引言
科研助手【科研版】提供并行计算功能模块,您可以基于该能力模块运行分布式作业。我们提供多种运行引擎的支持,您可以根据自己的需要使用不同的训练引擎。同时,我们也提供多个区域不同种类的算力,您可以根据需要按需选购。
场景描述
本文将通过使用 PyTorch框架训练手写数字识别 MNIST 模型来讲述如何在科研助手并行计算模块中训练模型。
手写数字MNIST 数据集是一个经典的手写数字图像数据集,广泛用于机器学习和深度学习领域的模型训练与评估。它包含60,000 张训练图像和 10,000 张测试图像,每张图像为 28×28 的灰度图,涵盖手写数字 0 到 9。MNIST数据集因其简单性和代表性,成为算法验证和教学的经典工具,支持多种机器学习方法和深度学习模型的开发与测试。
本场景的整体流程如下:

准备工作
准备工作包括如下几步:
- 准备数据:准备训练代码、训练数据、训练环境
- 创建科研文件:科研文件是科研助手提供的文件管理服务,并行计算需要依赖科研文件将数据挂载到训练任务中
- 上传数据:将准备好的数据上传到科研文件实例
数据准备
数据包括训练代码、训练数据和训练环境。
1、训练代码
本示例的训练代码包括两部分,如下所述:
(1)启动脚本
本示例提供一个启动脚本start.sh,可以简化创建任务填写的启动命令内容。内容如下:
sudo /opt/conda/bin/python3 /storage/mnist/bc_mnist.py
您可以按照实际情况调整启动脚本的内容。
(2)模型训练代码
本示例的训练代码包括训练和验证两部分内容,参考官方提供的示例代码进行改写。bc_mnist.py 内容如下:
from __future__ import print_function
import argparse
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.onnx
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=5, metavar='N',
help='number of epochs to train (default: 5)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
print("use_cuda: {}".format(use_cuda))
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('/storage/mnist/data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('/storage/mnist/data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
print("Dataloader done")
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
print("modeldone")
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
print("train done")
if args.save_model:
out_dir = "/storage/mnist/model/m/1/"
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
# 保存模型
model_path = out_dir + "mnist_model.pth"
torch.save(model.state_dict(), model_path)
print("模型已保存到 {}".format(model_path))
# 加载模型
print("加载模型...")
model = Net() # 创建新的模型实例
model.load_state_dict(torch.load(model_path)) # 加载保存的权重
model.eval() # 设置为评估模式
# 测试模型
print("开始测试...")
with torch.no_grad():
for images, labels in test_loader:
# 获取第一批数据中的第一张图片和标签
image = images[0].unsqueeze(0) # 添加一个批次维度
true_label = labels[0].item()
# 进行预测
output = model(image)
_, predicted_label = torch.max(output, 1)
predicted_label = predicted_label.item()
# 打印结果
print(f"真实标签: {true_label}")
print(f"预测标签: {predicted_label}")
break # 只处理一张图片
if __name__ == '__main__':
main()
您可以根据实际情况调整模型训练代码。
2、数据准备
本示例使用的是官方提供的MNIST 数据集。
【注意】训练代码中有配置自动下载代码的选项,如果没有提前下载数据,也支持自动下载。您可以按照实际情况上传模型训练需要的数据。
创建科研文件
【科研文件】是科研助手提供的文件管理服务模块,您可以通过【科研文件】来管理自己的数据。并行计算需要依赖【科研文件】提供训练所需数据,因此需要提前创建科研文件。
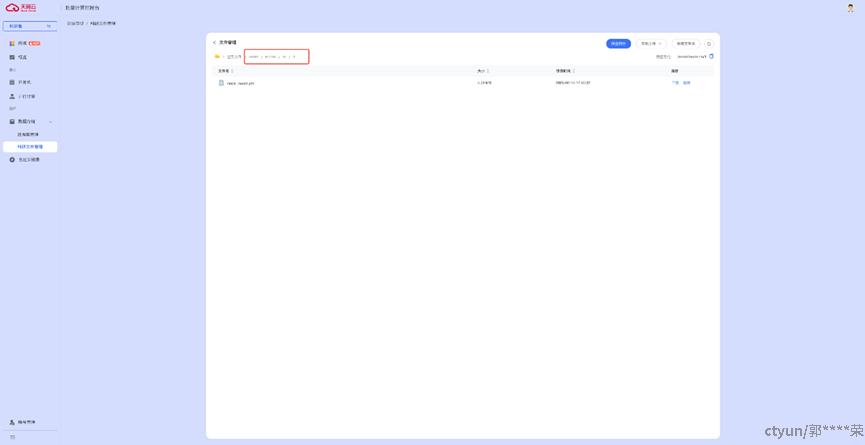
进入科研助手,选择【数据存储】>【科研文件管理】,点击【创建科研文件】按钮
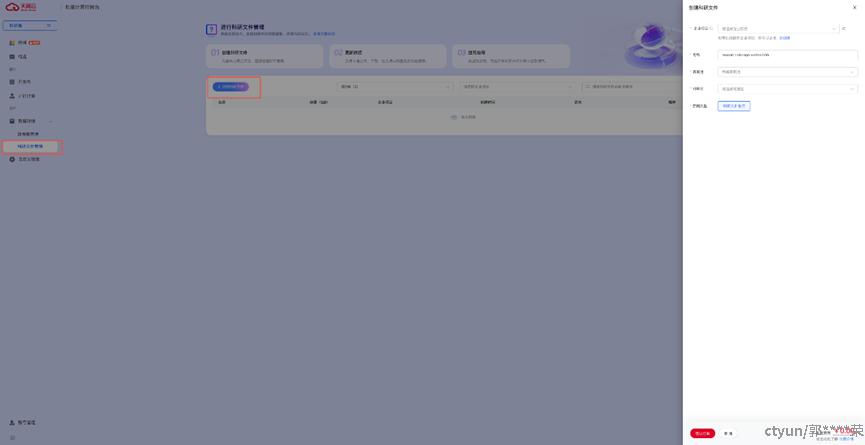
科研文件目前仅支持【厦门4】可用区,您需要注意选择对应的资源池【huanan001-xxx】。科研文件默认最小容量为10G,您可以按需调整所需容量。
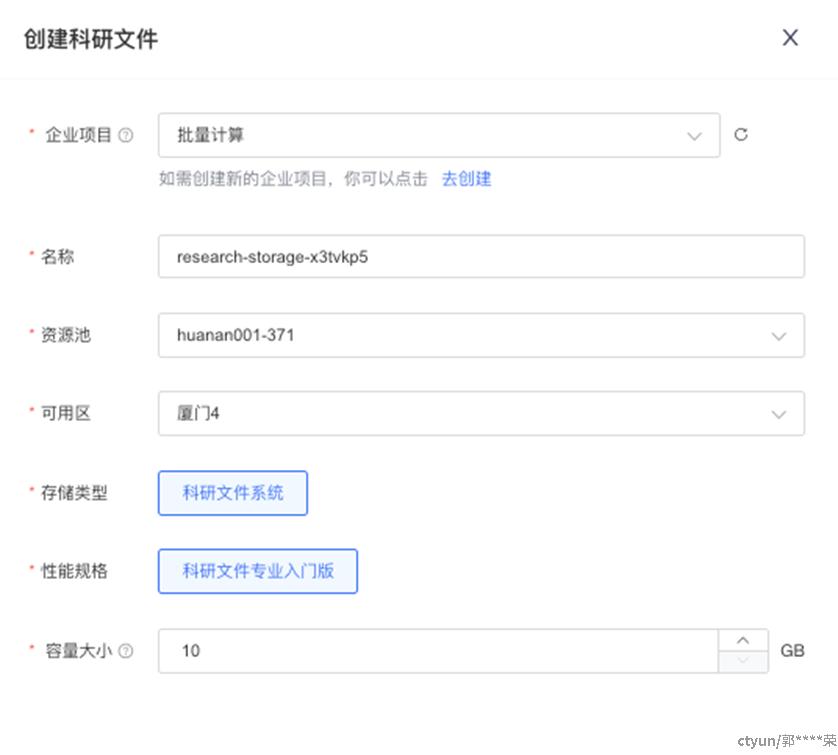
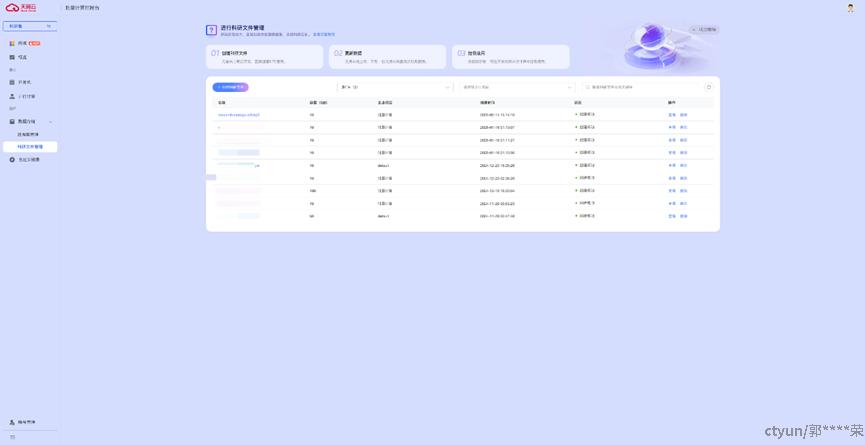
配置后,点击【确认订单】,等待科研文件状态变为【创建成功】
上传数据
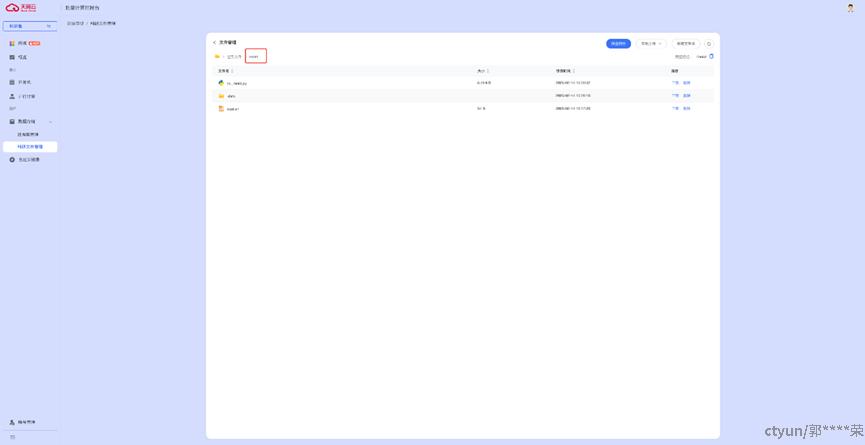
选择刚刚创建好的科研文件,点击【查看】,进入文件管理界面。
新建一个目录,本示例命名为mnist。进入目录上传准备好的训练脚本、训练数据。
【注意】
- 数据上传过程中,请保持网络畅通
- 数据上传过程中,不要刷新页面,否则会导致上传文件丢失
MNIST 手写识别模型训练
准备工作做完后,进入【并行计算】页面,点击【创建计算任务】按钮,进入任务配置页面。
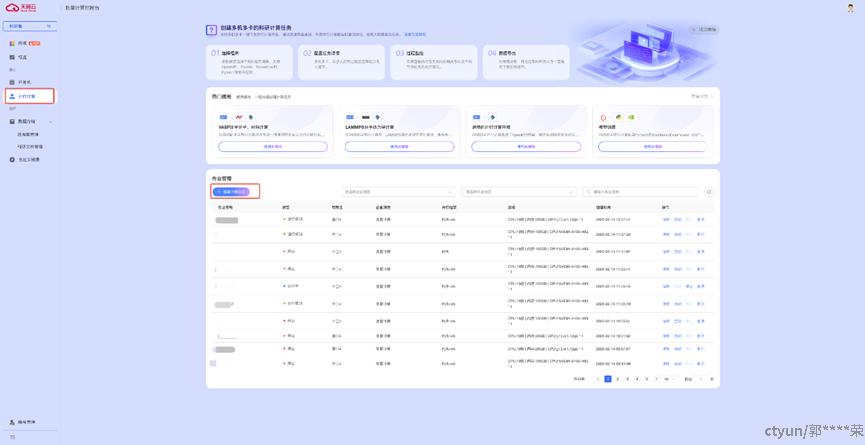
【注意】并行计算内置了一些可以直接使用的模板,您可以按需使用。
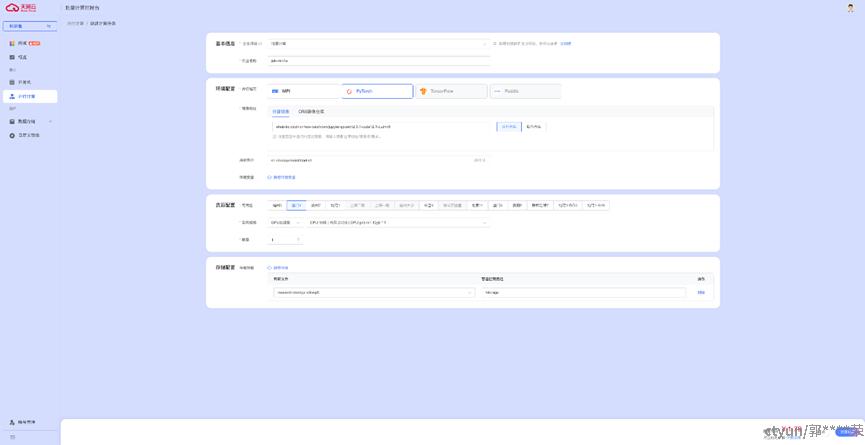
在任务配置页面,本示例的配置如下:
- 选择 PyTorch 训练框架
- 镜像地址:本示例使用科研助手公共的 PyTorch 镜像(该镜像需要使用本示例启动脚本对应的 python 命令),地址为:ehub-bc.ctcdn.cn/esx-batchcom/jupyter-pytorch2.3.1-cuda12.1-cudnn8
- 启动执行命令:sh /storage/mnist/start.sh
- 可用区:需要与科研文件在同一个可用区:厦门4
- 实例规格:可以按照实际需求选择
- 容器挂载路径,需要与训练脚本中使用的路径相对应:/storage
配置后,点【立即创建】
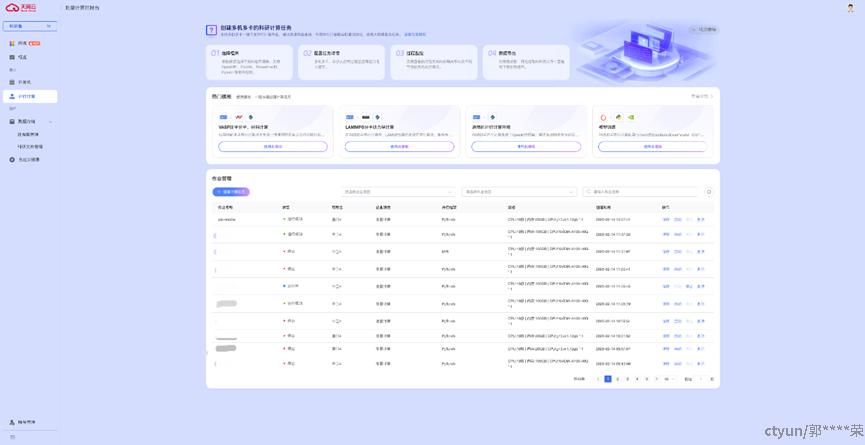
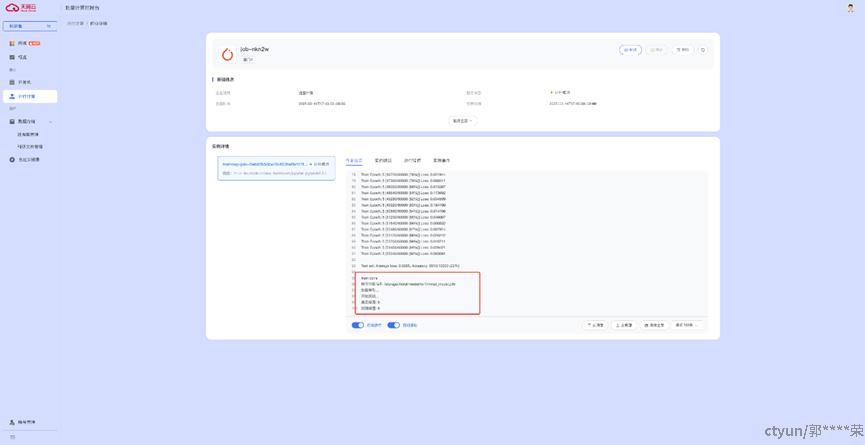
可以点击右侧的【详情】按钮查看任务运行情况。
并行计算提供多种能力来跟踪任务运行情况,包括:
- 作业日志:可以查看任务运行过程中产生的训练日志
- 实例终端:可以登录任务运行容器查看训练过程中产生的中间数据
- 运行监控:可以查看任务运行过程的资源占用情况
- 实例事件:可以查看任务运行过程中所产生的事件列表
作业日志如下:
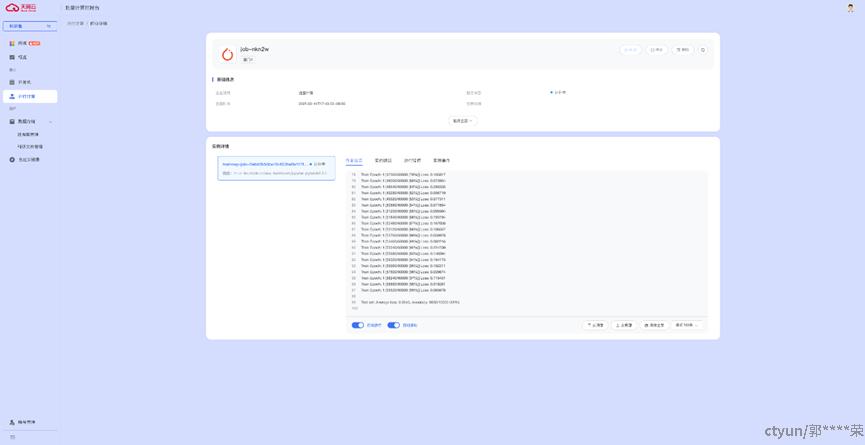
实例终端如下:
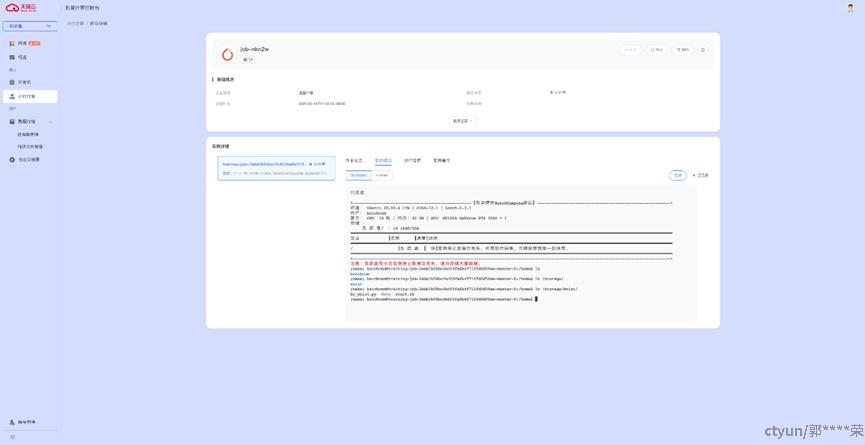
运行监控如下:
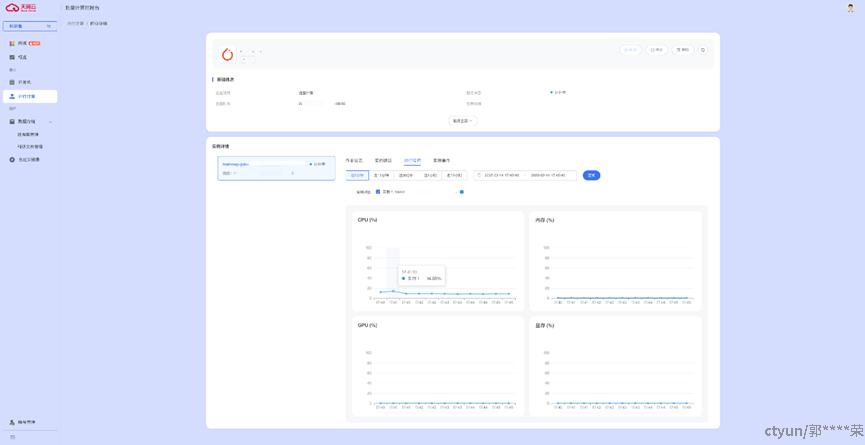
实例事件如下:
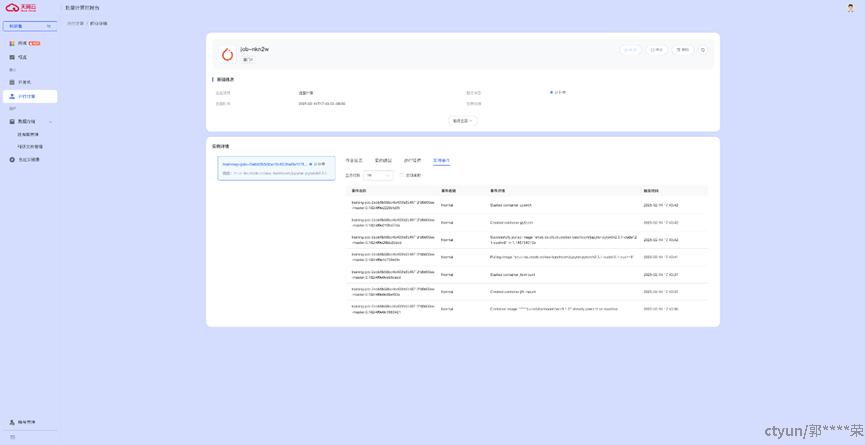
最终运行效果,模型成功训练,将模型保存到科研文件。通过保存的模型文件,能够正确识别手写识别数字。效果如下:
保存到科研文件的模型文件如下: