


前提概念
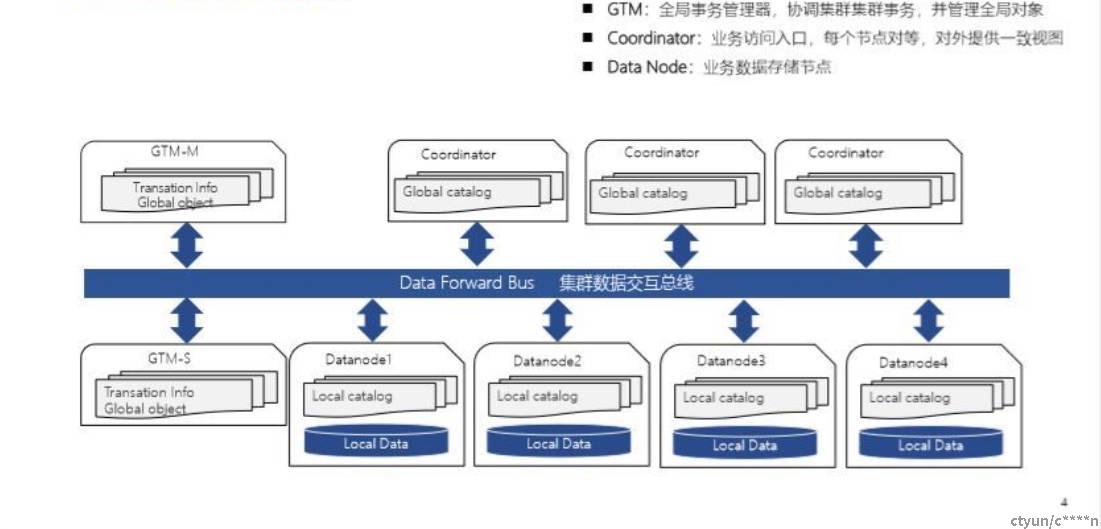
GTM、CN、DN概念
-
Coordinator:协调节点(简称CN),对外提供接口,负责数据的分发和查询规划。多个节点位置对等,每个节点都提供相同的数据库视图;在功能上CN上只存储系统的全局元数据,并不存储实际的业务数据
-
Datanode:用于处理存储本节点相关的元数据,每个节点还存储业务数据的分片,简称DN。在功能上,DN节点负责完成执行协调节点分发的执行请求。
-
GTM:全局事务管理器(Global transactionmanager.),主要是做分布式事务,负责管理集群事务信息,同时管理集群的全局对象,比如序列等,除此之外GTM上不提供其他的功能。
shard(普通表、分区表、冷热分区表)、复制表
shard普通表
建表时指定分布列与存储组,如果没有指定分布列则使用主键做分布列,否则默认第一个字段,使用distribute by 使用的是哈希分布,具有相同哈希值的数据会分布在同一节点。分布方式还有DISTRIBUTED RANDOMLY以及DISTRIBUTED REPLICATED。
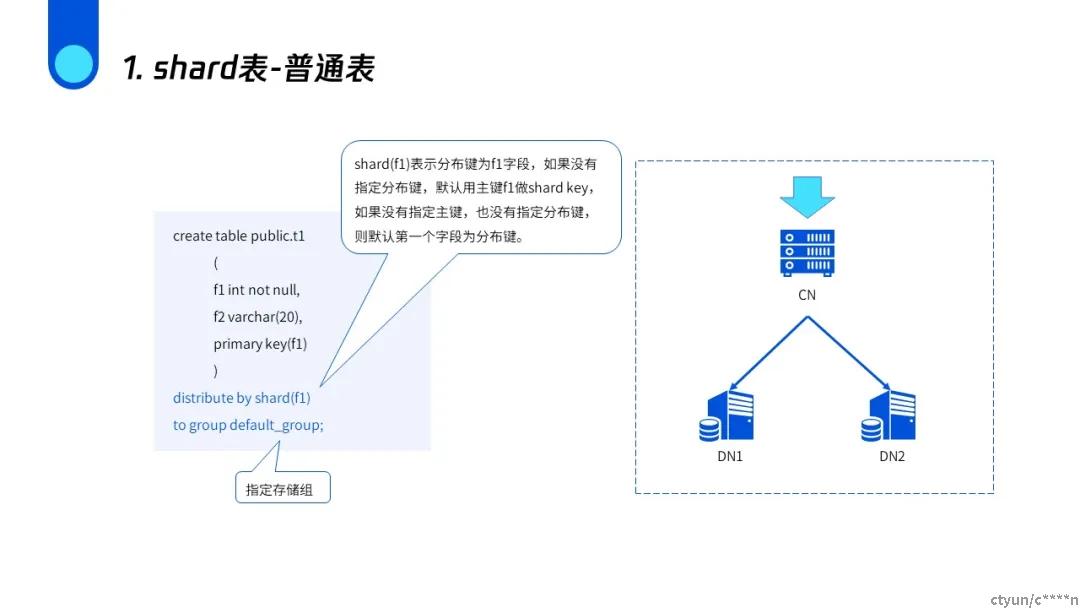
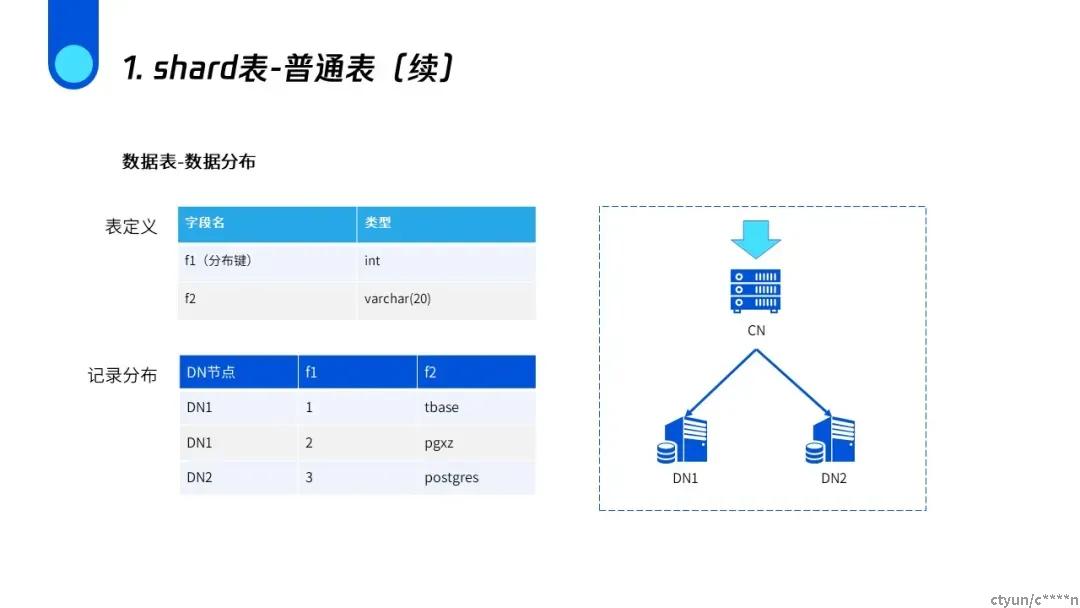
因为具有相同哈希值的数据是存储在同一个节点上的,所以在查询f1=3的数据时,只会在DN2上进行查询。
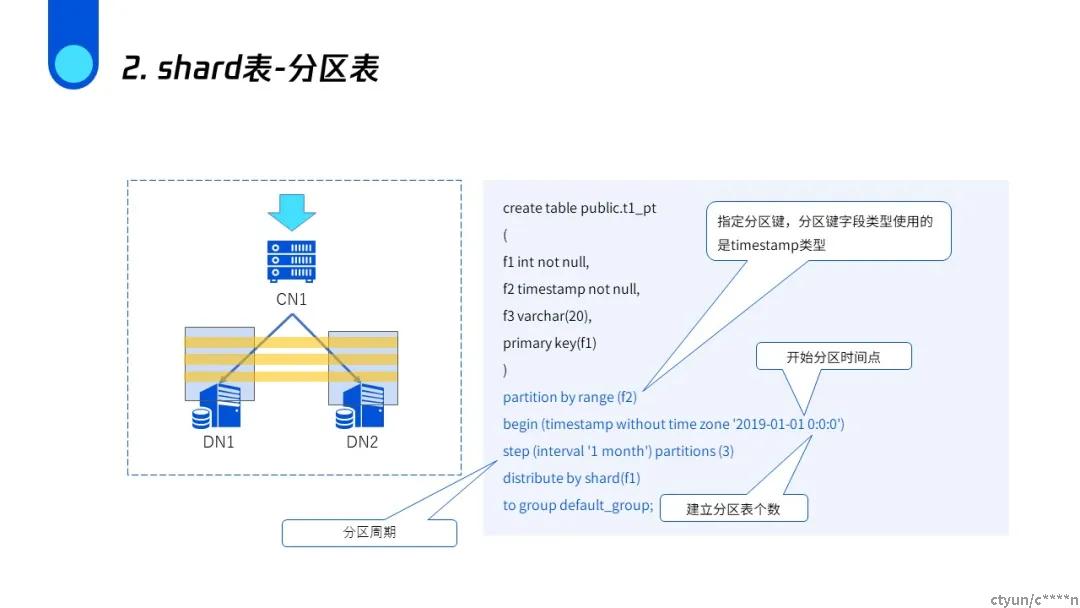
shard分区表
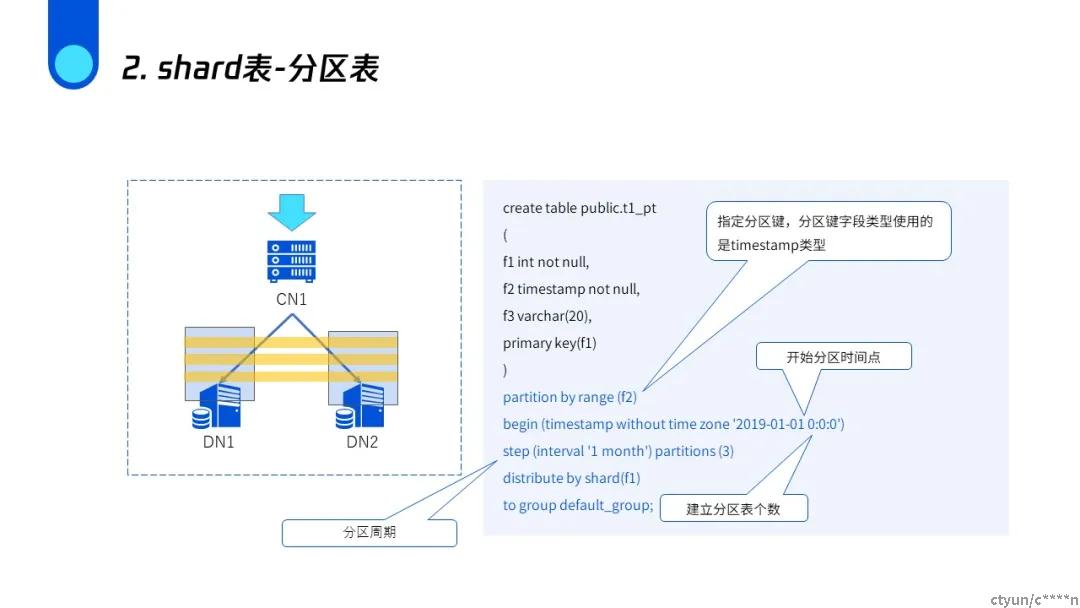
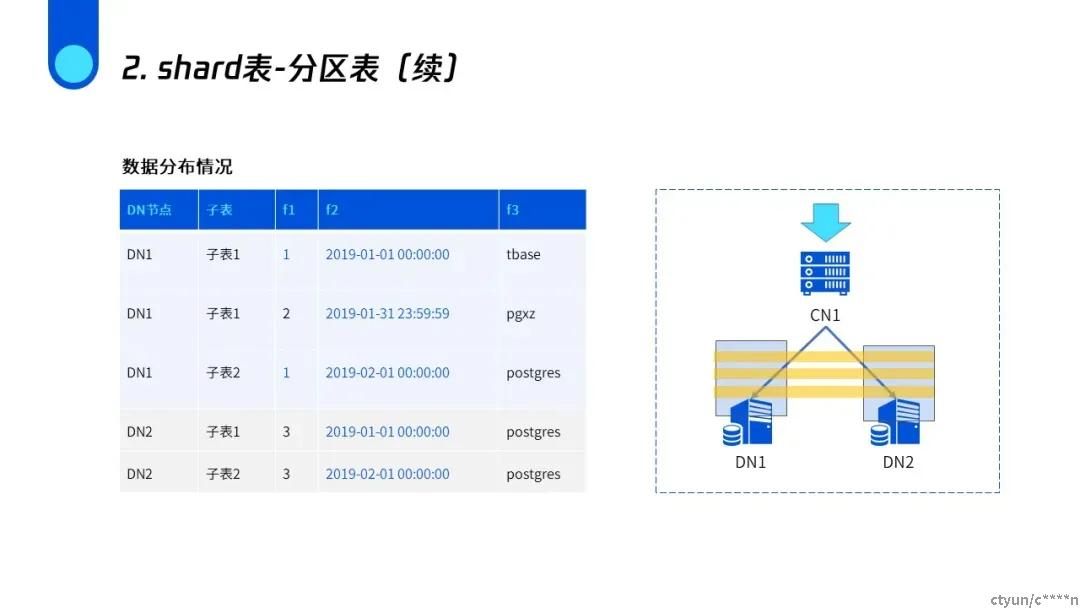
可以看到拥有同样字段值的内容根据时间已经分成了不同的子表,但是都存在DN1上。分区表的优点是如果你的查询带有时间的话,它很好的利用数据库分区剪枝的特性,它只查询其中的某一个分区,这样就减少了查询的数据量,提升了性能。
shard冷热分区表
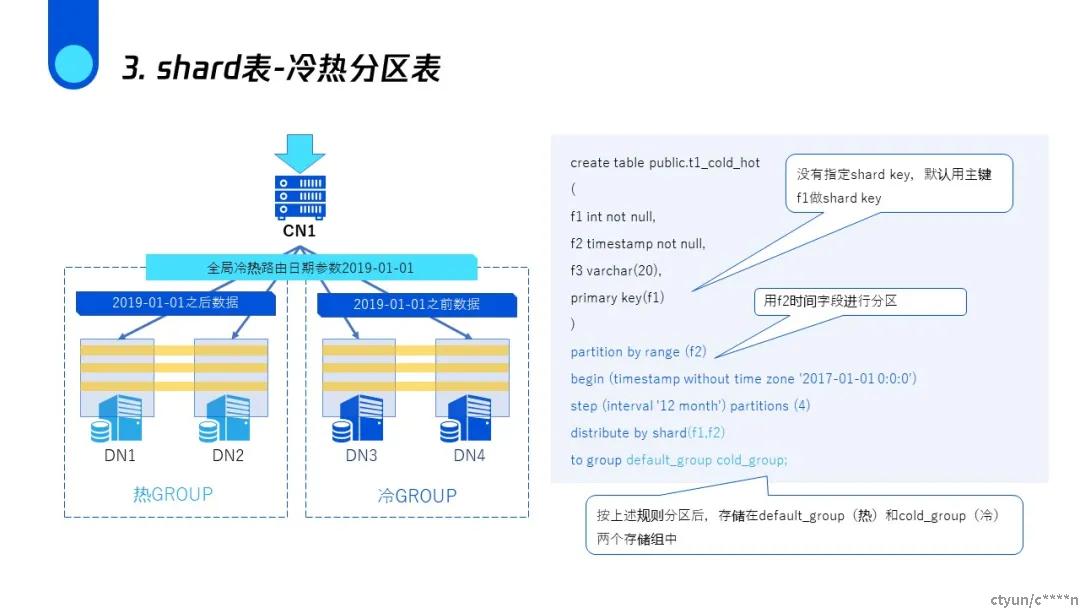
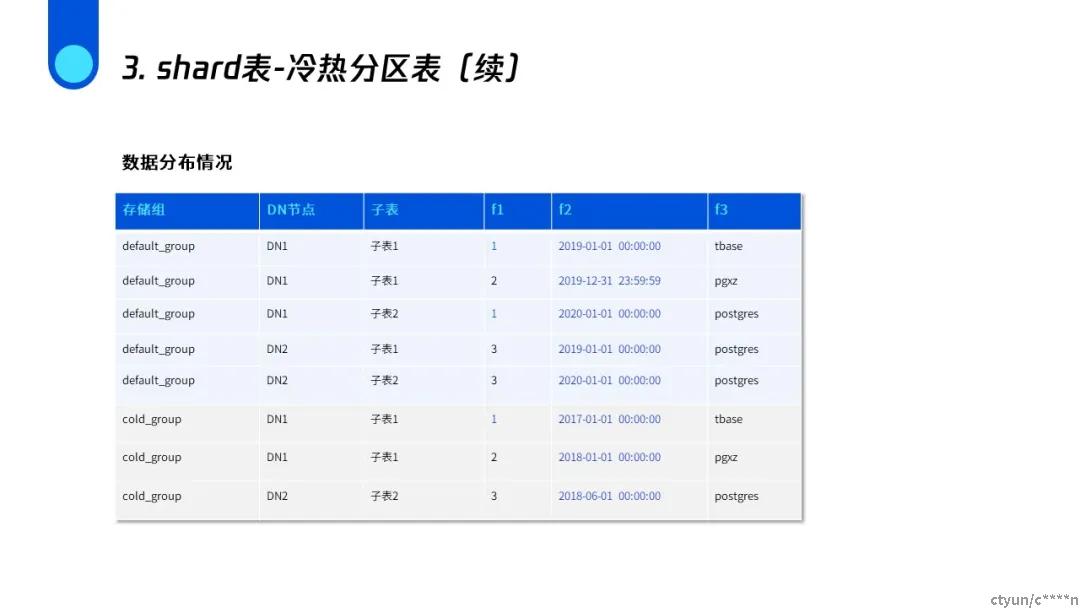
进行冷热分区以后可以将热点数据存储在较好的存储设备,将更多的冷数据存储在相对廉价的设备从而节约成本,做到性能与成本的兼顾。
复制表
复制表是指所有节点均拥有全量的数据,主要的使用场景是更新较少、经常参与join的小表,如果要是频繁的进行更新,就不适合用复制表
分布式查询数据重分布策略
分布式查询
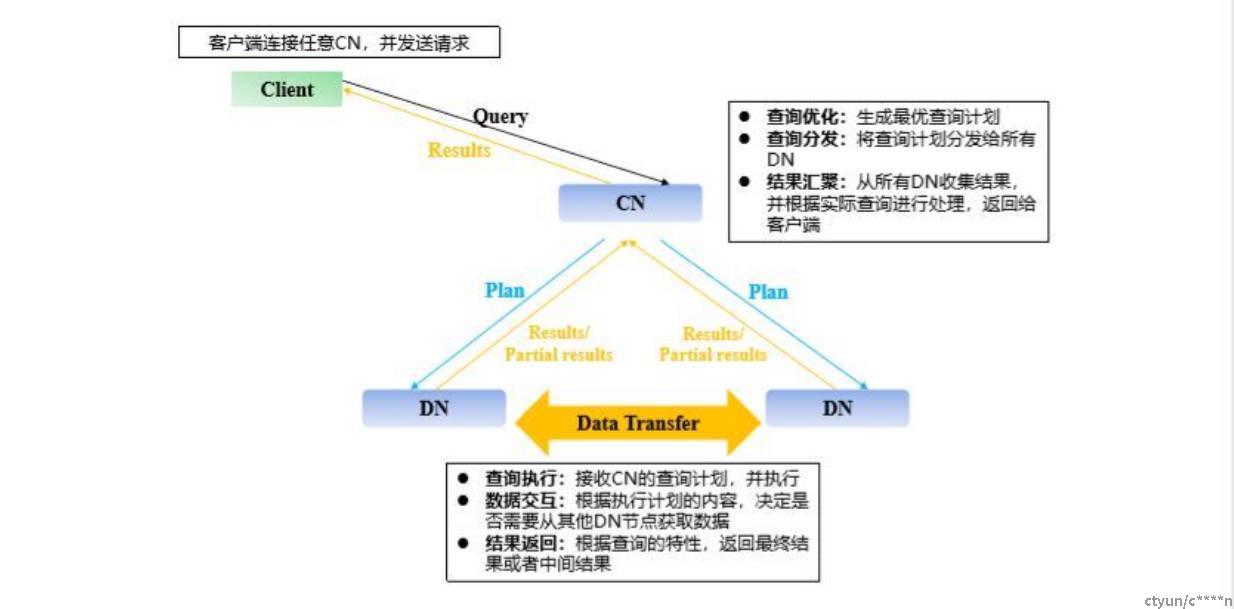
首先客户端连接到协调节点CN,CN生成最优的查询计划,将查询计划分发给所有的DN,DN接收CN的查询计划并执行,DN会根据执行计划的内容来决定是否会去其他节点获取数据。查询完成后,返回最终结果或者中间结果,CN收集所有DN结果,在根据实际查询进行处理,返回给客户端。
分布式join
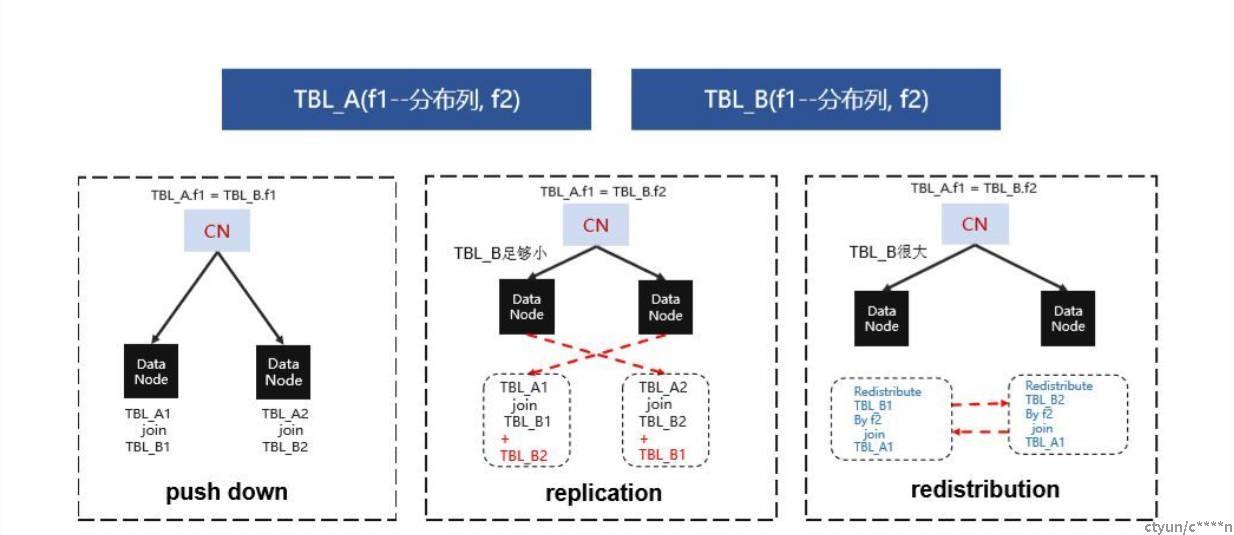
非重分布场景
-
当参与join的列都是分布列时,会进行Remote Fast Query Execution,将Query下发给对应的dn节点,节点join完了之后,在CN上做汇总即可。
-
explain select t.no, t.name, tc.cno from teach_course as tc, teacher as t where tc.tno=t.no; QUERY PLAN --------------------------------------------------------------------------------- Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0) Node/s: dn01, dn02 -> Hash Join (cost=161.38..1349.65 rows=8672 width=12) Hash Cond: (tc.tno = t.no) -> Seq Scan on teach_course tc (cost=0.00..915.13 rows=49713 width=8) -> Hash (cost=98.39..98.39 rows=5039 width=8) -> Seq Scan on teacher t (cost=0.00..98.39 rows=5039 width=8) (7 rows)
当参与join的有一个表是足够小的时候
当使用一个足够小的表与一个大表做join时,只有与大表的非分布式key做join时会是复制小表,否则的会进行query的下发或者重分布小表。
-
-
大表的分布式key和小表的非分布式key做join时会是对小表进行重分布
-
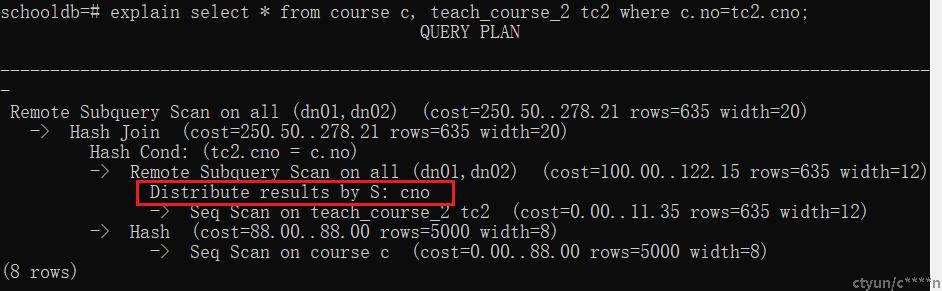
-
如果是大表的非分布式key和小表的分布式key做join会对小表进行复制,这样每个在每个节点上都会使用全量的小表与大表在每个节点上的分片进行join,然后在汇总给CN
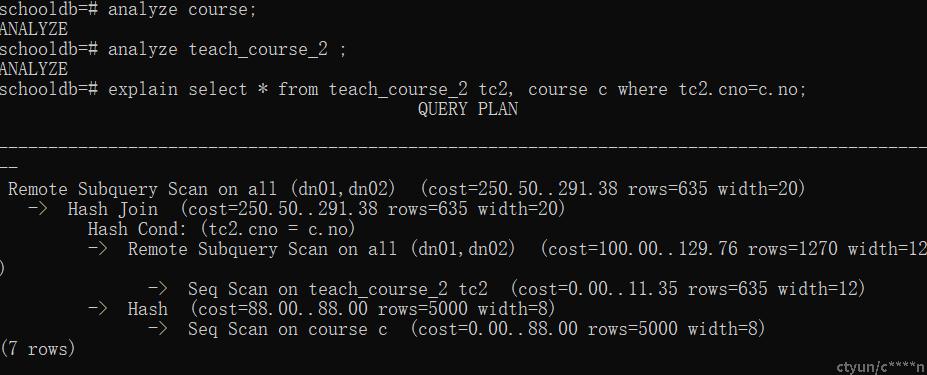
一张大表和一张小表做join的时候所有情况(具体在补充)
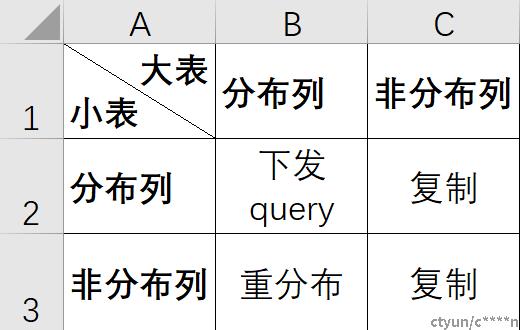
数据重分布的概念
a表分布key join b表非分布key在每个dn上面进行,会分别去其他dn获取b表的数据。每个dn会按照b表的join key进行计算,然后把b表数据发送到对应dn节点上面。(相当于把B表以join key为分布列,让B表的数据在dn节点上进行重新分布),这种场景涉及到了节点之间的通信,开销较高。
重分布场景
-
重分布是发生在数据节点之间需要进行数据交换的时候,当两个非复制表进行join的时候,分布列key与非分布列key做join的时候
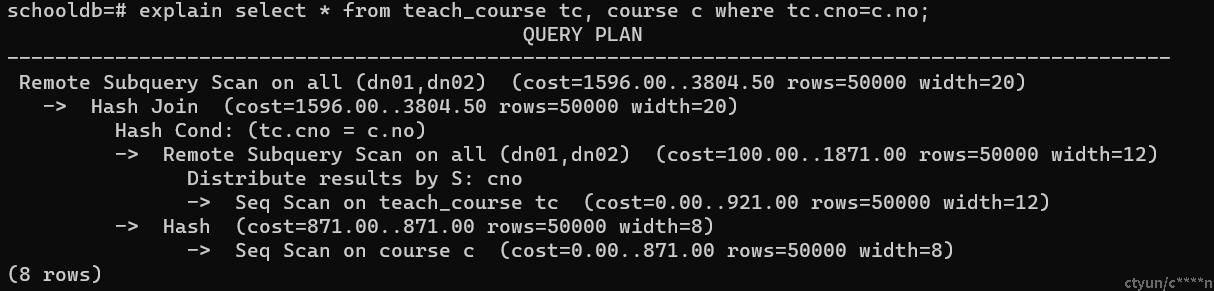
数据重分布实现
重分布执行流程
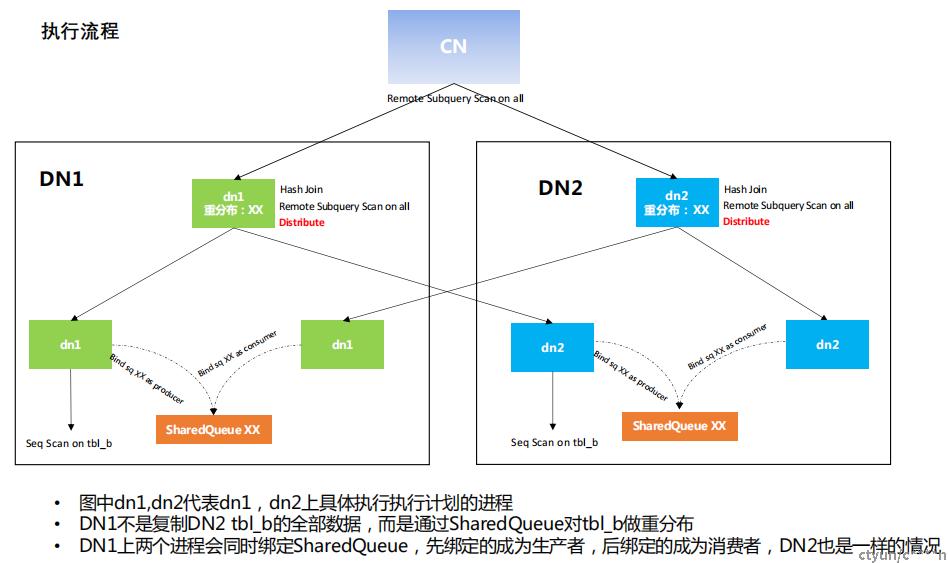
当进行重分布的时候,对TBL_B的非分布列在做hash,将每个dn节点上非分布key做join的值发送到所有的节点上,这样的话每个DN上TAB_B分片的数据完整,而用来实现数据重分布的主要数据结构是SharedQueue。
是一个生产者多消费者的动向队列,在进行重分布时,每个dn节点上都会有一个shardqueue,然后每个节点上的进程去绑定节点上的shardqueue,第一个绑定的会成为生产者,生产者绑定以后,会创建发送线程,然后为所有的消费者分别创建缓冲区DataPumpBuf。然后生产者把数据放到数据缓冲区,数据缓冲区中的数据量超过一定阈值(可以通过参数设置)时,发送线程会将数据发送,完成数据的重分布。
