


查询处理器流程
-
查询处理器分为查询编译和查询执行两个阶段,每个阶段的主要任务和流程如图所示(图片来源《PostgreSQL数据库内核分析》):
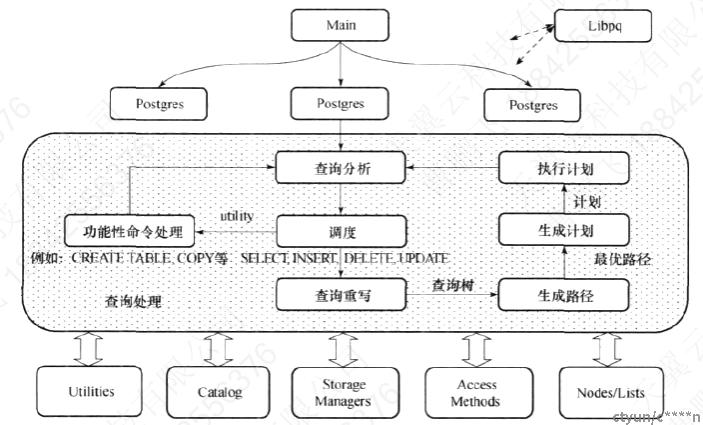
- 服务进程Postgres 在接收到用户发送的SQL语句后,首先交由查询重写模块,进行词法、语法和语义分析,简单的创建表等命令交由功能性命令处理模块完成。对于SELECT/UPDATE/DELETE等语句,为其构建查询树,再由查询重写模块生成新的查询树。生成路径模块采用动态规划算法或者遗传算法生成最优的表连接路径。在借助最优路径生成可执行的计划,并将其传递到执行模块进行执行,本文重点关注执行模块的执行流程。
查询执行器框架
-
下图展示了查询执行器的框架结构(图片来源《PostgreSQL数据库内核分析》),PostgreSQL 中将 SQL 语句分为两种类型,一种是包括创建表以及游标相关操作的数据定义语句,交由下图中的功能处理器模块(ProcessUtility)处理。
-
另一种是主要为 DML 的可优化语句,经过查询编译模块后会生成执行计划树,然后交由上图中的执行器模块(Executor)处理。

实际执行过程观察
执行计划
-
-
设计一条 SQL 语句,配合 GDB 调试,即从 Portal CreatePortal(const char *name, bool allowDup, bool dupSilent) 开始,观察函数的调用流程,以及重要的变量内容,通过这种方式了解整个执行器的框架以及执行流程。
-
数据库环境
-
-
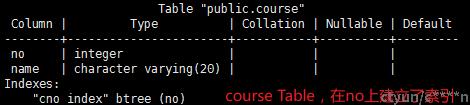
课程表,包含课程 ID 以及 课程名称信息
-
-
-
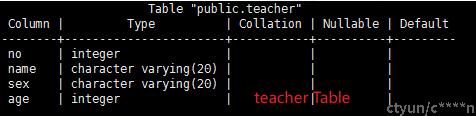
教师表,包含教师ID、姓名、性别以及年龄
-
-
-
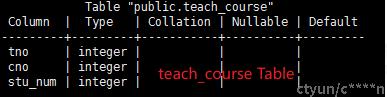
教师-课程信息表,包含课程ID、教师ID以及选课人数
-
-
-
每张表都使用脚本插入包含10W 条随机生成的数据
-
执行的SQL语句
-
-
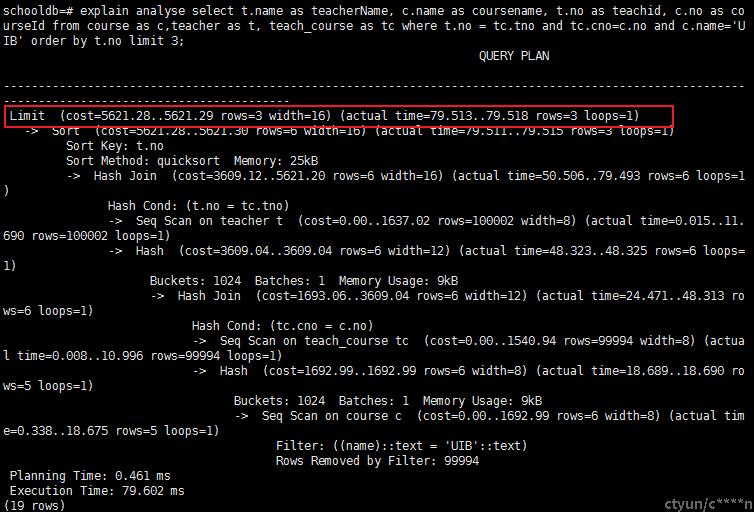
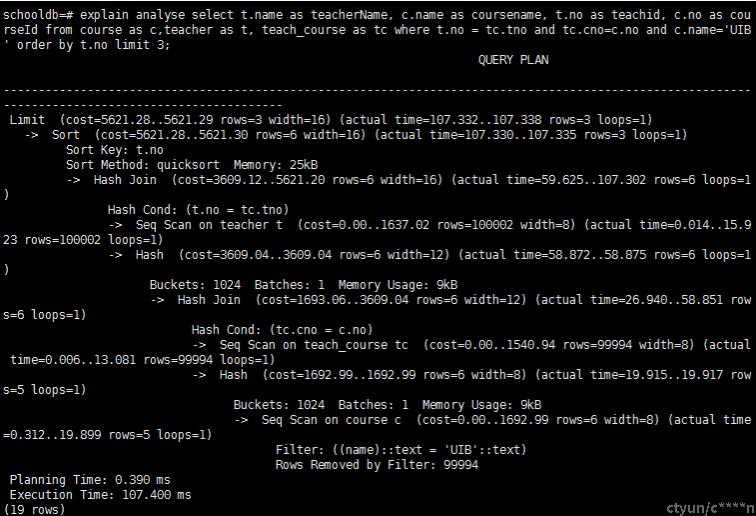
select t.name as teacherName, c.name as coursename, t.no as teachid, c.no as courseId from course as c,teacher as t, teach_course as tc where t.no = tc.tno and tc.cno=c.no and c.name='UIB' order by t.no limit 3;(选择教授课程 ‘UIB' 的教师信息,按照教师ID排序,取前三)
-
调试过程
-
-
Portal Create部分
-
-
-
-
在 CreatePortal 打断点,开始调试
-
-

-
-
-
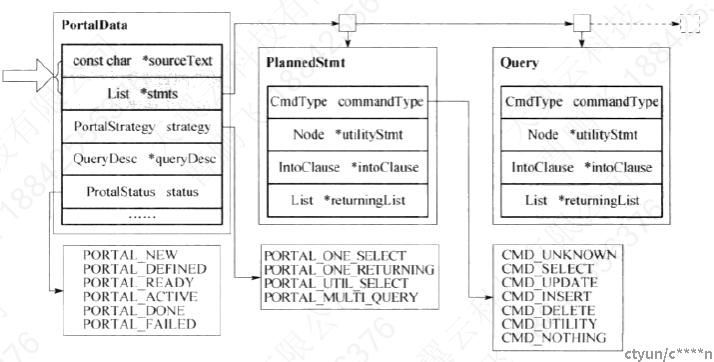
portal = CreatePortal("", true, true); 用来创建一个 Portal,然后用 Portal 作为执行器的输入数据,Portal中保存了包括查询树、计划树以及执行状态在内的所有信息,Portal结构如下图所示(图片来源《PostgreSQL数据库内核分析》)
-
-
-
-
-
CreatePortal 函数逐步执行情况,设置内存上下文、资源跟踪器等信息。
-
-
-
-
-
portal是指针形式的变量,打印的portal值
-
-

-
-
- 在CreatePortal函数后会调用PortalDefineQuery(portal, NULL, query_string, commandTag, plantrePorte_list, NULL); 函数主要是对 portal 进行字段设置工作,包括原始 SQL 语句,命令类型,查询编译输出的计划树等。
-

-
- Portal创建完成后,作为执行部分的入口,主要提供了 PortalStart、PortalRun、PortalEnd 三个对外的调用接口,下面将对这三个主要的调用接口进行跟踪。
-
PortalStart 部分
-
-
-
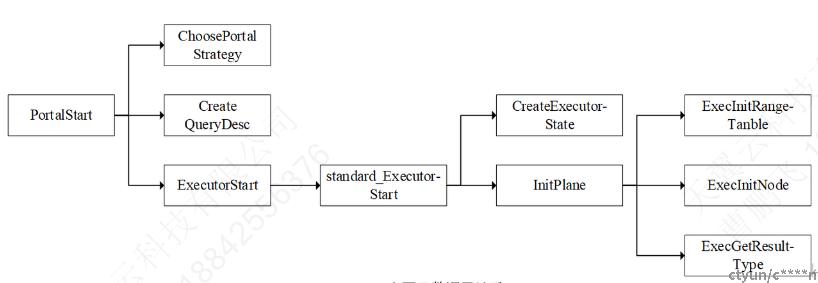
PortalStart 对定义好的 Portal 进行初始化,主要的函数调用如下图
-
-
-
-
-
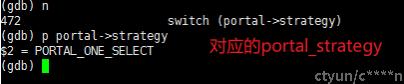
调用 ChoosePortalStrategy 函数决定执行策略,pg 主要就是根据编译器输出的原子操作链表中的原子命令类型和原子操作个数来选择执行策略。
-
-

打印执行策略值,PORTAL_ONE_SELECT 中包含一个简单的 SELECT 类型的查询计划树
-
-
-
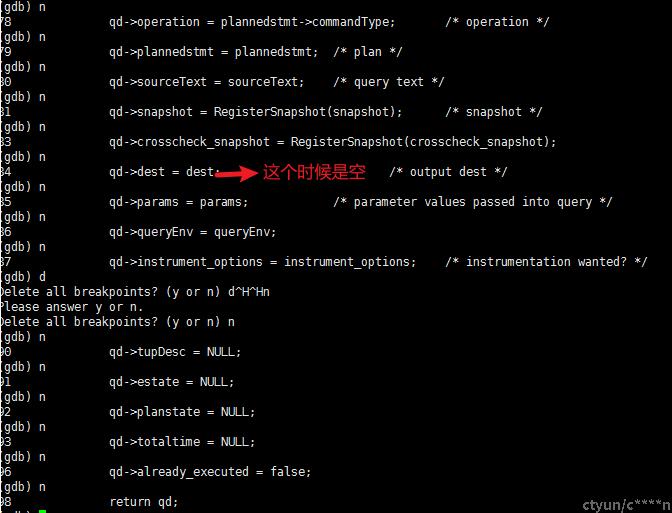
调用 queryDesc = CreateQueryDesc(linitial_node(PlannedStmt, portal->stmts), ....... 0); 创建查询描述符,存储包括查询计划树、功能语句执行计划、执行器全局状态以及计划节点执行状态等,作为 ExecutorStart 的输入来完成Executor 的初始化。
-
-
-
-
- 接着调用 ExecutorStart(queryDesc, myeflags); 主要是调用 standard_ExecutorStart(queryDesc, eflags); 函数完成 Executor 的初始化工作
-
-
-
-
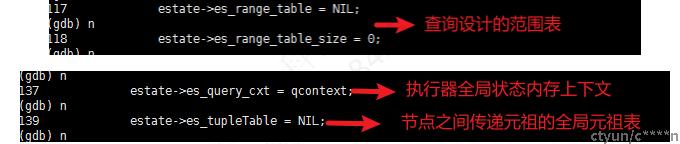
- 创建执行器全局状态,包括查询涉及的范围表、内存上下文以及节点之间传递元祖的元祖表。
-
-
-
-
-
- 执行状态字段进行赋值
-
-
-
-
-
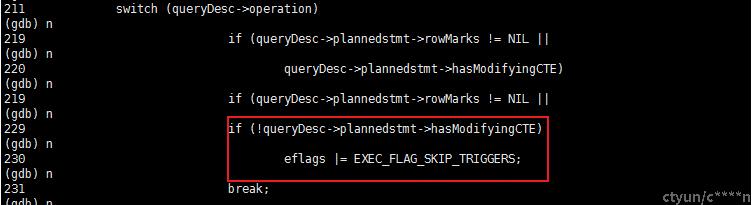
- 执行的SQL 语句是个 SELECT 操作,跳过 Trigger,提高效率
-
-
-
-
-
调用 InitPlan(queryDesc, eflags); 完成查询计划树的初始化,构造对应的 PlanState 树。执行器对于查询计划树的处理,最终都转化为对于计划树上每一个节点的处理,包括节点的初始化、处理以及清理动作。在 InitPlan 中调用 subplanstate = ExecInitNode(subplan, estate, sp_eflags); 函数进行节点的初始化
-
-
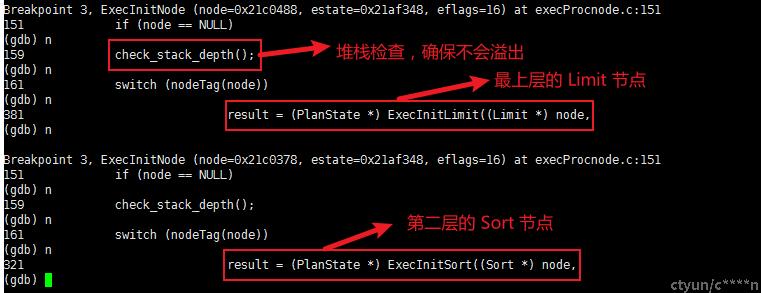
-
-
PortalRun 部分
-
-
-
-
PortalRun 主要负责完成查询计划树的执行,主要的调用函数如下图所示
-
-

-
-
-
打印出了 PortalRun(portal, ...,&qc) 的函数参数值
-
-

-
-
-
所执行的 SQL 语句是 ONE_SELECT 类型,所以在switch case 中会调用 nprocessed = PortalRunSelect(portal, true, count, dest); 进行查询计划的执行
-
-

-
-
-
执行器开始执行 ExecutorRun(queryDesc, direction, (uint64) count, portal->run_once);

-
接着调用 standard_ExecutorRun(queryDesc, direction, count, execute_once);
-
-
-

-
-
- 再调用 ExecutePlan(estate, queryDesc->planstate, queryDesc->plannedstmt->parallelModeNeeded, operation, sendTuples,count, direction, dest,execute_once);开始计划的执行
-
-
-
-
- 调用 slot = ExecProcNode(planstate); 递归对节点进行处理,递归到叶子结点,最后进行投影运算等,在向上一层方法结果元祖指针
-
-
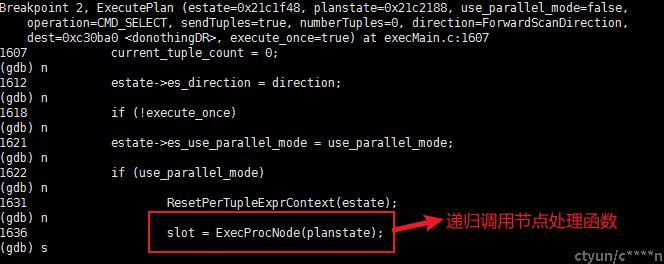
-
-
-
-
节点的处理展示
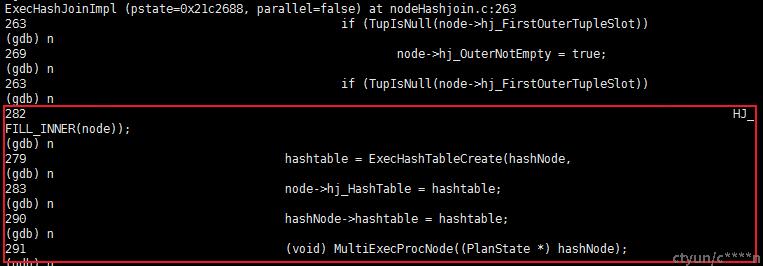 此处展示的是 hashJoin 的处理,因为会首先扫描 A 表的所有元祖进行 Hash 操作,获得块号和桶号,然后决定放入桶中或者临时表中。然后在对 B 表进行操作,获取元祖进行哈希,然后决定是否进行链接操作。
此处展示的是 hashJoin 的处理,因为会首先扫描 A 表的所有元祖进行 Hash 操作,获得块号和桶号,然后决定放入桶中或者临时表中。然后在对 B 表进行操作,获取元祖进行哈希,然后决定是否进行链接操作。
-
-
-
-
-
- 执行结果,每次获得一个结果元祖后,ExecutePlan 会根据语句操作类型选择对应的最后处理,对于Select语句会使用ExecSelect直接输出查询结果,上述的SQL语句共获得了三条元祖。
-
-
-
PortalDrop 部分
-
-
-
-
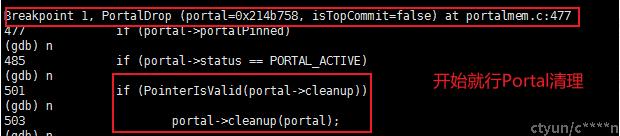
PortalDrop 主要是对 Portal 在运行中所占用的包括缓存结果的资源进行释放,主要函数调用如下图所示(图片来源《PostgreSQL数据库内核分析》)。
-
-

-
-
- PortalDrop(portal, false); 清理 Portal 的入口
-
-
-
-
调用 ExecutorEnd函数,继而调用 standard_ExecutorEnd(queryDesc); 函数

-
-
-
-
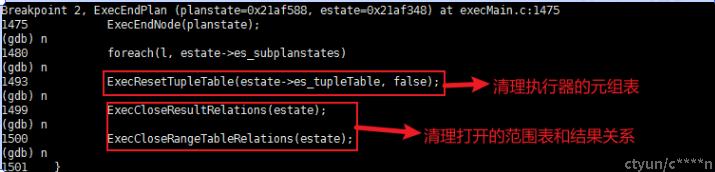
- 在 standard_ExecutorEnd 中 调用 ExecEndPlan(queryDesc->planstate, estate); 完成计划的清理
-

-
-
-
- ExecEndPlan 中 调用 ExecEndNode(planstate); 启动节点的清理工作

- ExecEndPlan 中 调用 ExecEndNode(planstate); 启动节点的清理工作
-
-
-
-
-
-
- ExecEndNode 会递归的对所有的节点进行清理工作,不同的节点对应这不同的清理函数
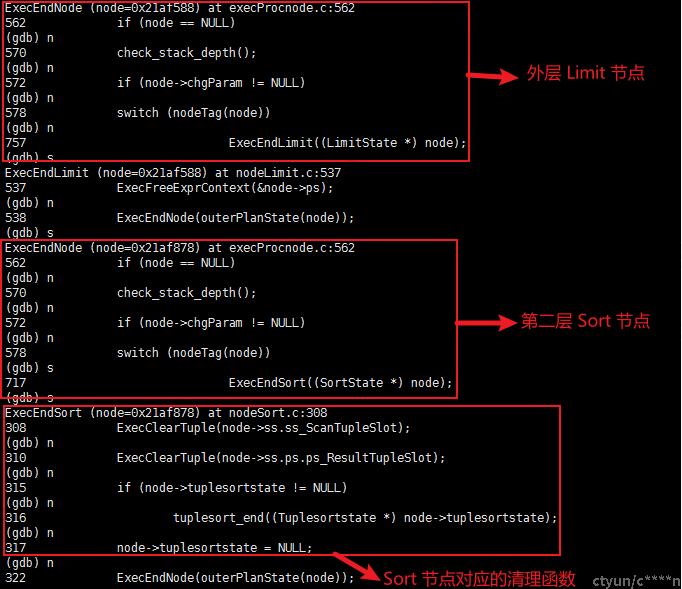
- ExecEndNode 会递归的对所有的节点进行清理工作,不同的节点对应这不同的清理函数
-
继续ExecEndPlane 的清理动作
-
-
-
-
-
-
继续 standard_ExecutorEnd 的清理动作
-
-

-
-
执行结果
-
-
-
-
查询计划
-
-
-
-
-
查询结果
-
-

总结
-
-
通过介绍了一条 SQL 语句的一般的执行过程,对于一条输入的SQL语句从生成计划树之后的流程进行跟踪分析,了解了Executor的执行流程。了解SQL对应的执行策略、执行过程中所涉及的主要变量的数据结构、Executor的执行逻辑以及SQL语句所涉及的节点以及节点操作,建立了对于执行器大致框架的了解。
-
