 |
| job.content.inputs.parameter.value.deserializer | string | 否 | ....StringDeserializer | |
| job.content.inputs.parameter.key.deserializer | string | 否 | ....StringDeserializer | |
|
job.content.inputs.parameter.poll.duration.ms |
int | 否 |
1000
|
kafka consumer两次poll的最大时间间隔 |
| job.content.inputs.parameter.max.poll.records | int | 否 |
1000
|
kafka consumer每次消费最大条数 |
| job.content.inputs.parameter.group.id | string | 是 | kafka group id | |
| job.content.inputs.parameter.security.protocol | string | 否 | SASL_PLAINTEXT | |
| job.content.inputs.parameter.sasl.mechanism | string | 否 | PLAIN | |
| job.content.inputs.parameter.sasl.jaas.config | string | 否 |
org.apache.kafka.common.security.plain.PlainLoginModule required username=\"xxxx\" password=\"xxxx\"; kafka sasl鉴权验证 |
|
| job.content.inputs.parameter.table.name | string | 是 | kafka中的数据的虚拟表 | |
| job.content.inputs.parameter.table.column.alias | string | 是 | kafka中的数据的虚拟表字段别名,注意:别名为输出到下游的字段名 | |
| job.content.inputs.parameter.table.column.name | string | 是 | kafka中的数据的虚拟表字段名 | |
| job.content.processors.name | string | 是 | 数据处理器名 | |
| job.content.processors.enable | boolean | 是 | true | 是否开启数据处理器 |
| job.content.processors.parameter.duplicate.key | list | 是 | 去重的字段,可以选多个,使用逗号分割 | |
| job.content.processors.parameter.engine.name | string | 是 | bloomfilter | 去重插件名,当前只支持本地 bloomfilter,后期支持redis |
| job.content.processors.parameter.engine.time.column | string | 是 | bloomfilter时间缓存字段,在事件数据中取一个时间字段,去重bloomfilter因为不能一直增加,所以需要按事件中的一个时间字段来过期删除bloomfilter,bloomfilter占用内存大小计算工具:https://krisives.github.io/bloom-calculator/ | |
| job.content.processors.parameter.engine.time.data.type | string | 否 | string_t | 时间字段类型,可以支持 string_t 字符串,比如:2021-11-02 17:13:32,int_t 10位时间戳,long_t 13位时间戳 |
| job.content.processors.parameter.engine.time.format | string | 是 | 如果time.data.type为string_t,必须指定时间格式 | |
| job.content.processors.parameter.engine.cardinality | long | 否 | 1000000 | bloomfilter基数 ,这个值越大,内存磁盘资源也就越大,bloomfilter占用内存大小计算工具:https://krisives.github.io/bloom-calculator/ |
| job.content.processors.parameter.engine.fpp | double | 否 | 0.01 | bloomfilter容错因子 |
| job.content.processors.parameter.engine.instances | int | 否 | 100 | bloomfilter缓存最大个数 |
| job.content.processors.parameter.engine.cache.day | int | 否 | 1 | 缓存bloomfilter最大时间,单位天,这个数据越大,快照时间和服务重启和停止时间也就越长,注意:需要计算下instances之间的关系,bloomfilter为每小时缓存一个,一天24个 |
| job.content.processors.parameter.engine.snapshot.interval.ms | int | 否 | 300000 | bloomfilter定时快照时间,单位ms,单位ms,不能小于60000,否则强制为60000,为了保证服务重启,过滤器不丢失过滤数据 |
| job.content.processors.parameter.data.source.type | string | 否 | file | bloomfilter快照输出数据源,当前只支持文件,后期支持多节点的话,可以支持hdfs,redis |
| job.content.outputs.name | string | 是 | 输出数据源,当前只支持clickhousewriter | |
| job.content.outputs.parameter.batch.size | int | 否 | 1000 | 每批次写入clickhouse大小,数值越大,延时越大。 |
| job.content.outputs.parameter.flush.interval.ms | int | 否 | 1000 | 每批次最大等待时间,单位ms,不能小于1000,否则强制为1000,数据越少在数据量不大的情况下,延时越低。注意需要平衡好batch.size和flush.interval的关系,平衡延时和性能,类似于kafka的批量操作 |
| job.content.outputs.parameter.connection.jdbc.url | string | 是 |
clickhouse集群的jdbc.url,例如jdbc:clickhouse://127.0.0.1:8123/test_db 注意只能用clickhouse的http端口 |
|
| job.content.outputs.parameter.connection.table | string | 是 | 数据写入目标表,当前只支持写分布式表 | |
| job.content.outputs.parameter.retry.times | int | 否 | 3 | 写clickhouse,失败重试次数 |
| job.content.outputs.parameter.username | string | 是 | clickhouse访问账号 | |
| job.content.outputs.parameter.password | string | 是 | clickhouse访问密码 | |
| job.content.metrics.Prometheus.host | string | 是 | Prometheus数据上报IP | |
| job.content.metrics.Prometheus.interval | int | 是 | Prometheus数据收集时间间隔 | |
| job.content.metrics.Prometheus.class | string | 是 | 当前只能为cn.chinatelecom.jchsinker.metrics.promethues.PrometheusReporter使用pull方式 | |
| job.content.metrics.Prometheus.port | int | 是 |
9249
|
Prometheus pull方式对外服务端口 |
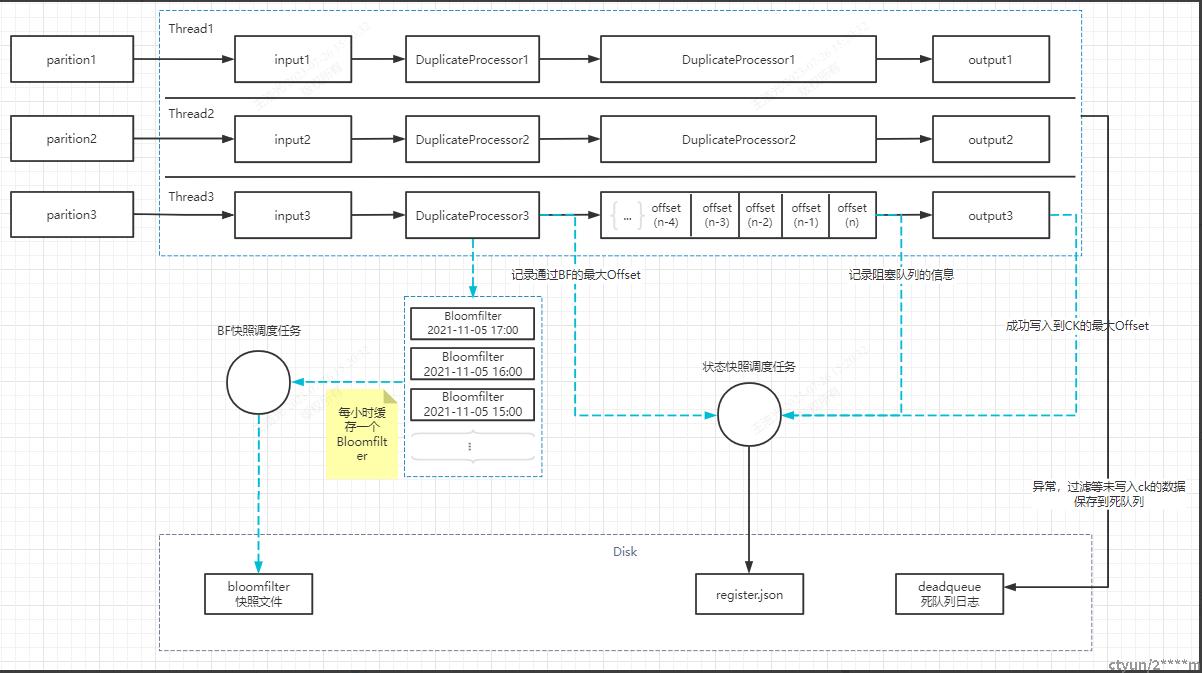
数据完整性保证
数据的完整性主要分量种exactly-once(精确一次语义)和at-least-once(至少一次语义)。
完整性消费架构
去重逻辑处理细节
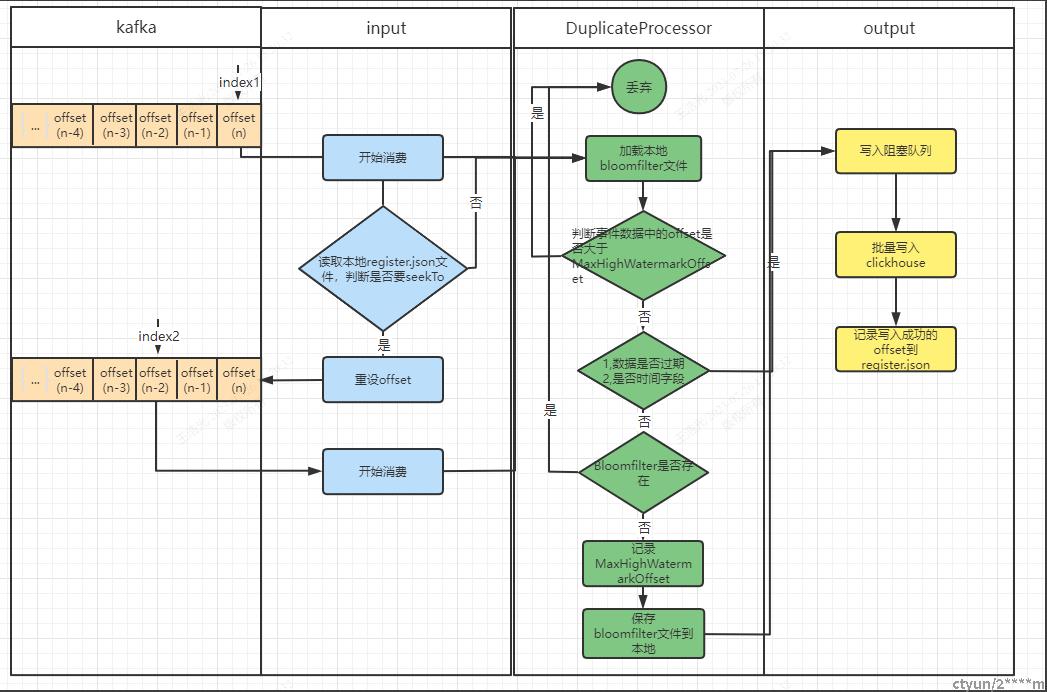
消费快照文件
register.json
{
##记录成功写入到clickhouse数据库的offset
"consumedOffset": {
"demo1-in#0": 546983,
"demo1-in#9": 543723,
"demo1-in#6": 544547,
"demo1-in#5": 544166,
"demo1-in#8": 541308,
"demo1-in#7": 545393,
"demo1-in#2": 541287,
"demo1-in#1": 545401,
"demo1-in#4": 544586,
"demo1-in#3": 543736
},
##更新时间
"updateTime": 1636106394830,
##队列中余留的数据长度
"outputBatchQueueRemain": {
"3#": 60,
"2#": 69,
"1#": 29,
"0#": 32,
"9#": 62,
"8#": 22,
"7#": 22,
"6#": 64,
"5#": 41,
"4#": 29
},
##去重任务去重后的最大offset
"dumpHighWatermarkOffset": {
"0#": 547014,
"9#": 543784,
"5#": 544206,
"6#": 544610,
"7#": 545414,
"8#": 541329,
"1#": 545429,
"2#": 541355,
"3#": 543795,
"4#": 544614
}
}
数据完整性监控
curl ip:port/metrics
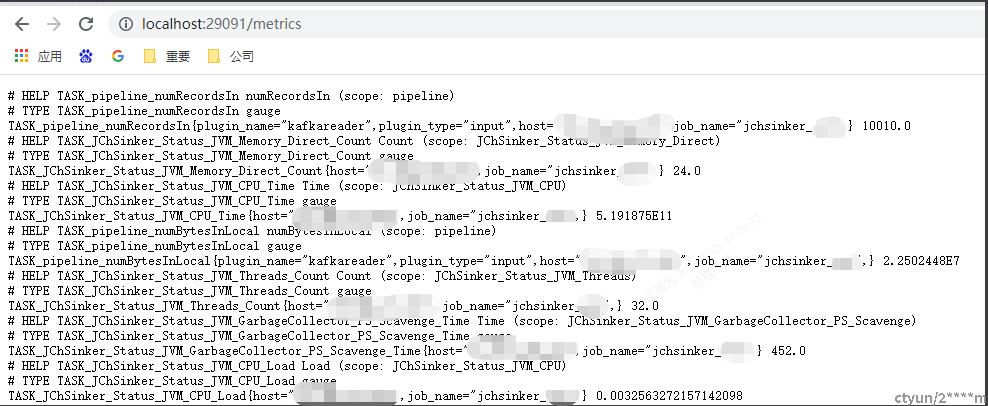
输入数据量:TASK_pipeline_numRecordsIn
输出数据量:TASK_pipeline_numRecordsOut
判断两个数据是否相等。
完整性保障流程
为保证整个流程数据的完整性
0,数据消费一个线程处理一个kafka 分区,kafka offset消费单调递增。
1,定时记录快照文件,包括bloomfilter文件信息,不同任务的状态信息register.json。
2,在进程奔溃的时候同样需要记录状态信息到本地。
3,在进程重启或者奔溃的情况下,需要按记录的状态文件(register.json)做replay。
