


一、PostgreSQL Vacuum简介
Postgresql要求周期性的清理维护,主要是出于以下几方面的考量:
-
- 恢复或重用被已更新或已删除行所占用的磁盘空间。
- 更新被PostgreSQL查询规划器使用的数据统计信息。
- 更新可见性映射,它可以加速只用索引的扫描。
- 保护老旧数据不会由于事务ID回卷或多事务ID回卷而丢失。
VACUUM会把行标记为 冻结,这表示它们是被一个在足够远的过去提交的事务所插入, 这样从 MVCC 的角度来看,效果就是该插入事务对所有当前和未来事务来说当然都 是可见的。PostgreSQL保留了一个特殊的 XID (FrozenTransactionId),这个 XID 并不遵循普通 XID 的比较规则 并且总是被认为比任何普通 XID 要老。普通 XID 使用模-232算 法来比较。这意味着对于每一个普通 XID都有 20 亿个 XID “更老”并且 有 20 亿个“更新”,另一种解释的方法是普通 XID 空间是没有端点的环。 因此,一旦一个行版本创建时被分配了一个特定的普通 XID,该行版本将成为接下 来 20 亿个事务的“过去”(与我们谈论的具体哪个普通 XID 无关)。如 果在 20 亿个事务之后该行版本仍然存在,它将突然变得好像在未来。要阻止这一切 发生,被冻结行版本会被看成其插入 XID 为FrozenTransactionId, 这样它们对所有普通事务来说都是“在过去”,而不管回卷问题。并且这样 的行版本将一直有效直到被删除,不管它有多旧。二、PostgreSQL Autovacuum介绍
2.1 AutoVacuum介绍
通过上一节的介绍,可以看到Vacuum对于PostgreSQL数据库的重要作用,用户可以选择通过执行脚本,对数据库中的表进行清理,也可以通过AutoVacuum进行周期性的清理。PostgreSQL有一个可选的但是被高度推荐的特性autovacuum,它的目的是自动执行VACUUM和ANALYZE命令。当它被启用时,自动清理会检查被大量插入、更新或删除元组的表。这些检查会利用统计信息收集功能,因此除非track_counts被设置为true,自动清理不能被使用。在默认配置下,自动清理是被启用的并且相关配置参数已被正确配置。
2.2 AutoVacuum主要参数介绍
- log_autovacuum_min_duration: 控制超过指定时间的自动清零操作是否写入日志。
- autovacuum_max_workers: 指定能同时运行的自动清理进程(除了自动清理启动器之外)的最大数量。
- autovacuum_naptime: 指定两次vacuum启动之间的时间间隔。
- autovacuum_analyze_threshold: 控制触发自动analyze的最小行数
- autovacuum_vacuum_threshold: 控制触发自动vacuum的最小行数
- autovacuum_analyze_scale_factor: 与autovacuum_analyze_threshold一起工作,用于动态计算analyze操作的阈值。
- autovacuum_vacuum_scale_factor: 与autovacuum_vacuum_threshold一起工作,用于动态计算vacuum操作的阈值。
- autovacuum_freeze_max_age: 指定一个表的pg_class.relfrozenxid字段能保持的最大年龄(事务数)。当达到此值时,将强制执行VACUUM操作以防止事务ID回绕。
- autovacuum_vacuum_cost_delay和autovacuum_vacuum_cost_limit: autovacuum_vacuum_cost_delay指定了在评估VACUUM操作的cost超过autovacuum_vacuum_cost_limit时,进程将延迟多长时间。autovacuum_vacuum_cost_limit指定了评估的cost阈值,-1表示使用全局的vacuum_cost_limit值。
2.3 AutoVacum主要函数介绍
2.3.1 启动器Launcher进程
“自动清理后台进程”实际上由多个进程组成。有一个称为 自动清理启动器的常驻后台进程, 它负责为所有数据库启动自动清理工作者进程。 启动器将把工作散布在一段时间上,它每隔 autovacuum_naptime秒尝试在每个数据库中启动一个工作者 (因此,如果安装中有N个数据库,则每 autovacuum_naptime/N秒将启动一个新的工作者)。 在同一时间只允许最多autovacuum_max_workers个工作者进程运行。如果有超过autovacuum_max_workers 个数据库需要被处理,下一个数据库将在第一个工作者结束后马上被处理。 每一个工作者进程将检查其数据库中的每一个表并且在需要时执行 VACUUM和/或ANALYZE。 可以设置log_autovacuum_min_duration来监控自动清理工作者的活动。
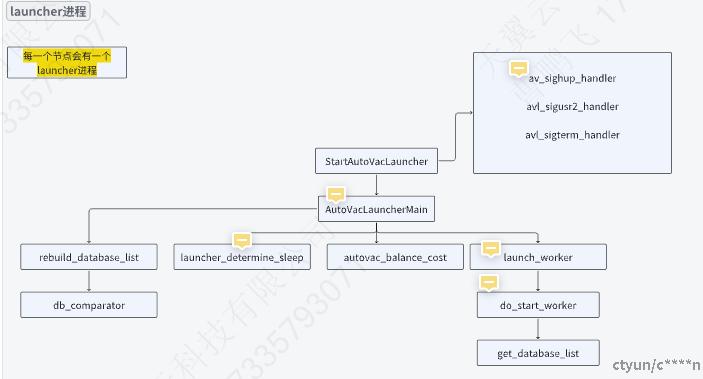
如上述图中所显示,autovacuum worker进程主要是通过启动器Launcher进程进行启动,更具体的是通过do_start_worker进程进行启动。而启动器进程则是在Postgres启动的后台辅助进程,在收到启动autovacuum worker进程的信号后,开始启动AutoVacuum Worker进程的流程。
2.3.2 AutoVacuum Worker进程
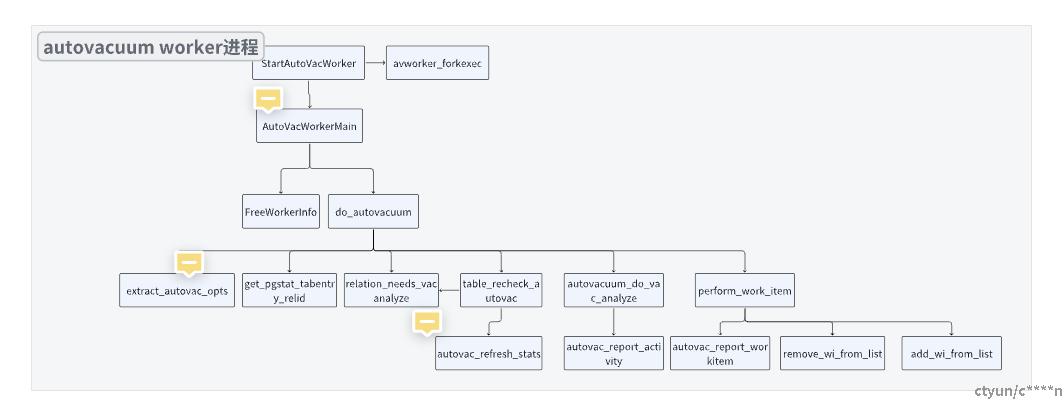
从上述图中可以看出,Launcher启动AutoVacuum Worker进程之后,主要的工作是在AuotVacWorkerMain函数来完成AutoVacuum操作。其中包括执行清理Worker进程的FreeWorkerInfo,该函数将工作结束或者启动超时的worker进程资源进行回收,并增加一个可用的”启动槽位“,用于启动下一个worker进程。do_autovacuum进程用于完成。
2.3.3 do_autovacuum函数
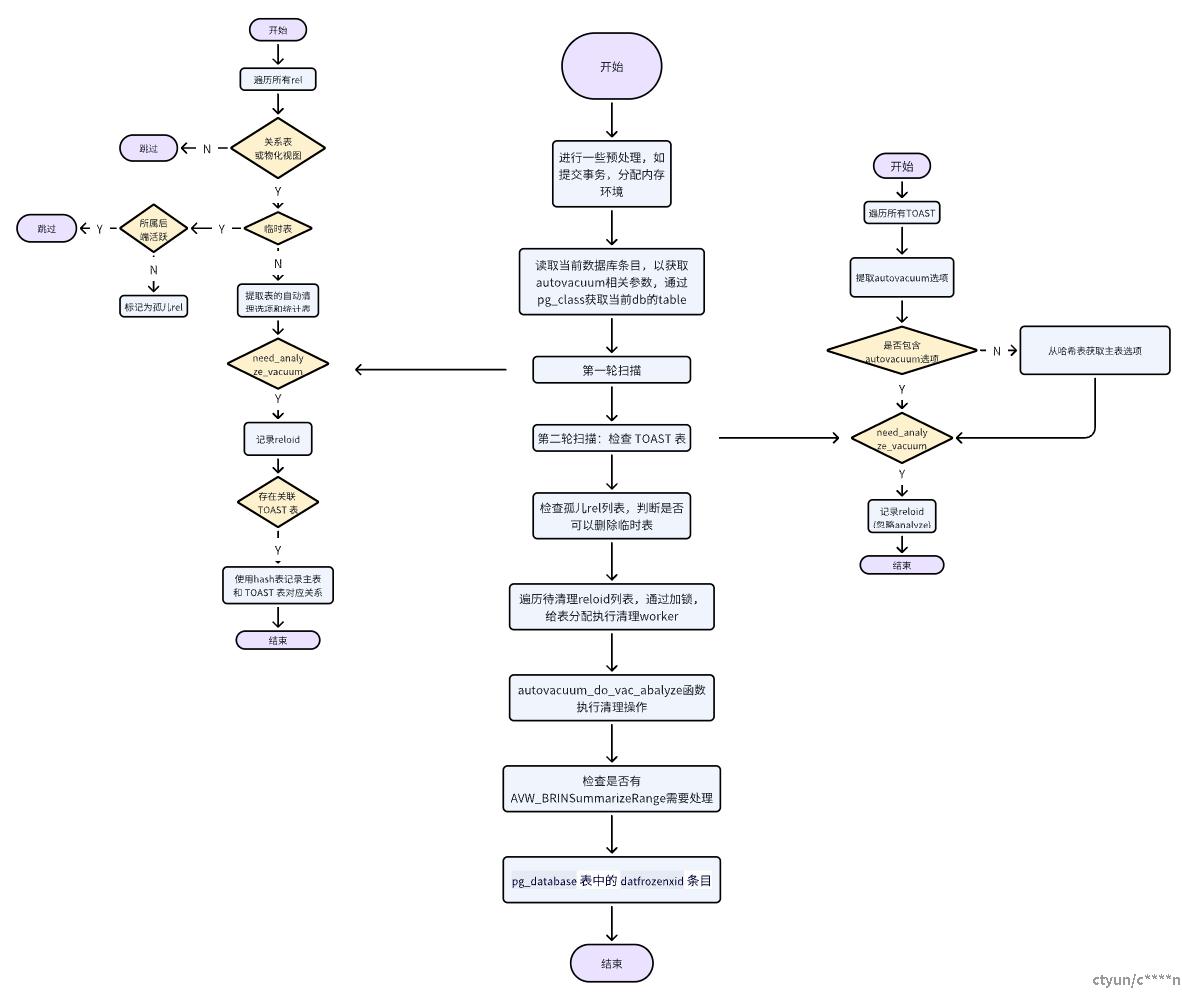
上图展示了autovacuum主要的函数do_vacuum的主要流程,首先是一些预处理,如提交事务、分配内存环境等。之后会读取当前数据库的条目获取autovacuum的相关参数、获取当前数据库的表。之后会进行第一轮扫描,首先是遍历所有rel,跳过所有的非关系表和非物化视图。针对于临时表,会判断对应的所属后端时候活跃。之后会对关系表进行判断,根据设定的相关vacuum参数来判断该表是否需要清理,如果需要清理,则将该表的oid加入到待需要清理列表中。之后会进行第二轮扫描,主要是检查TOAST表,判断TOAST表是否需要清理。之后针对之前的临时表来判断是否需要删除临时表。接下来就是对于之前生成的待清理关系表,使用autovacuum_do_vac_analyze函数来完成最终的vacuum和analyze操作,接下来调用的函数既为vacuum操作所使用的函数。
2.2.4 判断是否需要vacuum
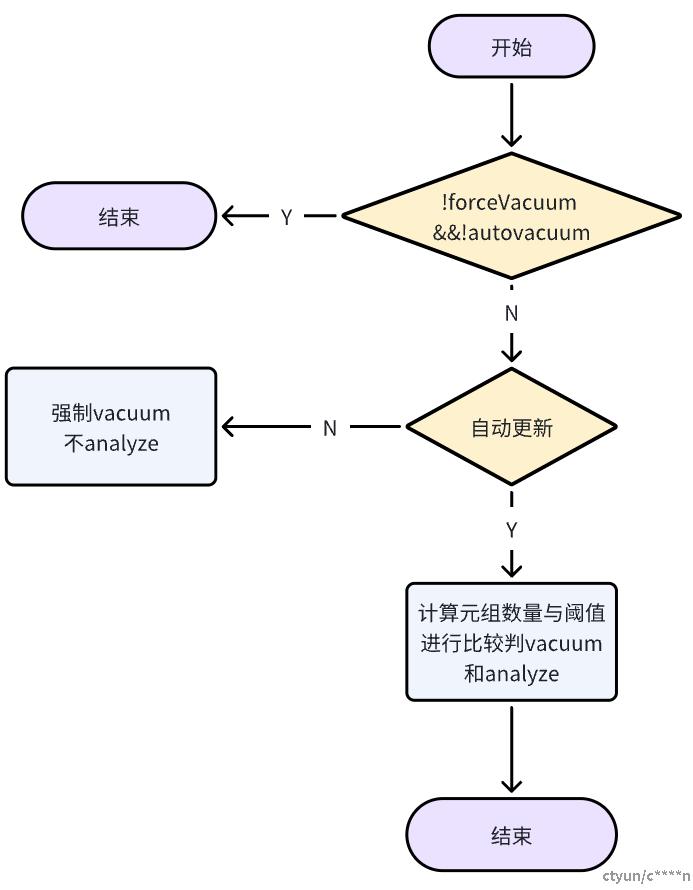
上图中的重要的地方就是判断该关系表是否需要清理,主要的计算方式如下:
/* Force vacuum if table is at risk of wraparound */
// xidForceLimit = 最近的事务id-允许的最大的事务id
// 超过freeze_max_age将被‘冰冻’,dbx中默认值是2亿
xidForceLimit = recentXid - freeze_max_age;
// 如果该值小于第一次允许的正常值(通常为3)表示可能发生了事务环绕
if (xidForceLimit < FirstNormalTransactionId)
xidForceLimit -= FirstNormalTransactionId;
// 如果表的relfrozenxid是一个正常的事务ID,并且它早于我们计算出的回绕限制值,
// 则需要强制进行清理以防止事务ID回绕。
force_vacuum = (TransactionIdIsNormal(classForm->relfrozenxid) &&
TransactionIdPrecedes(classForm->relfrozenxid,
xidForceLimit));
// 同样的方式计算多事务
if (!force_vacuum)
{
multiForceLimit = recentMulti - multixact_freeze_max_age;
if (multiForceLimit < FirstMultiXactId)
multiForceLimit -= FirstMultiXactId;
force_vacuum = MultiXactIdIsValid(classForm->relminmxid) &&
MultiXactIdPrecedes(classForm->relminmxid, multiForceLimit);
}
*wraparound = force_vacuum;
