


前言
现需要实现一个数据加工的DSL(domain-specific language 领域特定语言),不需要对DSL过多理解,你可以类比SQL语言即可。现使用JavaCC这个工具来生成一个词法和语法解析器,注意是代码生成器,所以才叫CC(Compiler Compiler编译器的编译器)。
技术理念
DSL
domain-specific language 领域特定语言,最典型的就是SQL,还有比如lucene Query Parser Syntax,promQL等。DSL主要分为两类。
内部DSL)内嵌到现有的编程语言(java,c,python)上。比如lucene,PromQL等。
外部DSL)拥有自己一套完整的词法分析,语法分析,编译,代码生成等一整套完整的体系的独立语言,比如JSON,正则,XML,markdown等。
javaCC
想个很简单的问题,计算机如何识别你表达的语言在按你的语言去执行相应的逻辑?这就是编译原理,将你的输入的内容也叫代码语言通过词法语法分析、语法翻译、中间代码生成、存储管理、代码优化和目标代码等过程翻译成计算机能识别的代码。那么同理DSL也需要一个这样的过程。业内有很多优秀的中间件的词法和语法解析器代码生成器都是javaCC。比如lucene QueryParser.jj,Calcite parser.jj,JsqlParser JSqlParserCC.jjt等,更多可以直接看官网。
编译器原理
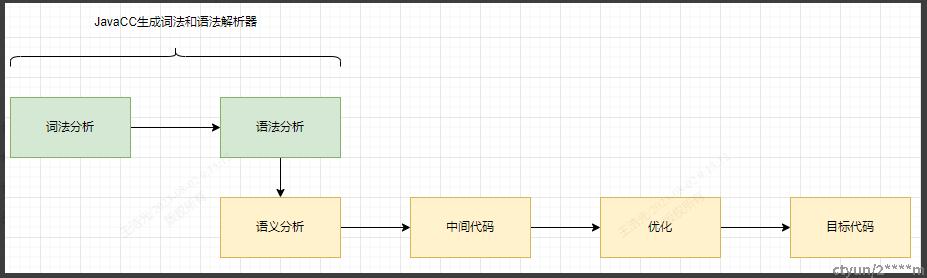
模块说明
词法分析:将输入的文本代码解析生成Token流,也叫扫描器。
语法分析:利用词法分析生成的Token流转成AST(抽象语法树),也叫解析器。
语义分析:分析语法树,得到新的语法树。
中间代码:分析语法树,生成中间代码。
而JavaCC则主要担当生成词法分析器和语法分析器。
javaCC解析器原理
javaCC的工作即为生成词法分析器(lexical analyzer)和语法分析器(parser generators)的工具。真正对文本代码分析的流程入图。

一些信息
1,javaCC 使用自顶向下(top-down)递归下降(recursive descent)解析。
2,默认是LL(1)文法用于预测性解析,不过在使用 LOOKAHEAD(n) 的时候为LL(k),主要为了消除歧义,而在其他情况下均为LL(1),这样能减少递归回溯。至于啥是LL(k)算法,去看编译原理吧,我也看得一知半解。
3,javaCC词法分析器使用正则或字符串定义,语法解析器定义使用EBNF(扩展巴科斯范式)语法,使用EBNF可以减少左递归的影响且更加易读,词法分析器和语法分析器使用同一个文件定义。
4,javaCC提供了自带的JJTree,非常方便直接生成AST树。
本地环境安装
安装官方参考文档。官方使用的是linux安装,我这边使用的是win本地开发。
1,下载安装包(javacc-7.0.10.tar.gz),下载地址。
2,解压到相应的目录并配置环境变量
#解压安装路径
F:\soft3\javacc-javacc-7.0.10
#环境变量
JAVACC_HOME : F:\soft3\javacc-javacc-7.0.10\scripts
#配置path
%JAVACC_HOME%
3,需要特别注意的是,需要在安装目录的根目录下创建一个target文件夹,然后将bootstrap文件夹中的javacc.jar拷贝过去,否则会报错。

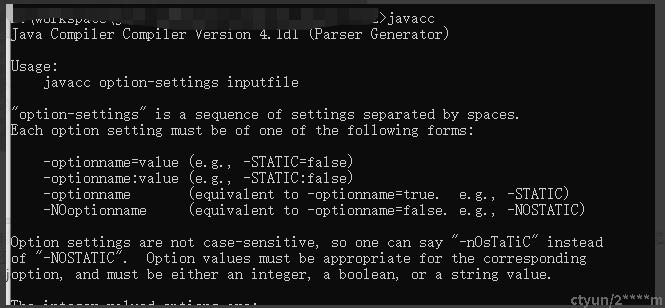
4,检查是否安装成功
打开cmd,输入javacc,出现如下信息则表示安装成功。
写个Demo
在开始开发javacc的解释器前,需要了解一些基本知识,否则会非常绕不方便理解,我这边的例子参考官方给的javacc-tutorial(个人感觉是写的最清楚的英文也比较简单,网上写的都让人云里雾里,不过可惜的是一些图表信息不完整,jjtree说的也不详细,不过对于我们入门学习还是非常足够了)。
BNF语法
::= //翻译成人话就是:“定义为”, ::== 符号表示为 “可扩展为” 或 “可替换为”, “可定义为”.
<A> //A为必选项
“A” //A是一个术语,不用翻译
'A' //A是一个术语,不用翻译
[A] //A是可选项
{A} //A是重复项,可出现任意次数,包括0次
A* //A是重复项,可出现任意次数,包括0次
A+ //A可出现1次或多次
(A B) //A和B被组合在一起
A|B //A、B是并列选项,只能选一个javaCC xx.jj文件模板
options {
JavaCC 的选项
}
PARSER_BEGIN(解析器类名)
package 包名
import 库名
public class 解析器类名 {
任意的 Java 代码
}
PARSER_END(解析器类名)
扫描器的描述
解析器的描述一些说明
1,options部分,用于放置 JavaCC 的选项。常用选项见下文中的 JavaCC 语法描述文件中的 options。
2,PARSER_BEGIN、PARSER_END部分,用于定义解析器类。解析器类中需要定义的成员和方法都写在这里。
3,扫描器的描述部分,用于定义扫描器。
4,解析器的描述部分,用于定义解析器。
生成词法和语法解析器文件说明
XXConstants: 定义一些常量值,比如将TOKEN定义的值转换为一个个的数字;
XXParserTokenManager: token管理器, 用于读取token, 可以自定义处理;
JavaCharStream: CharStream的实现,会根据配置选项生成不同的类;
ParseException: 解析错误时抛出的类;
Token: 读取到的单词描述类;
TokenMgrError: 读取token错误时抛出的错误;xx.jj 一些关键字
TOKEN /* 定义一些确定的普通词或关键词,主要用于被引用 */
SPECIAL_TOKEN /* 定义一些确定的特殊用途的普通词或关键词,主要用于被引用或抛弃 */
SKIP /* 定义一些需要跳过或者忽略的单词或短语,主要用于分词或者注释 */
MORE /* token的辅助定义工具,用于确定连续的多个token */
EOF /* 文件结束标识或者语句结束标识 */
IGNORE_CASE /* 辅助选项,忽略大小写 */
JAVACODE /* 辅助选项,用于标识本段代码是java */
LOOKAHEAD /* 语法二义性处理工具,用于预读多个token,以便明确语义 */
PARSER_BEGIN /* 样板代码,固定开头 */
PARSER_END /* 样板代码,固定结尾 */
TOKEN_MGR_DECLS /* 辅助选项 */实现javacc-tutorial中的计算器例子
1,编写calculator0.jj文件
# javacc全局配置,更多的options可以查看https://javacc.github.io/javacc/documentation/grammar.html#options
options {
STATIC = false ;
}
# 开始java代码块,内部的实现主要是实现main函数,完成解析的调用和执行
PARSER_BEGIN(Calculator)
public class Calculator {
static public void main(String[] args) throws ParseException, TokenMgrError, NumberFormatException {
Calculator parser = new Calculator(System.in);
parser.Start(System.out) ;
}
double previousValue = 0.0 ;
}
# java块结束
PARSER_END(Calculator)
# 词语解析器开始,使用正则表达式定义
## SKIP 表示忽略那些字符的扫描
SKIP : { " " }
## 表示扫描的结束符
TOKEN : { < EOL : "\n" | "\r" | "\r\n" > }
## 加减乘除关键词定义
TOKEN : { < PLUS : "+" > }
TOKEN : { < MINUS : "-" > }
TOKEN : { < TIMES : "*" > }
TOKEN : { < DIVIDE : "/" > }
## 读取值
TOKEN : { < PREVIOUS : "$" > }
## 数值定义,包括整形和浮点数,注意使用DIGITS替换整个(["0"-"9"])+的重复定义,增加可读性,减少重复部分。
TOKEN : { < NUMBER : <DIGITS> | <DIGITS> "." <DIGITS> | <DIGITS> "." | "."<DIGITS> > }
## 数值定义,由于被其他Token定义引用,因此名称使用#表示
TOKEN : { < #DIGITS : (["0"-"9"])+ > }
## 左右括号
TOKEN : { < OPEN_PAR : "(" > }
TOKEN : { < CLOSE_PAR : ")" > }
# 解析器开始函数,内部实现为计算表达式结果后,控制台打印结果。
void Start(PrintStream printStream) throws NumberFormatException :
{}
{
(
previousValue = Expression()
<EOL>
{ printStream.println( previousValue ); }
)*
<EOF>
}
# 表达式解析,可以看到函数基本上和java语法差不多,不过函数内部实现为EBNF语法,这样看起来比较麻烦,可以可以一层一层看下去,Primary()将Token.image返回扫描到表达式中数值转换成double返回,Term()控制乘法和除法优先级, Expression()计算整个表达式的结果。
# 这样函数看起来不够清晰,我举一个简单的例子 <NUMBER>(<PLUS><NUMBER>)*<EOF> 这明显就是一个EBNF表达式,表示第一个字符串必须为数值,而()中表示连接,第二个字符必须为加号,第三个必须为数值,然后*表示0到无数次。而抽出多个函数,主要是为了可读性和优先级以及特殊# # 处理。
double Expression() throws NumberFormatException :
{
double i ;
double value ;
}
{
value = Term()
(
<PLUS>
i = Term()
### 大括号中的表示动作
{ value += i ; }
|
<MINUS>
i = Term()
{ value -= i ; }
)*
{ return value ; }
}
#对乘法和除法优先级处理
double Term() throws NumberFormatException :
{
double i ;
double value ;
}
{
value = Primary()
(
<TIMES>
i = Primary()
{ value *= i ; }
|
<DIVIDE>
i = Primary()
{ value /= i ; }
)*
{ return value ; }
}
#如果是数值,直接解析为Double数据,如果为$则返回计算值,如果使用()括号包括则递归调用计算表达式,如果第一个字符为-负号,则取负值。
double Primary() throws NumberFormatException :
{
Token t ;
double d ;
}
{
t=<NUMBER>
{ return Double.parseDouble( t.image ) ; }
|
<PREVIOUS>
{ return previousValue ; }
|
<OPEN_PAR> d=Expression() <CLOSE_PAR>
{ return d ; }
|
<MINUS> d=Primary()
{ return -d ; }
}
2,生成词法和语法解析器
#进入项目
cd ..\calculator2
#执行
javacc calculator0.jj
看到如此信息则表示创建词法和语法解析成功。
3,编译java文件
javac *.java
4,创建表达式文件input.txt,注意要有一个换行的结束符。
5,执行结果
java Calculator <input.txt
总结
1,javaCC是java语言中最强大且使用最广的词法和语法解析器代码生成器。
2,当前demo代码是直接在xx.jj解析器动作中直接计算的,通常情况下一般不会这样,而是先试用jjtree转换成AST抽象语法树后再做后续的逻辑。
3,javaCC主要是生成词法和语法解析器,将文本代码转换成计算机可读可理解的AST抽象语法树。
4,javacc使用正则表达式描述词法规则,使用EBNF表示法描述语法规则。
5,javaCC相对而言还是比较复杂,尤其是语法解析那部分,还有后期的AST树遍历处理,后期简绍下Antlr4。
